Python网络爬虫-使用Selenium爬取京东商品
Python网络爬虫-模拟Ajax请求抓取微博中我们了解了Ajax的分析和抓取的方式,但是有很多的网站即使是Ajax来获取的数据,但是其Ajax接口含有很多加密参数,我们很难找出其中的规律,也就很难直接使用Ajax来抓取。
为了解决这些问题,我们可以直接使用模拟浏览器运行的方式来实现,这样就可以做到在浏览器中看到是什么样,抓取的源码就是什么样,也就是可见即可爬。这样我们就不用再去管网页内部的JavaScript用了什么算法渲染页面,不用管网页后台的Ajax接口到底有哪些参数。
Python提供了许多模拟浏览器运行的库,如Selenium、Splash等。
Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些JavaSript动态渲染的页面来说,此种抓取方式非常有效。
下面使用Selenium来模拟浏览器操作爬取京东商城的商品信息。
1.目标
使用Selenium爬取京东商城商品信息并使用xpath解析得到商品的名称、价格、评论和店铺名称并将其写入文件保存。
2.准备工作
- Chrome浏览器
- 安装Python的Selenium库
- 在Chrome里面配置ChromeDriver
3.网页分析
人工输入京东的网址https://www.jd.com/,然后在搜索框中输入ipad点击确认,往下拉到网页底部,页面上共加载出60个有关ipad关键字的商品信息,并且在页面底部有一个分页的导航,其中既包括了前7页的链接,页包括了下一页的链接。
4.爬取流程
- 0基础url:https://www.jd.com/
- 1使用selenium模拟浏览器,定位到搜索框,输入ipad关键字,然后点击确定
- 2等待网页加载,获取网页代码
- 3解析网页源代码,获取商品信息写入文件
- 4以上流程结束,使用selenium定位到下一页的按钮,模拟点击
- 5等待网页加载,重复以上234,直到获取到所有的页面的商品信息
5.使用selenium模拟爬取流程中的12流程
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from lxml import etree
browser = webdriver.Chrome()
wait = WebDriverWait(browser, 10)
KEY_WORD = 'ipad'
# 流程1开始准备工作,获取到基础url,模拟浏览器输入ipad,点确定
def start_crawl():
try:
url = 'https://www.jd.com/'
browser.get(url)
# 根据CSS定位到输入搜索框
input = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '#key')))
# 根据CSS定位到确定按钮
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#search > div > div.form > button')))
type(input)
input[0].send_keys(KEY_WORD)
submit.click()
except TimeoutException:
print('start_crawl exception')
def next_page(page):
print("爬取第", page, "页")
try:
# 滑动到底部,不然页面只有30个商品信息
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)
# 加载完成,获取当前页的网页资源
html = browser.page_source
# todo 解析当前页
# todo 保存到文件
# 开始翻页 获取下一页的按钮
button = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em')))
button.click()
# 需要增加翻页成功的标示?
except TimeoutException:
print('next_page exception', page)6.解析商品信息
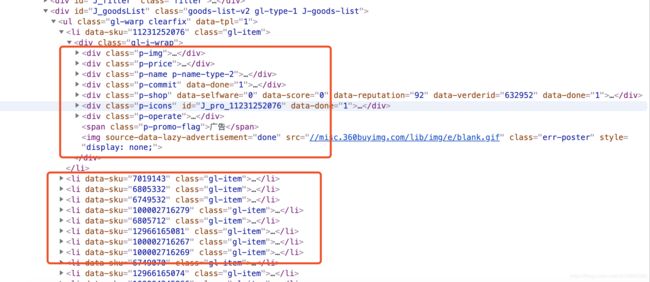
根据源码中商品信息的布局,解析商品的信息代码如下:
from lxml import etree
def parse_html(html):
html = etree.HTML(html)
# 获取所有样式是li class名是gl-item的html文件
items = html.xpath('//li[@class="gl-item"]')
for i in range(len(items)):
product = {}
# 标题是:div子孙节点 class名是p-name p-name-type-2 子孙节点em下的所有文本
product['title'] = html.xpath('//div[@class="p-name p-name-type-2"]//em')[i].xpath('string(.)')
# 价格是: div子孙节点 class名是p-price 子孙节点i下的文本
product['price'] = html.xpath('//div[@class="p-price"]//i')[i].text
# 评论是 div子孙节点 class是p-commit 子节点strong 子节点a下的文本
product['comment'] = html.xpath('//div[@class="p-commit"]/strong/a')[i].text
product['shop'] = html.xpath('//div[@class="p-shop"]//a')[i].text
yield product7.整体代码
# -*- coding: utf-8 -*-
# @Time : 2019-08-02 22:07
# @Author : xudong
# @email : [email protected]
# @Site :
# @File : jdSpider.py
# @Software: PyCharm
'''
jd的搜索页面,爬取关键字是ipad的商品信息
'''
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from lxml import etree
import json
import time
browser = webdriver.Chrome()
wait = WebDriverWait(browser, 10)
KEY_WORD = 'ipad'
# 流程1开始准备工作,获取到基础url,模拟浏览器输入ipad,点确定
def start_crawl():
try:
url = 'https://www.jd.com/'
browser.get(url)
# 根据CSS定位到输入搜索框
input = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '#key')))
# 根据CSS定位到确定按钮
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#search > div > div.form > button')))
type(input)
input[0].send_keys(KEY_WORD)
submit.click()
except TimeoutException:
print('start_crawl exception')
def get_total_page():
# 获取所有的页码数
total = wait.until(
EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, '#J_bottomPage > span.p-skip > em:nth-child(1) > b')
)
)
return total[0].text
# 加载当前页解析写入文件并获取下一页
def next_page(page):
print("爬取第", page, "页")
try:
# 滑动到底部,不然页面只有30个商品信息
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 一定要加time sleep不然网页加载不出来获取不到数据
time.sleep(5)
# 加载完成,获取当前页的网页资源
html = browser.page_source
# 解析当前页
results = parse_html(html)
# 保存到文件
write_file(results)
# 开始翻页 获取到下一页的按钮
button = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em')))
button.click()
# 需要增加翻页成功的标示?
except TimeoutException:
print('next_page exception', page)
# 解析网页
def parse_html(html):
html = etree.HTML(html)
# 获取所有样式是li class名是gl-item的html文件
items = html.xpath('//li[@class="gl-item"]')
for i in range(len(items)):
product = {}
# 标题是:div子孙节点 class名是p-name p-name-type-2 子孙节点em下的所有文本
product['title'] = html.xpath('//div[@class="p-name p-name-type-2"]//em')[i].xpath('string(.)')
# 价格是: div子孙节点 class名是p-price 子孙节点i下的文本
product['price'] = html.xpath('//div[@class="p-price"]//i')[i].text
# 评论是 div子孙节点 class是p-commit 子节点strong 子节点a下的文本
product['comment'] = html.xpath('//div[@class="p-commit"]/strong/a')[i].text
product['shop'] = html.xpath('//div[@class="p-shop"]//a')[i].text
yield product
# 写入文件
def write_file(results):
for result in results:
print(result)
json1 = json.dumps(result, ensure_ascii=False) + '\n'
with open('jd.txt', 'a', encoding='utf-8') as file:
file.write(json1)
if __name__ == '__main__':
start_crawl()
# 爬10页,可以利用get_total_page方法爬取所有页
for i in range(10):
next_page(i)
8.结果
如果控制台能够打印数据,并且结束后,对应文件中有jd.txt文件,文件中有如下的数据,即表示目标达成。
