JDK9.0 Hashtable源码阅读记录
和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射
Hashtable结构图
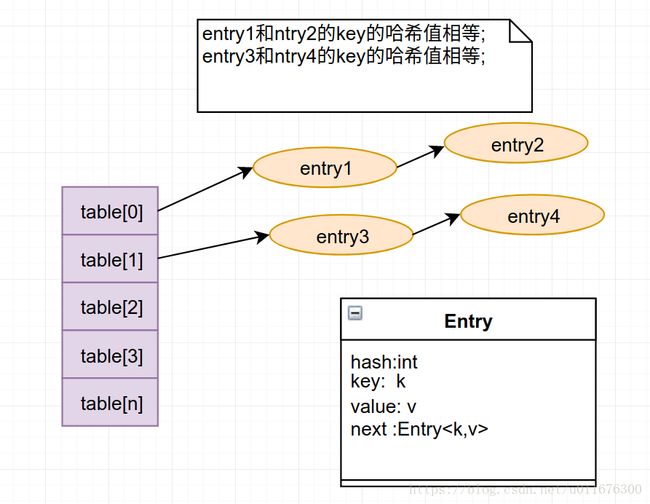
1. Hashtable使用Entry类型的数组保存每一个Entry的引用,由于会出现不同的key值的哈希值有可能一样,如果哈希值一致的键值对就保存在同一个index,然后使用链表进行关联.
2. Hashtable已经对部分方法进行加锁处理,因此其是线程安全的;
3. Hashtable的key和value都不能为null.
4. Hashtable扩容时是进行两倍扩容,扩容效率较低,因此应当初始化一个合适的容量.

两个不同的key值获取的哈希值一致,就会出现哈希冲突.
因为Hashtable是根据以下公式计算索引位置的,也就是同一个哈希值算出的索引位置是一致的,Hashtable使用链表在同一个位置存储多个entry.
int index = (hash & 0x7FFFFFFF) % tab.length;当进行查找或添加等其他操作时,需要比较哈希值和key是否一致,再进行相关操作.因此一个好的计算哈希值算法将会有效地提高效率.因为出现哈希冲突的次数越少,在进行相关操作时,需要比较的次数越多,将会导致效率降低.
for (Entry,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}Hashtable继承体系
Class Hashtable<K,V>
java.lang.Object
java.util.Dictionary<K,V>
java.util.Hashtable<K,V>
All Implemented Interfaces:
Serializable, Cloneable, Map<K,V>Dictionary 类是一个抽象类,用来存储键/值对,作用和Map类相似。
给出键和值,你就可以将值存储在Dictionary对象中。一旦该值被存储,就可以通过它的键来获取它。所以和Map一样, Dictionary 也可以作为一个键/值对列表。
Entry结构
可以看出,Entry实际上就是一个单向链表
private static class Entry<K,V> implements Map.Entry<K,V> {
//哈希值
final int hash;
//键
final K key;
//值
V value;
//指向下一个元素
Entry next;
} 私有变量
//是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的
private transient Entry[] table;
//含有键值对的数量
private transient int count;
//是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"
private int threshold;
//加载因子,这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少
//了空间开销,但同时也增加了查找某个条目的时间
//(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)
private float loadFactor;
//modCount是用来实现fail-fast机制的
private transient int modCount = 0;构造器
//指定初始容量和加载因子
//可以看出加载因子必须为正浮点数
public Hashtable(int initialCapacity, float loadFactor){
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
//指定初始容量,加载因子默认为0.75
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
//根据其他集合对象创建
public Hashtable(Map t) {
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}Enumeration
Enumeration接口中定义了一些方法,通过这些方法可以枚举(一次获得一个)对象集合中的元素。
这种传统接口已被迭代器取代,虽然Enumeration 还未被遗弃,但在现代代码中已经被很少使用了
//获取键
public synchronized Enumeration keys() {
return this.getEnumeration(KEYS);
}
//获取值
public synchronized Enumeration elements() {
return this.getEnumeration(VALUES);
} 测试
Hashtable hashtable = new Hashtable();
Enumeration enumerationKey;
Enumeration enumerationValue;
hashtable.put("num1",1);
hashtable.put("num2",2);
hashtable.put("num3",3);
hashtable.put("num4",4);
hashtable.put("num5",5);
enumerationKey = hashtable.keys();
while(enumerationKey.hasMoreElements()) {
System.out.println(enumerationKey.nextElement());
}
enumerationValue = hashtable.elements();
while(enumerationValue.hasMoreElements()) {
System.out.println(enumerationValue.nextElement());
} 输出
num5
num4
num3
num2
num1
5
4
3
2
1添加元素
public synchronized V put(K key, V value) {
// 从这可以看出,不允许添加null值
//没有对key进行判断,也就是key也可以为null?
//不是,如果key为null,获取哈希值将会导致NullPointerException异常
if (value == null) {
throw new NullPointerException();
}
Entry tab[] = table;
//获取key的哈希值
int hash = key.hashCode();
//获取索引位置
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry entry = (Entry)tab[index];
//由于会存在不同的key的哈希值一样的情况,因此同一个索引位置可能会存在多个键值对
//因此需要判断哈希值和key值,再进行插入
//这就是entry使用链表结构的原因
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
//如果不存在,则使用addEntry新增
addEntry(hash, key, value, index);
return null;
} private void addEntry(int hash, K key, V value, int index) {
Entry tab[] = table;
//容量不足,进行扩容处理
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry e = (Entry) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
modCount++;
} 获取元素
1.获取key的哈希值,该方法调用的是底层C/C++实现的代码,看不到源码.
2.通过哈希值计算索引
3.获取索引位置处的Entry,需要哈希值和key值一致,如果未查找到,返回null
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
//由于会存在不同的key的哈希值一样的情况,因此同一个索引位置可能会存在多个键值对
//因此需要判断哈希值和key值
for (Entry e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}扩容处理
1.扩容大小:原来容量的两倍
2.将旧的Hashtable数组上的Entry转移到新的Hashtable数组.这一步非常的耗时间,因此在构造Hashtable时,尽量指定合适的容量.
protected void rehash() {
int oldCapacity = table.length;
Entry[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry old = (Entry)oldMap[i] ; old != null ; ) {
Entry e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry)newMap[index];
newMap[index] = e;
}
}
} 相关文章
JDK9.0 ArrayList源码阅读记录
JDK9.0 LinkedList源码阅读记录
ArrayList和LinkedList性能比较
JDK9.0 Vector源码阅读记录
JDK9.0 Hashtable源码阅读记录
Java9.0 HashMap源码阅读记录
JDK9.0 HashSet源码阅读记录