Hadoop 原生分布式对象存储 Ozone

背景
HDFS是业界默认的大数据存储系统,在业界的大数据集群中有非常广泛的使用。HDFS集群有着很高的稳定性,得益于它较简单的构架,集群也很容易扩展。业界包含几千个数据节点,保存上百PB数据的集群也不鲜见。
HDFS通过把文件系统元数据全部加载到Namenode内存中,给客户端提供了低延迟的元数据访问。由于元数据需要全部加载到内存,所以一个HDFS集群能支持的最大文件数,受JAVA堆内存的限制,上限大概是4亿左右个文件。所以HDFS适合大量大文件(几百兆以上)的集群,如果集群中有非常多的小文件,HDFS的元数据访问性能会受到影响。虽然可以通过各种Federation技术来扩展集群的节点规模, 但单个HDFS集群仍然没法很好的解决小文件的限制。
基于这些背景,Hadoop 社区推出了新的分布式存储系统 Ozone,从构架上解决这个问题。
Ozone的设计原则
Ozone 由一群对大规模Hadoop集群有着丰富运维和管理经验的工程师和构架师设计和实现。他们对大数据有深刻的洞察力,清楚的了解HDFS的优缺点,这些洞察力自始自终影响了Ozone的设计和实现。Ozone的设计遵循一下原则,
强一致性
构架简洁性
当系统出现问题时,一个简单的架构更容易定位,也容易调试。Ozone尽可能的保持架构的简单,即使因此需要可扩展性上做一些妥协。但是在Ozone在扩展性上绝不逊色,目标是支持单集群1000亿个对象。
构架分层
Ozone采用分层的文件系统。Namespace 元数据的管理,数据块和节点的管理分开。用户可以对二者独立扩展。
容易恢复
HDFS一个关键优点是,它能经历大的灾难事件,比如集群级别的电力故障,而不丢失数据, 并且能高效的从灾难中恢复。对于一些小的故障,比如机架和节点级别的故障,更是不在话下。Ozone将继承HDFS的这些优点。
Apache开源
Apache社区开源对于Ozone的成功非常重要。所有Ozone的设计和实现都在社区中进行,接受社区所有人的Review。
和Hadoop生态的互操作性
Ozone可以被Hadoop生态中的应用,如 Apache Hive、Apache Spark 和 Mapreduce 无缝对接。Ozone支持Hadoop Compatible FileSystem API (aka OzoneFS)。通过OzoneFS, Hive,Spark等应用不需要做任何修改,就可以运行在Ozone上。Ozone同时支持Data Locality,使得计算能够尽可能的靠近数据。
语义
Ozone是一个分布式Key-value对象存储系统。Ozone提供给用户的语义包含Volume, Bucket 和Key。

Volume
类似于用户的Home目录,建议每个用户单独创建自己的Volume。Volume只有系统管理员才可以创建,是存储管理的单位,比如配额管理。Volume用来存储Bucket,一个Volume下面可以包含任意多个Bucket。
Bucket
Bucket 下存储 Key 和 Value。Bucket 的概念类似于 S3 的 Bucket,或者 Azure 中的 Container。Bucket 由 ACL 来控制访问。
Key
每个 Key 在 Bucket 中必须唯一,可以是任意字符串。用户的数据以 Key-value 的形式存储在 Bucket 下。
Ozone URL
Ozone URL 采用如下格式:
[scheme][server:port]/volume/bucket/key
其中,Scheme可以选
a) o3 - 通过 RPC 协议访问 Ozone Manager 和 Datanodes
b) http/https - 通过 HTTP 协议访问 REST API
Scheme可以省略,这种情况下默认使用RPC协议。Server:Port 是 Ozone Manager 的地址。如果没有指定,则用定义在 ozone-site.xml 中 "ozone.om.address" 默认值。
构架
Ozone 从结构上分为三个部分,Ozone Manager, 元数据管理;Storage Container Manager, 数据块和节点管理;Datanode, 数据最终的存放处。类比 HDFS 的构架, 可以看到原来 Namenode 的功能,现在由 Ozone Manager 和 Storage Container Manage 分别进行管理了。接下来,我们仔细看一下 Ozone 主要模块和概念。

Ozone构架
Ozone Manager
管理 Ozone 的 Namespace,提供所有的 Volume, Bucket 和 Key 的新建,更新和删除操作。存储了 Ozone 的元数据信息,这些元数据信息包括 Volumes、Buckets 和 Keys,底层通过 Ratis(实现了Raft协议) 扩展元数据的副本数来实现 元数据的 HA。Ozone Manager 只和 Ozone Client 和 Storage Container Manager 通信,并不直接和 Datanode 通信。
Storage Container Manager(SCM)
类似HDFS中的Block Manager,管理 Container, Pipelines 和 Datanode,为 Ozone Manager 提供Block 和 Container 的操作和信息。SCM也监听 Datanode 发来的心跳信息,作为Datanode manager的角色, 保证和维护集群所需的数据冗余级别。SCM 和 Ozone Client 之间没有通信。
Block,Container 和 Pipeline
Block 是数据块对象,真实存储用户的数据。Container是一个逻辑概念,是由一些相互之间没有关系的 Block 组成的集合。在 Ozone 中, 数据是以 Container 的粒度进行副本复制的。Pipeline 来保证 Container 实现想要的副本数。SCM 中目前支持2种 Pipeline 方式实现多副本,单副本的 Standalone 模式和三副本的 Ratis 方式。Container 有2种状态,OPEN 和 CLOSED。当一个Container 是 OPEN 状态时,可以往里边写入新的 BLOCK。当一个Container 达到它预定的大小时(默认5GB),它从 OPEN 状态转换成 CLOSED 状态。一个 Closed Container 是不可修改的。

Container 内部结构

Ratis 写 Pipeline
Datanode
Datanode 是 Ozone 的数据节点,以 Container 为基本存储单元,维护每个 Container 内部的数据映射关系,定时向 SCM 发送心跳节点,汇报节点的信息,管理的 Container 的信息,Pipeline 的信息。当一个 Container Size 超过预定的大小 90% 时 或者写操作失败时,Datanode 会发送 Container Close 命令给 SCM,把 Container 的状态从 Open 转变成 Closed。或者当Pipeline 出错时,发送 Pipeline Close 命令给SCM,把Pipeline 从 Open 状态转为 Closed 状态。
Ozone 分层的构架结构,使得Ozone Manager,Storage Container Manager 和 Datanode 按需独立扩展。对于Ozone 提供的语义,也是由各层分层管理的,
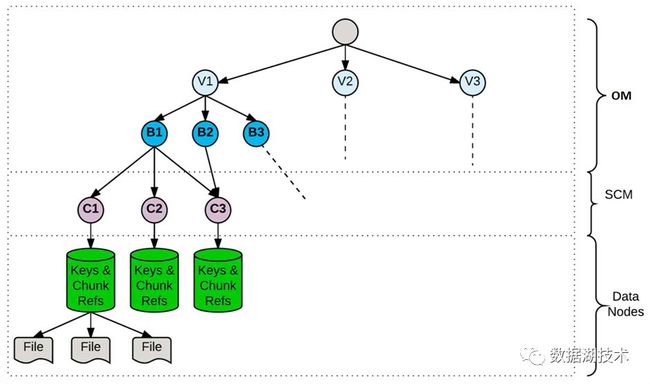
Ozone 语义和管理模块
读写过程
写过程
Ozone 客户端 先和 Ozone Manager 通信,提供需要创建的Key 的信息,包括 /volume/bucket/key,数据的大小,备份数,和其他用户自定义Key的属性。Ozone Manager 收到 Ozone 客户端的请求后,调用SCM 的服务,寻找足够容纳数据的Open Container,将Container 对应的Pipeline 的Datanode 列表信息返回给Ozone Manager。Ozone Manager 返回对应的信息给客户端。
客户端拿到Datanode列表信息之后,和第一个Datanode(Raft Leader)建立通信,将数据写入Datanode 的Container 中,更新Container 的元数据,记录新增加的这个数据块。
最后,客户端再和Ozone Manager 通信,告知数据已经成功的在 Datanode写入了。Ozone 修改 Namspace 元数据,记录一个新生成的Key。之后,其他的客户端就可以访问这个Key了。

创建一个新 Key
读过程
读的过程相对简单,类似于HDFS的文件读。Ozone 客户端 先和 Ozone Manager 通信,告知需要读取的Key 的信息(/volume/bucket/key)。Ozone Manager 在元数据库中查找对应的Key,返回 Key 数据所在的 Datanode 列表给Ozone 客户端。Ozone 支持Data locality。如果Ozone 客户端运行在集群中的某个节点上,Ozone Manager 会返回按照网络拓扑距离排序的Datanode列表。当 Ozone 客户端拿到 Key 的信息之后,可以选择第一个Datanode 节点(一本地节点),也是离客户端最近的节点来读取数据,节省数据读取的时间。

读取一个Key
和Hadoop 生态的结合
Ozone 同时支持 Hadoop 2.x 和 Hadoop 3.x 集群,能够和运行其上的Hive,Spark 等应用无缝集成。
结束语
Apache Ozone 是一个开发迭代非常活跃的社区,在 2018 年发布了版本 0.2.1 和 0.3.0,支持 OzoneFS, YARN, HIVE and Spark on OzoneFS, S3 协议接口。2019年发布了版本0.4.0,0.4.1 和0.4.2,支持基于Kerbero的认证,透明数据加密/解密,支持Ranger,实现CNCF CSI 插件支持Kubernetes布署。2020年0.5.0 的发布正在进行中。Ozone 社区提供Docker-Compose脚本,帮助初次使用者很方便的布署单集群,尝试Ozone的各种功能。更多文档的信息,请参考Apache Ozone官网和对应的Github开源项目。
参考文档
https://hortonworks.com/blog/introducing-apache-hadoop-ozone-object-store-apache-hadoop/
https://hortonworks.com/blog/apache-hadoop-ozone-object-store-architecture/
猜你喜欢
1、NVIDIA 与数砖合作,将 GPU 加速带入 Apache Spark 3.0
2、恭喜,Apache Hudi 即将成为顶级项目!
3、MongoDB Spark Connector 实战指南
4、Apache Kafka 不需要管理员:删除 Apache ZooKeeper 的依赖

过往记忆大数据微信群,请添加微信:fangzhen0219,备注【进群】