python操作excel文件,简单数据整合
小妹丢来3张表,要求按格式整理成一张新excel表;3张表数据杂乱不是重点,重点是工期只有半天,说多了都是泪……
数据杂乱的话,整理好数据结构,每张表去遍历一遍,然后存入自建的数据库,再从数据库里导出需要的表也是可以实现的;既然工期紧张,这些就没时间去深入研究了,直接把原来3张表人工处理一下,确保相同的行与列,直接用行列定位的方式做简单的数据整合吧。
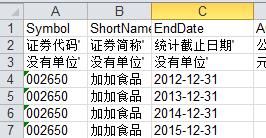

每张表前三行都是表头,前三列都是都是相同格式;每个企业有4行数据,经过手工处理每张表企业根据代码排序且相同,数据总量288条,最终需要整合成下面格式:
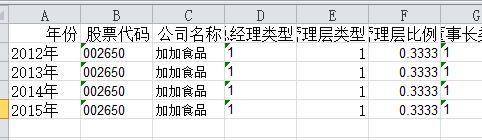
从3个表里取出相应的数据,每个企业分类并按照时间顺序排序,操作excel前记得先装好相应的库:
import xlrd
import xlwt根据需求,要整合的数据创建一个类:
class company(object):
# 构造函数
def __init__(self):
self.time = ''
self.code = ''
self.name = ''
self.D = '' # 总经理类型
self.E = '' # 管理层类型
self.F = '' # 管理层比例
self.G = '' # 董事长类型
self.H = '' # 董事会类型
self.I = '' # 董事会比例
self.J = '' # CEO及董事长类型
self.K = '' # 公司规模
self.L = '' # 财务杠杆
self.M = '' # 资产净利润率
self.N = '' # 资本密集度
self.O = '' # 托宾Q
self.P = '' # 股利支付率
self.Q = '' # 行业读取3张excel:
f_1 = xlrd.open_workbook(r'C:\Users\ysc\Desktop\1.xls')
f_2 = xlrd.open_workbook(r'C:\Users\ysc\Desktop\2.xlsx')
f_3 = xlrd.open_workbook(r'C:\Users\ysc\Desktop\3.xls')
# print(f_1.sheet_names()) # 获取所有sheet
f_1Sheet1 = f_1.sheet_by_index(0)
f_2Sheet1 = f_2.sheet_by_index(0)
f_3Sheet1 = f_3.sheet_by_index(0)
# rows_1 = f_1Sheet1.row_values(0) # 获取第1行内容
# cols_1 = Sheet1.col_values(0) # 获取第1列内容由于每个企业有4行数据,且最终要按照时间排序,写个分段读取函数:
# 读excel
def read_excel(start, end):
code = ''
time = []
for i in range(start, end):
if i == 291:
time = selectionSort(time)
find_data(code, time, start, i)
for x in data:
print(x)
write_excel(data)
break
else:
rows = f_1Sheet1.row_values(i) # 获取行内容
if code == '':
code = rows[0]
print(time)
print(code)
if code == rows[0]:
time.append(rows[2])
print(time)
print(code)
if code != rows[0]:
time = selectionSort(time)
start_i = start
end_i = i
find_data(code, time, start_i, end_i)
break比如说先读取第一个企业的数据read_excel(3, 8)表格第4行到第7行,然后取出时间推入数组排序,传递给find_data函数对3张表进行查找:
def find_data(code, time, start_i, end_i):
for t in time:
new_data = copy.deepcopy(company())
new_data.time = t
new_data.code = code
for i in range(start_i, end_i):
f_1rows = f_1Sheet1.row_values(i) # 获取行内容
f_2rows = f_2Sheet1.row_values(i)
f_3rows = f_3Sheet1.row_values(i)
if new_data.time == f_1rows[2]:
new_data.D = f_1rows[7]
new_data.name = f_1rows[1]
new_data.G = f_1rows[6]
new_data.J = f_1rows[8]
new_data.Q = f_1rows[5]
if new_data.time == f_2rows[2]:
new_data.F = f_2rows[4]
new_data.I = f_2rows[3]
# 管理层比例不为0 那么管理层类型就写1
if new_data.F != 0:
new_data.E = 1
else:
new_data.E = 0
if new_data.I != 0:
new_data.H = 1
else:
new_data.H = 0
if new_data.time == f_3rows[2]:
new_data.K = f_3rows[4]
new_data.L = f_3rows[6]
new_data.M = f_3rows[7]
new_data.N = f_3rows[10]
new_data.O = f_3rows[11]
new_data.P = f_3rows[12]
data.append(new_data)由于3张表企业结构统一,所以不需要逐一遍历比对,直接根据行列就能查找数据;先将数据对象推入数组,最后循环写入新文件即可。
def write_excel(data_list):
f = xlwt.Workbook() # 创建工作簿
'''
创建一个sheet:
sheet1
'''
sheet1 = f.add_sheet(u'sheet1', cell_overwrite_ok=True) # 创建sheet
row0 = [u'年份 ', u'股票代码', u'公司名称', u'总经理类型', u'管理层类型', u'管理层比例', u'董事长类型', u'董事会类型',
u'董事会比例', u'CEO及董事长类型', u'公司规模', u'财务杠杆', u'资产净利润率', u'资本密集度', u'托宾Q', u'股利支付率', u'行业']
# 生成第一行
for i in range(0, len(row0)):
sheet1.write(0, i, row0[i], set_style('Times New Roman', 220, True))
row = 0
for i in data_list:
# sheet1.write(1,0,"newsheet") #在(行,列)处填入数据
print(i)
row = row + 1
sheet1.write(row, 0, i.time)
sheet1.write(row, 1, i.code)
sheet1.write(row, 2, i.name)
sheet1.write(row, 3, i.D)
sheet1.write(row, 4, i.E)
sheet1.write(row, 5, i.F)
sheet1.write(row, 6, i.G)
sheet1.write(row, 7, i.H)
sheet1.write(row, 8, i.I)
sheet1.write(row, 9, i.J)
sheet1.write(row, 10, i.K)
sheet1.write(row, 11, i.L)
sheet1.write(row, 12, i.M)
sheet1.write(row, 13, i.N)
sheet1.write(row, 14, i.O)
sheet1.write(row, 15, i.P)
sheet1.write(row, 16, i.Q)
f.save('demo333.xls') # 保存文件,文件扩展名要以2003为准,xlsx改成 xls写一个等差数列,循环执行read_excel函数:
# 等差为4
k = 4
l = [i for i in range(3, 291, k)]
print('数据分段')
print(l)
for i in l:
read_excel(i, i + k + 1)部分调试数据:
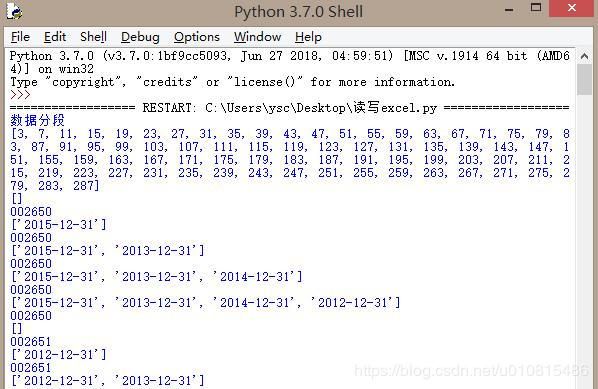
最终效果:

源码放上来,做个备份:
import xlrd
import xlwt
import copy
# 格式化数据对象
class company(object):
# 构造函数
def __init__(self):
self.time = ''
self.code = ''
self.name = ''
self.D = '' # 总经理类型
self.E = '' # 管理层类型
self.F = '' # 管理层比例
self.G = '' # 董事长类型
self.H = '' # 董事会类型
self.I = '' # 董事会比例
self.J = '' # CEO及董事长类型
self.K = '' # 公司规模
self.L = '' # 财务杠杆
self.M = '' # 资产净利润率
self.N = '' # 资本密集度
self.O = '' # 托宾Q
self.P = '' # 股利支付率
self.Q = '' # 行业
data = []
def findSmallest(arr):
smallest = arr[0] # 将第一个元素的值作为最小值赋给smallest
smallest_index = 0 # 将第一个值的索引作为最小值的索引赋给smallest_index
for i in range(1, len(arr)):
if arr[i] < smallest: # 对列表arr中的元素进行一一对比
smallest = arr[i]
smallest_index = i
return smallest_index
# 排序函数
def selectionSort(arr):
newArr = []
for i in range(len(arr)):
smallest = findSmallest(arr) # 一共要调用5次findSmallest
# 每一次都把findSmallest里面的最小值删除并存放在新的数组newArr中
newArr.append(arr.pop(smallest))
return newArr
f_1 = xlrd.open_workbook(r'C:\Users\ysc\Desktop\1.xls')
f_2 = xlrd.open_workbook(r'C:\Users\ysc\Desktop\2.xlsx')
f_3 = xlrd.open_workbook(r'C:\Users\ysc\Desktop\3.xls')
# print(f_1.sheet_names()) # 获取所有sheet
f_1Sheet1 = f_1.sheet_by_index(0)
f_2Sheet1 = f_2.sheet_by_index(0)
f_3Sheet1 = f_3.sheet_by_index(0)
# rows_1 = f_1Sheet1.row_values(0) # 获取第1行内容
# cols_1 = Sheet1.col_values(0) # 获取第1列内容
# 读excel
def read_excel(start, end):
code = ''
time = []
for i in range(start, end):
if i == 291:
time = selectionSort(time)
find_data(code, time, start, i)
for x in data:
print(x)
write_excel(data)
break
else:
rows = f_1Sheet1.row_values(i) # 获取行内容
if code == '':
code = rows[0]
print(time)
print(code)
if code == rows[0]:
time.append(rows[2])
print(time)
print(code)
if code != rows[0]:
time = selectionSort(time)
start_i = start
end_i = i
find_data(code, time, start_i, end_i)
break
def find_data(code, time, start_i, end_i):
for t in time:
new_data = copy.deepcopy(company())
new_data.time = t
new_data.code = code
for i in range(start_i, end_i):
f_1rows = f_1Sheet1.row_values(i) # 获取行内容
f_2rows = f_2Sheet1.row_values(i)
f_3rows = f_3Sheet1.row_values(i)
if new_data.time == f_1rows[2]:
new_data.D = f_1rows[7]
new_data.name = f_1rows[1]
new_data.G = f_1rows[6]
new_data.J = f_1rows[8]
new_data.Q = f_1rows[5]
if new_data.time == f_2rows[2]:
new_data.F = f_2rows[4]
new_data.I = f_2rows[3]
# 管理层比例不为0 那么管理层类型就写1
if new_data.F != 0:
new_data.E = 1
else:
new_data.E = 0
if new_data.I != 0:
new_data.H = 1
else:
new_data.H = 0
if new_data.time == f_3rows[2]:
new_data.K = f_3rows[4]
new_data.L = f_3rows[6]
new_data.M = f_3rows[7]
new_data.N = f_3rows[10]
new_data.O = f_3rows[11]
new_data.P = f_3rows[12]
data.append(new_data)
# 写excel
def set_style(name, height, bold=False):
# 设置单元格样式
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = name # 'Times New Roman'
font.bold = bold
font.color_index = 4
font.height = height
# borders= xlwt.Borders()
# borders.left= 6
# borders.right= 6
# borders.top= 6
# borders.bottom= 6
style.font = font
# style.borders = borders
return style
def write_excel(data_list):
f = xlwt.Workbook() # 创建工作簿
'''
创建一个sheet:
sheet1
'''
sheet1 = f.add_sheet(u'sheet1', cell_overwrite_ok=True) # 创建sheet
row0 = [u'年份 ', u'股票代码', u'公司名称', u'总经理类型', u'管理层类型', u'管理层比例', u'董事长类型', u'董事会类型',
u'董事会比例', u'CEO及董事长类型', u'公司规模', u'财务杠杆', u'资产净利润率', u'资本密集度', u'托宾Q', u'股利支付率', u'行业']
# 生成第一行
for i in range(0, len(row0)):
sheet1.write(0, i, row0[i], set_style('Times New Roman', 220, True))
row = 0
for i in data_list:
# sheet1.write(1,0,"newsheet") #在(行,列)处填入数据
print(i)
row = row + 1
sheet1.write(row, 0, i.time)
sheet1.write(row, 1, i.code)
sheet1.write(row, 2, i.name)
sheet1.write(row, 3, i.D)
sheet1.write(row, 4, i.E)
sheet1.write(row, 5, i.F)
sheet1.write(row, 6, i.G)
sheet1.write(row, 7, i.H)
sheet1.write(row, 8, i.I)
sheet1.write(row, 9, i.J)
sheet1.write(row, 10, i.K)
sheet1.write(row, 11, i.L)
sheet1.write(row, 12, i.M)
sheet1.write(row, 13, i.N)
sheet1.write(row, 14, i.O)
sheet1.write(row, 15, i.P)
sheet1.write(row, 16, i.Q)
f.save('demo333.xls') # 保存文件,文件扩展名要以2003为准,xlsx改成 xls
def main():
# 等差为4
k = 4
l = [i for i in range(3, 291, k)]
print('数据分段')
print(l)
for i in l:
read_excel(i, i + k + 1)
main()