Java基本数据类型知识总结
Java基本数据类型一览表
| 原生类型 | 占位数 | 是否有符号位 | 最小值 | 最大值 |
|---|---|---|---|---|
| boolean | 1 | 无 | —— | —— |
| byte | 8 | 有 | -2^7=-128=Byte.MIN_VALUE | 2^7-1=127=Byte.MAX_VALUE |
| char | 16 | 无 | ‘\u0000’=0=Character.MIN_VALUE | ‘\uFFFF’=2^15*2-1=65535=Character.MAX_VALUE |
| short | 16 | 有 | -2^15=Short.MIN_VALUE | 2^15-1=Short.MAX_VALUE |
| int | 32 | 有 | -2^31=Integer.MIN_VALUE | 2^31-1=Integer.MAX_VALUE |
| long | 64 | 有 | -2^63=Long.MIN_VALUE | 2^63-1=Long.MAX_VALUE |
| float | 32 | 有 | 1.4E-45f=Float.MIN_VALUE | 3.4028235E38=Float.MAX_VALUE |
| double | 64 | 有 | 4.9E-324=Double.MIN_VALUE | 1.7976931348623157E308==Double.MAX_VALUE |
| 原生类型 | 字节数 | 默认值 | 包装类 | 备注 |
|---|---|---|---|---|
| boolean | 1 或 4 | false | Boolean | boolean类型无法和其他类型直接转换 |
| byte | 1 | 0 | Byte | IO流中经常使用 |
| char | 2 | ‘\u0000’ | Character | |
| short | 2 | 0 | Short | 历史遗留类型,不再被使用 |
| int | 4 | 0 | Integer | |
| long | 8 | 0 | Long | 在int无法存储的情况下使用 |
| float | 4 | 0.0f | Float | 在对内存要求高对精度要求不高时使用 |
| double | 8 | 0.0d | Double |
表说明:
1.nEm表示n10的m次方,nE-m表示n10的m次方分之一。
2.Java核心技术卷一是说:“Java没有任何无符号类型”是错的,事实上char确实是无符号类型,boolean为什么不是无符号类型?因为虚拟机在存boolean时会将boolean用int来代替,而int是有符号的。
3.Java核心技术卷一上标明了float类型的取值范围是±3.40282347E38明显写错了。
因为Float.MIN_VALUE>(Float.MAX_VALUE*-1F),即1.4E-45大于-3.4028235E38。Float.MIN_VALUE+Float.MAX_VALUE也并不等于1。
4.为什么boolean的字节数是1或4呢?
《Java虚拟机规范》:“虽然定义了boolean这种数据类型,但是只对它提供了非常有限的支持。在Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达式所操作的boolean值,在编译之后都使用Java虚拟机中的int数据类型来代替,而boolean数组将会被编码成Java虚拟机的byte数组,每个元素boolean元素占8位”,也就是说,单个boolean占4字节,boolean数组里的boolean占1字节。
5.实际上,char占几个字节由使用的字符编码决定
脱离具体的编码谈某个字符占几个字节是没有意义的。
就好比有一个抽象的整数“42”,你说它占几个字节?这得具体看你是用 byte,short,int,还是 long 来存它。用 byte 存就占一字节,用 short 存就占两字节,int 通常是四字节,long 通常八字节。当然,如果你用 byte,受限于它有限的位数,有些数它是存不了的,比如 256 就无法放在一个 byte 里了。
字符是同样的道理,如果你想谈“占几个字节”,就要先把编码说清楚。
同一个字符在不同的编码下可能占不同的字节。
就以“字”字为例,“字”在 GBK 编码下占 2 字节,在 UTF-16 编码下也占 2 字节,在 UTF-8 编码下占 3 字节,在 UTF-32 编码下占 4 字节。
不同的字符在同一个编码下也可能占不同的字节。
“字”在 UTF-8 编码下占3字节,而“A”在 UTF-8 编码下占 1 字节。(因为 UTF-8 是变长编码)
而 Java 中的 char 本质上是 UTF-16 编码。而 UTF-16 实际上也是一个变长编码(2 字节或 4字节)。
如果一个抽象的字符在 UTF-16 编码下占 4 字节,显然它是不能放到 char 中的。换言之, char 中只能放 UTF-16 编码下只占 2 字节的那些字符。
而 getBytes 实际是做编码转换,你应该显式传入一个参数来指定编码,否则它会使用缺省编码来转换。
你说“ new String(“字”).getBytes().length 返回的是3 ”,这说明缺省编码是 UTF-8.如果你显式地传入一个参数,比如这样“ new String(“字”).getBytes(“GBK”).length ”,那么返回就是 2.
你可以在启动 JVM 时设置一个缺省编码,
假设你的类叫 Main,那么在命令行中用 java 执行这个类时可以通过 file.encoding 参数设置一个缺省编码。比如这样:java -Dfile.encoding=GBK Main这时,你再执行不带参数的 getBytes() 方法时,new String(“字”).getBytes().length 返回的就是 2 了,因为现在缺省编码变成 GBK 了。当然,如果这时你显式地指定编码,new String(“字”).getBytes(“UTF-8”).length 返回的则依旧是 3.
否则,会使用所在操作系统环境下的缺省编码。
通常,Windows 系统下是 GBK,Linux 和 Mac 是 UTF-8.但有一点要注意,在 Windows 下使用 IDE 来运行时,比如 Eclipse,如果你的工程的缺省编码是 UTF-8,在 IDE 中运行你的程序时,会加上上述的 -Dfile.encoding=UTF-8 参数,这时,即便你在 Windows 下,缺省编码也是 UTF-8,而不是 GBK。
由于受启动参数及所在操作系统环境的影响,不带参数的 getBytes 方法通常是不建议使用的,最好是显式地指定参数以此获得稳定的预期行为。
字符相关知识
代码单元就是char类型的数值范围,0-65535都是代码单元。
代码点就是超出65535的代码单元,这时由于char类型的最大值限制,导致char无法表示一个大于65535的字符。
为解决这个问题,开发JavaAPI的攻城狮就将大于65535的字符统一用两个代码单元(0-65535)表示,并且规定,这两个代码单元是好基友,是一个整体,我们就叫它们代码点好了!
为了将所有字符都有统一的名字,API的攻城狮也是蛮拼的,攻城狮们干脆再规定,0-65535的代码单元也可以叫代码点!
以下为代码单元和代码点的操作代码:
char[] c = Character.toChars(65536);
String str = new String(c);
System.out.println("我是一个代码点,不信你看: " + str.codePointCount(0, str.length()));// 1
System.out.println("我是这个代码点数值为:" + str.codePointAt(0));
System.out.println("我是两个代码单元,不信你看: " + str.length());
System.out.println("我是第一个代码单元:" + (int) str.charAt(0));
System.out.println("我是第一个代码单元:" + (int) str.charAt(1));
String test = "A" + str + "B";
for (int i = 0; i < test.length(); i++) {
System.out.println("遍历字符串的代码单元是这样干的:" + (int) test.charAt(i));
}
for (int i = 0; i < test.length(); i++) {
int codePoint = test.codePointAt(i);
System.out.println("遍历字符串的代码点是这样干的:" + codePoint);
if (Character.isSupplementaryCodePoint(codePoint)) {
i++;
}
}
为什么不建议使用char?
String c1="![]() ";//数学上的整数集符号,这个符号无法用char表示,因为它超出65535了,所以只能采用是两个char(代码单元)表示。
";//数学上的整数集符号,这个符号无法用char表示,因为它超出65535了,所以只能采用是两个char(代码单元)表示。
String str=c1+“A”;
char c2=str.chartAt(1);
结果c2不是你想要的’A’,而是![]() 的后半个字符(代码单元)。
的后半个字符(代码单元)。
代码单元代码点相关的详细资料请查看:
Java中的代码点和代码单元
字符编码相关文章推荐
https://xiaogd.net/category/%E5%AD%97%E7%AC%A6%E9%9B%86%E7%BC%96%E7%A0%81%E4%B8%8E%E4%B9%B1%E7%A0%81/
Java如何存储负数
1.如何存储负数
Java是采用"2的补码"(简称补码)存储负数的。
如8位的数字00000001表示正数1,11111111示负数1。
2.补码
补码是基于有符号位的(基于置符号位的),正数的补码等于数字本身(这句话要这样理解:并不是正数的补码等于本身,而是正数不需要计算它的补码,正数计算的补码是给负数用的,所以规定正数的补码等于本身)。
3.“2的补码”
"2的补码"是将一个数的反码+1。
4.反码
反码就是将数字的二进制位全部取反,0变成1,1变成0,正数的反码等于数字本身(这句话要这样理解:并不是正数的反码等于本身,而是正数不需要计算它的反码,正数计算的反码是给负数用的,所以规定正数的反码等于本身)。
如00000001的反码就是11111110。
##5.“1的补码”
"1的补码"不用细究它,因为"1的补码"的结果和反码一致,只是它采用的不是”二进制位全部取反“的操作方式。我们不用管它是怎么算的,直接将它理解成反码就对了。
6.置符号位
数字置符号位是二进制中表示正负的方法,一个数字的最高位就是符号位,如果符号位为0表示正,如果符号位为1表示负。
7.直观表示法
直观便于理解的表示二进制负数的形式是置符号位,不需要采用补码。
如8位的数字00000001表示正数1,10000001示负数1。
8.为什么采用补码表示负数
之所以采用补码表示负数,而不是直接采用直观便于理解的置符号位,是因为在计算机中直观表示在做负数运算是不能得到正确的结果,而补码却可以做到。
如:
数00000001(数字1的直观表示法)
+10000001(数字-1的直观表示法)
=10000010(数字-2的直观表示法)
很明显1+(-1)=0而不是-2啊!!!
而采用补码方式却可以得到正确的结果:
数00000001(数字1的补码表示法)
+11111111(数字-1的补码表示法)
注意此时只有8位,超过8位会溢出,所以:
=00000000(数字0的补码表示法)
基本类型转换
1.boolean与其他任何类型都不兼容。
2.小类型向大类型转换时,如果小类型不是char类型,那么就执行有符号扩展,如果小类型是char那么永远执行无符号扩展。
有符号扩展:
byte b=“00000001”;
short s=b;//此时s的值为0000000000000001
byte b=“11111111”;//11111111是byte类型-1的补码形式
short s=b;//此时s的值为1111111111111111,1111111111111111是short类型-1的补码形式。
无符号扩展:
char c=“1111111111111111”;
int i=c;//此时i的值为00000000000000001111111111111111。
char c=“0000000000000001”;
int i=c;//此时i的值为00000000000000000000000000000001。
3.大类型向小类型转换时需要强制转换。
如:
int i=1;
short s=(int)i;
4.不同类型数据在计算时,统一会先转换成最大的类型再计算。
如:
System.out.println(0.1D+0.2F);//0.2F会被先转成0.2D再与0.1D计算
System.out.println(1L+2);//2会被先转成2L再与1L计算
System.out.println(1L+2);//2会被先转成2L再与1L计算
5.非浮点类型在和浮点类型数据计算时,统一会先转换成浮点类型再计算。
如:
System.out.println(1+0.2F);//1会被先转成1F再与0.2F计算
System.out.println(1L+0.2F);//1L会被先转成1.0F再与0.2F计算
System.out.println(1+0.2D);//1会被先转成1.0D再与0.2D计算
包装类与原生类型的转换
原生类型转包装类:
new 包装类(原生类型的值),如:new Boolean(true);
包装类转原生类型:
包装类对象.原生类型Value,如:new Boolean(true).booleanValue();
利用java5的自动拆包:Boolean b1=true;boolean b2=new Boolean(true);
原生类型和包装类做运算时,会将包装类拆成原生类后再做计算。
基本类型与字符串的转换
基本类型转字符串:
1、基本类型的值拼接上空字符串(其实就是java5自动包装成包装类后调用toString方法),如:String s=true+""。
2、使用String类的静态valueOf方法:如:String s=String.valueOf(true);
字符串转基本类型:
是用原生类型的包装类的静态方法parse基本类型或静态方法valueOf,如:boolean parseBoolean = Boolean.parseBoolean(“true”);Boolean valueOf = Boolean.valueOf(“true”);
其中Integer的parseInt还支持将2进制、8进制、16进制字符串转int,Integer.parseInt(“11”,2);//结果为3
原生类型和包装类型的区别
原生类型是java虚拟机定义的基本类型,不是类,包装类型是类,是对原生类型的包装,不但存储了原生类型的数据,而且提供了很多操作原生类型数据的方法。
包装类大部分情况下不能直接用==判断是否相等,Short i1=127;等于Short i2=127;但是Short i1=128;不等于Short i2=128;
浮点类型相关知识
1.浮点类型的存储范围很大
float虽然和int占位一样,但float能存储的值比int大太多,可以参见Integer.MAX_VALUE和Float.MAX_VALUE,不但如此,float比long都大很多,另外double又比float更大。 所以,long存放不了的数字可以存放在float,float放不下的数字可以放入double中。
2.浮点类型无法完全精确表示小数
float和double在计算时都不是完全精确的,float能精确到6位或7位小数,double能精确到15位小数。
超出范围的小数会被四舍五入。
例如:
System.out.println(1.0f/0.3f);
System.out.println(2.0f/0.3f);
System.out.println(1.0d/0.3d);
System.out.println(2.0d/0.3d);
打印:
3.3333333
6.6666665
3.3333333333333335
6.666666666666667
3.二进制无法精确表示一些可以在10进制精确表示的小数
二进制无法精确表示十进制中的一些数,就像十进制无法精确表示1/3一样,二进制无法精确表示0.1等等各种小数。
(以下是复制的)
二进制表示小数的时候只能够表示能够用1/(2^n)的和的任意组合。
例如:
0.5能够表示,因为它可以表示成为1/2。
0.75也能够表示,因为它可以表示成为1/2+1/(2^2)。
0.875也能够表示,因为它可以表示成为1/2+1/(22)+1/(23)。
0.1不能够精确表示,因为它不能够表示成为1/(2^n)的和的形式。
4.浮点类型在计算时容易出现偏差
原因有两点:
1.因为浮点类型的精度都是固定的,超出范围的精度会被四舍五入。
2.因为二进制无法精确表示十进制中的一些数,所以你会看到很奇怪的结果,如:
System.out.println(1.0-0.93);
System.out.println(1.0-0.7);
System.out.println(1.1-1.0);
打印:
0.06999999999999995//计算机无法表达0.07
0.30000000000000004//计算机无法表达0.3
0.10000000000000009//计算机无法表达0.1
要想使用完全精确的计算请使用BigDecimal,并且是BigDecimal(String val)这个构造方法。
5.不要使用==判断两个浮点数的大小
对于浮点类型之间的大小判断,不应该使用==,而只能使用>、<、>=、<=,愿意上面第4点已经说了。
示例:
float f1=1.345f;
float f2=1.123f;
System.out.println(f1+f2-f2==f1);//打印false
了解浮点数详细信息请查看:你的小数点去哪了
小数在计算机中的存储形式
二进制浮点数和十进制浮点数相互转换
十进制转二进制:
整数部分,看图:
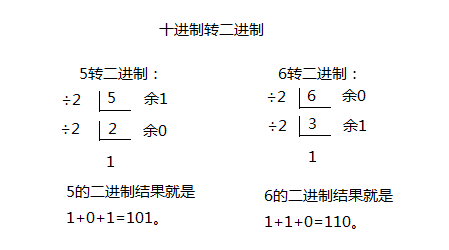
小数部分,看图:

二进制转十进制:
二进制转十进制比较简单,将二进制的所有面值乘以2的“字面值对应的权系”次方相加,语言不太好表达,看公式:
n1*(2m2)+n2*(2m2)+n3*(2^m3)+…
例如:
1101.01=12(2^3) +12(22)+0*(21)+1*(20)+0*(2-1)+1*(2^-2)=8+4+0+1+0+0.25=13.25。