Jena RDF API 使用教程
Jena RDF API 使用教程
- Jena
- RDF(Resource Description Framework)
- 基础Java API
- 使用Maven引入Jena
- 创建资源(Resource)
- 描述(Statements)
- 读写RDF
- 将RDF写入XML
- 读取RDF
- 控制前缀
- Jena RDF包
- 深入Model
- 查询Model
- Model中的操作
- 容器
本文是对Jena 官方文档进行的提炼和总结,其中也糅合了一些个人的理解。
Jena
A free and open source Java framework for building Semantic Web and Linked Data applications.
上文摘自Jena 官网,是Apache Jena官方对自家产品的描述与定位:一个用于构建语义网和链接数据应用的免费并且开源的框架。
RDF(Resource Description Framework)
资源描述框架,W3C所推荐的一种用来描述资源的框架。什么是资源?你可以这么理解:存在于客观世界的,以及存在于全人类共同想象中的所有人或物都是资源。
你自己是一个资源,你的个人主页是一个资源,数字1是一个资源,某部小说里的某个人物同样是一个资源。
再来举个实际的例子:
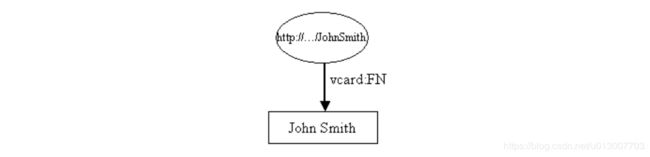
上图椭圆形中描述的就是一个资源:John Smith,只不过它是用URI(统一资源定位符)来描述的。其中,"http://…/"是一个命名空间。
资源拥有属性,在上图的例子中,John Smith这个资源只有一个属性 vcard:FN,这个属性的属性值是“John Smith”,这个属性所代表的含义是:“John Smith这个资源(人)的全名是John Smith”。
在这个例子中,属性值是一个字面量。在实际的使用中,属性值可以是字面量,也可以是另一个通过URI来描述的资源。
上图所描述的资源可以通过三元组的方式来描述,也就是通过“主谓宾”的方式来描述:(John Smith,vcard:FN,John Smith),其中John Smith是主语,vcard:FN是谓语,John Smith是宾语。
注意,主语和谓语虽然都是John Smith,但是它们有着本质的区别。主语John Smith表示的是一个资源,或者说是一个实体(John Smith这个活生生的人),而宾语John Smith是一个字面量(John Smith这个字符串)。
基础Java API
使用Maven引入Jena
<dependency>
<groupId>org.apache.jenagroupId>
<artifactId>apache-jena-libsartifactId>
<type>pomtype>
<version>3.12.0version>
dependency>
根据实际需要的版本,自行修改version标签中的值即可。
创建资源(Resource)
我们根据上文的例子,来创建一个“John Smith”资源:
// 统一资源描述符
String uri = "http://www.beanyon.site/John";
// 全名(属性vcard:FN的值)
String fullName = "John Smith";
// 创建Model(也就是Graph)
Model model = ModelFactory.createDefaultModel();
// 通过创建好的model对象和uri,创建资源
Resource resource = model.createResource(uri);
// 为资源添加属性和属性值,其中VCARD.FN是Jena内置的属性
resource.addProperty(VCARD.FN, fullName);
我们上文已经提到过,属性值可以是字面量,也可以是另一个资源,我们用一个图来进行说明
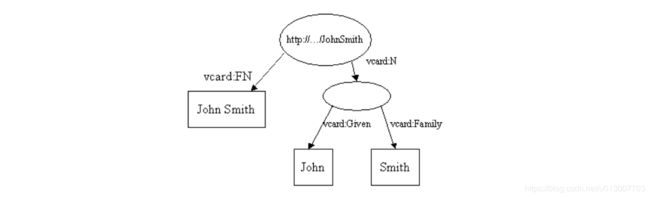
在上图中,John Smith这个资源多了一个属性:vcard:N,它的属性值是一个空(没有URI)的资源,但是这个空资源有两个属性,分别是vcard:Given和vcard:Family,这两个属性和vcard:FN一样,是Jena内置的属性。适应上图的java代码如下
// 统一资源描述符
String uri = "http://www.beanyon.site/John";
// 人名(属性vcard:Given的值)
String givenName = "John";
// 家族名(属性vcard:Family的值)
String familyName = "Smith";
// 全名(属性vcard:FN的值)
String fullName = givenName + " " + familyName;
// 创建Model(也就是Graph)
Model model = ModelFactory.createDefaultModel();
// 通过创建好的model对象和uri,创建资源,作为John Smith资源
Resource resource = model.createResource(uri);
// 创建一个空(没有URI)的资源,作为名称资源
Resource nameResourse = model.createResource();
// 为名称资源添加属性
nameResourse.addProperty(VCARD.Given, givenName);
nameResourse.addProperty(VCARD.Family, familyName);
// 将名称资源作为属性添加到John Smith资源中
resource.addProperty(VCARD.N, nameResourse);
// 为John Smith资源添加字面量属性
resource.addProperty(VCARD.FN, fullName);
描述(Statements)
上文我们已经提到过,资源可以用三元组的形式来表示,一个三元组又被称为一个描述(statement)。Jena为我们提供了遍历描述(三元组)的API
// 从model中读取所有的statement
StmtIterator stmtIterator = model.listStatements();
// 遍历statement
while(stmtIterator.hasNext()){
Statement statement = stmtIterator.nextStatement();
// 从statement中获取主、谓、宾
Resource subject = statement.getSubject();
Property predicate = statement.getPredicate();
RDFNode object = statement.getObject();
System.out.print(subject.toString());
System.out.print(" " + predicate.toString() + " ");
// 由于宾语可能是字面量,也可能是资源,所以需要分开处理
if(object instanceof Resource){
System.out.print(object.toString());
} else {
System.out.print("\"" + object.toString() + "\"");
}
System.out.println(" .");
}
代码执行结果如下
18f3827e-9f46-4b51-9f84-8114c6c5f12e http://www.w3.org/2001/vcard-rdf/3.0#Family "Smith" .
18f3827e-9f46-4b51-9f84-8114c6c5f12e http://www.w3.org/2001/vcard-rdf/3.0#Given "John" .
http://www.beanyon.site/John http://www.w3.org/2001/vcard-rdf/3.0#FN "John Smith" .
http://www.beanyon.site/John http://www.w3.org/2001/vcard-rdf/3.0#N 18f3827e-9f46-4b51-9f84-8114c6c5f12e .
18f3827e-9f46-4b51-9f84-8114c6c5f12e 是 Jena内部的标识符,可以理解为id。
读写RDF
将RDF写入XML
通常的做法是将RDF写入一个XML文件。
// 将model中的资源信息以XML的格式写入控制台,写入文件的话替换输出流即可
model.write(System.out);
控制台输入如下
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:vcard="http://www.w3.org/2001/vcard-rdf/3.0#">
<rdf:Description rdf:about="http://www.beanyon.site/John">
<vcard:FN>John Smithvcard:FN>
<vcard:N rdf:parseType="Resource">
<vcard:Family>Smithvcard:Family>
<vcard:Given>Johnvcard:Given>
vcard:N>
rdf:Description>
rdf:RDF>
以上方式不适合处理model比较大的情况,当要写入大文件的时候,推荐使用下面的API
// 当要写入比较大的model时,可以使用N-TRIPLES方式
model.write(System.out, "N-TRIPLES");
可以得到更加紧凑的结果
_:B8fb9545cX2Dc894X2D4e42X2D8108X2D687009b27999 <http://www.w3.org/2001/vcard-rdf/3.0#Family> "Smith" .
_:B8fb9545cX2Dc894X2D4e42X2D8108X2D687009b27999 <http://www.w3.org/2001/vcard-rdf/3.0#Given> "John" .
<http://www.beanyon.site/John> <http://www.w3.org/2001/vcard-rdf/3.0#FN> "John Smith" .
<http://www.beanyon.site/John> <http://www.w3.org/2001/vcard-rdf/3.0#N> _:B8fb9545cX2Dc894X2D4e42X2D8108X2D687009b27999 .
读取RDF
Jena也为我们提供了从本地文件中读取RDF的API
Model model = ModelFactory.createDefaultModel();
// 创建文件流
InputStream is = FileManager.get().open("vc-db-1.rdf");
// 从文件流中读取内容
model.read(is, "");
// 输出
model.write(System.out, "N-TRIPLES");
其中vc-db-1.rdf是官方提供的一个测试文件,可以点此下载。read()方法的第二个参数是用于解析相关的URI的URI,可以留空。输出内容格式类似于上文已经给出的内容,此处不再赘述。
控制前缀
为了减少RDF存储时占用的空间,我们可以为比较长的命名空间设置一个较短的前缀。Jena允许我们自定义命名空间的前缀,如果我们没有为命名空间指定一个前缀,那么Jena将会为我们自动生成一个。
Model m = ModelFactory.createDefaultModel();
// 自定义两个命名空间
String nsA = "http://somewhere/else#";
String nsB = "http://nowhere/else#";
// 使用这两个命名空间
Resource root = m.createResource( nsA + "root" );
Property P = m.createProperty( nsA + "P" );
Property Q = m.createProperty( nsB + "Q" );
Resource x = m.createResource( nsA + "x" );
Resource y = m.createResource( nsA + "y" );
Resource z = m.createResource( nsA + "z" );
m.add( root, P, x ).add( root, P, y ).add( y, Q, z );
System.out.println( "# -- 没有给定前缀,使用默认前缀" );
m.write( System.out );
System.out.println( "# -- nsA设置了前缀" );
m.setNsPrefix( "nsA", nsA );
m.write( System.out );
System.out.println( "# -- nsA和nsB都设置了前缀" );
m.setNsPrefix( "cat", nsB );
m.write( System.out );
# -- 没有给定前缀,使用默认前缀,可以看到前缀分别是j.0和j.1
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:j.0="http://somewhere/else#"
xmlns:j.1="http://nowhere/else#">
<rdf:Description rdf:about="http://somewhere/else#root">
<j.0:P>
<rdf:Description rdf:about="http://somewhere/else#y">
<j.1:Q rdf:resource="http://somewhere/else#z"/>
rdf:Description>
j.0:P>
<j.0:P rdf:resource="http://somewhere/else#x"/>
rdf:Description>
rdf:RDF>
# -- nsA设置了前缀,nsA的前缀从j.0变成了nsA
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:nsA="http://somewhere/else#"
xmlns:j.0="http://nowhere/else#">
<rdf:Description rdf:about="http://somewhere/else#root">
<nsA:P>
<rdf:Description rdf:about="http://somewhere/else#y">
<j.0:Q rdf:resource="http://somewhere/else#z"/>
rdf:Description>
nsA:P>
<nsA:P rdf:resource="http://somewhere/else#x"/>
rdf:Description>
rdf:RDF>
# -- nsA和nsB都设置了前缀,j.0变成了nsA,j.1变成了cat
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:nsA="http://somewhere/else#"
xmlns:cat="http://nowhere/else#">
<rdf:Description rdf:about="http://somewhere/else#root">
<nsA:P>
<rdf:Description rdf:about="http://somewhere/else#y">
<cat:Q rdf:resource="http://somewhere/else#z"/>
rdf:Description>
nsA:P>
<nsA:P rdf:resource="http://somewhere/else#x"/>
rdf:Description>
rdf:RDF>
Jena RDF包
Jena是一组构建语义网应用的Java API。
org.apache.jena.rdf.model,核心包,提供了RDF所有的核心概念的实现,包括 models,resources,properties,literals,statements 等
org.apache.jena…impl,一系列实现包。
深入Model
我们可以根据资源的URI,从模型中获取这个资源。如果模型中已经存在URI所代表的资源,则会直接返回这个资源,如果不存在,模型则会创建一个新的资源。
// 从模型中获取资源,如果不存在,则创建
Resource resource = model.getResource(johnSmithURI);
我们还可以从资源中根据属性名称读取属性值。由于属性值可以是一个资源,也可以是一个字面量,因此无法在编译器确定获取到的属性值到底是何种类型。因此,Jena针对这些情况,分别为我们包装了几种方法。
// 以Object形式获取属性值
Object name = resource.getProperty(VCARD.N).getObject();
// 根据实际情况强制类型转换为Resource或者String
Resource nameResource = (Resource)name;
String nameLiteral = (String)name;
// 以Resource形式获取属性值
Resource nameResource = resource.getProperty(VCARD.N).getResource();
// 以字面量(String)形式获取属性值
String nameLiteral = resource.getProperty(VCARD.FN).getString();
Jena允许我们为一个属性添加多个值,比如昵称可能有多个
vcard.addProperty(VCARD.NICKNAME, "Smithy")
.addProperty(VCARD.NICKNAME, "Adman");
当我们通过 getProperty(VCARD.NICKNAME) 方法获取昵称时,该方法只会返回一个属性值,并且并不保证每次返回回来的是同一个属性值。因此当我们明确知道某个属性的值有多个时,就应该使用 listProperties() 方法,该方法会返回一个迭代器,通过迭代器可以获得所有的属性值。
// 列出所有的nickname
StmtIterator iter = vcard.listProperties(VCARD.NICKNAME);
while (iter.hasNext()) {
System.out.println(" " + iter.nextStatement()
.getObject()
.toString());
}
输出结果如下
The nicknames of "John Smith" are:
Smithy
Adman
查询Model
Jena 提供了一些在model中查询数据的API,需要注意的是,由于查询性能的限制,这些API并不推荐在大规模的model上进行查询,在大规模的model中进行查询时推荐使用SPARQL。
// 查询所有的三元组
model.listStatements();
// 查询所有的主语
model.listSubjects();
// 根据属性查询主语,属性值可以不传,会调用对应的重载方法
model.listSubjectsWithProperty(Property p, RDFNode o);
以上这些方法其实都是 model.listStatements(Selector s) 方法的语法糖。其中 s 定义了具体的查询条件。Selector 接口 目前只有一个实现类 SimpleSelector,可以通过一下代码创建一个 SimpleSelector 对象的实例
Selector selector = new SimpleSelector(subject, predicate, object);
通过 selector,可以查询到所有匹配subject、predicate、object 的 statements,如果将这三个参数中的某几个置为null,则会匹配对应所有的的 statements。
比如
Selector selector = new SimpleSelector(null, null, null);
将会返回model中所有的statements。
Selector selector = new SimpleSelector(null, VCARD.FN, null);
将会返回所有以 VCARD.FN 为谓语的 statements。
listStatements( S, P, O )
等价于
listStatements( new SimpleSelector( S, P, O ) )
当我们使用 SimpleSelector 定义查询规则的时候,我们可以通过复写 selects 方法的方式进一步对查询结果进行过滤。
// 查询所有谓语为 VCARD.FN 并且全名以“smith”结尾的statements
StmtIterator iter = model.listStatements(
new SimpleSelector(null, VCARD.FN, (RDFNode) null) {
public boolean selects(Statement s)
{return s.getString().endsWith("Smith");}
});
Model中的操作
Jena 为我们提供了三种将model作为整体进行操作的API,分别是合并、交叉(求同)、求异。
以合并操作为例,顾名思义,就是把两个有差异的 model 合并为一个 model。
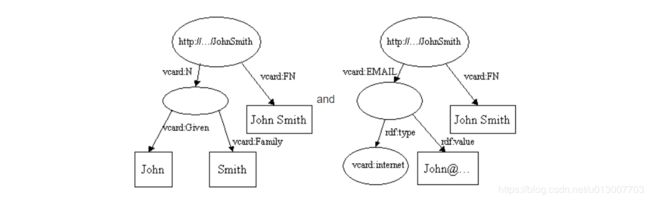
如上图所示,这两个model所描述的资源是同一个,但是它们具有一些不同的属性,我们可以将其合并为下图所描述的样子。vcard:FN 在上图中的两个model中都出现了,因此只会保留一个。
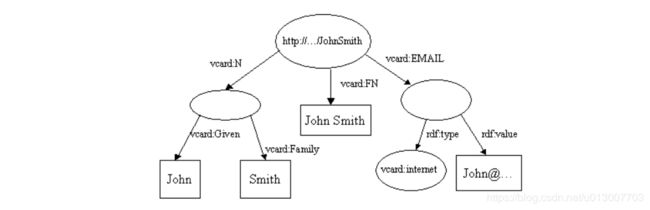
进行合并、交叉、求异的API如下
String uri = "http://www.beanyon.site/JohnSmith";
String fullName = "John Smith";
String givenName = "John";
String familyName = "Smith";
String email = "[email protected]";
String w3cUri = "http://www.w3.org/2006/vcard/ns#";
// 创建第一个model(FN,N)
Model model1 = ModelFactory.createDefaultModel();
Resource resource1 = model1.createResource(uri);
resource1.addProperty(VCARD.FN, fullName);
Resource resource2 = model1.createResource();
resource2.addProperty(VCARD.Given, givenName).addProperty(VCARD.Family, familyName);
resource1.addProperty(VCARD.N, resource2);
// 创建第二个model(FN,EMAIL)
Model model2 = ModelFactory.createDefaultModel();
model2.setNsPrefix("ns", w3cUri);
Resource resource3 = model2.createResource(uri);
resource3.addProperty(VCARD.FN, fullName);
Resource resource4 = model2.createResource();
resource4.addProperty(RDF.type, VCARD4.Internet).addProperty(RDF.value, email);
resource3.addProperty(VCARD.EMAIL, resource4);
System.out.println("-------------model1------------");
model1.write(System.out);
System.out.println("-------------model2------------");
model2.write(System.out);
System.out.println("-------------merge model------------");
Model mergeModel = model1.union(model2);
mergeModel.write(System.out);
System.out.println("-------------intersection model------------");
Model intersectionModel = model1.intersection(model2);
intersectionModel.write(System.out);
System.out.println("-------------difference model------------");
Model differenceModel = model1.difference(model2);
differenceModel.write(System.out);
输出结果如下
-------------model1------------
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:vcard="http://www.w3.org/2001/vcard-rdf/3.0#">
<rdf:Description rdf:about="http://www.beanyon.site/JohnSmith">
<vcard:N rdf:parseType="Resource">
<vcard:Family>Smithvcard:Family>
<vcard:Given>Johnvcard:Given>
vcard:N>
<vcard:FN>John Smithvcard:FN>
rdf:Description>
rdf:RDF>
-------------model2------------
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:vcard="http://www.w3.org/2001/vcard-rdf/3.0#"
xmlns:ns="http://www.w3.org/2006/vcard/ns#">
<rdf:Description rdf:about="http://www.beanyon.site/JohnSmith">
<vcard:EMAIL>
<ns:Internet>
<rdf:value>[email protected]rdf:value>
ns:Internet>
vcard:EMAIL>
<vcard:FN>John Smithvcard:FN>
rdf:Description>
rdf:RDF>
-------------merge model------------
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:vcard="http://www.w3.org/2001/vcard-rdf/3.0#"
xmlns:ns="http://www.w3.org/2006/vcard/ns#">
<rdf:Description rdf:about="http://www.beanyon.site/JohnSmith">
<vcard:EMAIL>
<ns:Internet>
<rdf:value>[email protected]rdf:value>
ns:Internet>
vcard:EMAIL>
<vcard:FN>John Smithvcard:FN>
<vcard:N rdf:parseType="Resource">
<vcard:Given>Johnvcard:Given>
<vcard:Family>Smithvcard:Family>
vcard:N>
rdf:Description>
rdf:RDF>
-------------intersection model------------
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:vcard="http://www.w3.org/2001/vcard-rdf/3.0#">
<rdf:Description rdf:about="http://www.beanyon.site/JohnSmith">
<vcard:FN>John Smithvcard:FN>
rdf:Description>
rdf:RDF>
-------------difference model------------
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:vcard="http://www.w3.org/2001/vcard-rdf/3.0#">
<rdf:Description rdf:about="http://www.beanyon.site/JohnSmith">
<vcard:N rdf:parseType="Resource">
<vcard:Given>Johnvcard:Given>
<vcard:Family>Smithvcard:Family>
vcard:N>
rdf:Description>
rdf:RDF>
容器
RDF 定义了一种特殊的资源,用来描述事物的集合,就是容器。容器中的成员可以是字面量,也可以是资源。RDF 为我们提供了三种容器:
- BAG,无序的集合
- ALT,无序的集合,主要用来存储可选的资源
- SEQ,有序的集合
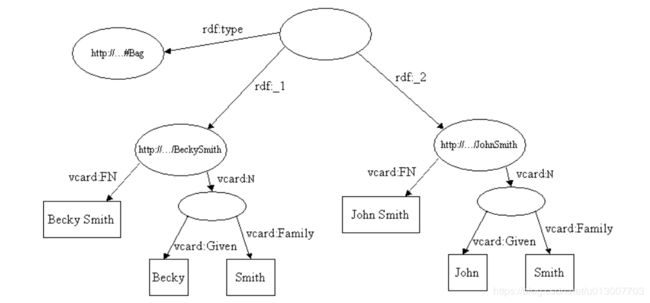
如上图所示,空节点就是一个BAG,它有一个属性叫做 rdf:type,值是 “http://…#BAG”。这个BAG描述了一个全名以“Smith”结尾的名片资源集合。
// 创建一个BAG容器
Bag bag = model.createBag();
// 创建一个选择器,选择VCARD.FN属性值以“Smith”结尾的statement
SimpleSelector selector = new SimpleSelector(null, VCARD.FN, (RDFNode) null) {
@Override
public boolean selects(Statement s) {
return s.getString().endsWith("Smith");
}
};
// 使用选择器从model中进行查询
StmtIterator stmtIterator = model.listStatements(selector);
// 将查询到的结果加入到BAG容器中
while(stmtIterator.hasNext()){
Statement statement = stmtIterator.nextStatement();
bag.add(statement);
}
model.write(System.out);
输出结果如下,可以看到 John Smith 和 Becky Smith 两条资源已经被加入到了BAG中
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:vcard="http://www.w3.org/2001/vcard-rdf/3.0#">
<rdf:Bag>
<rdf:li>[http://www.beanyon.site#BeckySmith, http://www.w3.org/2001/vcard-rdf/3.0#FN, "Becky Smith"]rdf:li>
<rdf:li>[http://www.beanyon.site#JohnSmith, http://www.w3.org/2001/vcard-rdf/3.0#FN, "John Smith"]rdf:li>
rdf:Bag>
<rdf:Description rdf:about="http://www.beanyon.site#JohnSmith">
<vcard:FN>John Smithvcard:FN>
rdf:Description>
<rdf:Description rdf:about="http://www.beanyon.site#BeanYon">
<vcard:FN>BeanYonvcard:FN>
rdf:Description>
<rdf:Description rdf:about="http://www.beanyon.site#BeckySmith">
<vcard:FN>Becky Smithvcard:FN>
rdf:Description>
rdf:RDF>