实现自定义Spark优化规则
文章目录
- Catalyst optimizer
- 实战编写一个优化规则
- 编写优化规则
- 注册优化规则
- 测试结果
- 添加钩子和扩展点功能
- 编写自定义优化规则和扩展点
- 配置并启用自定义Spark扩展
- 测试优化规则
- 参考文档
Catalyst optimizer
Spark SQL 使用一个叫 catalyst 的优化器对所有使用 spark sql 和 dataframe dsl的查询进行优化。经过优化的查询会比使用RDD直接编写的程序运行更快。catalyst 是 rule based 优化器,内部提供了很多优化规则,这些内部优化规则后续有时间再做具体的详细介绍,我们今天主要来讨论一下如何在不修改源码的情况下,以插件的方式来编写和应用我们自定义的优化规则。
实战编写一个优化规则
我们这里做一个简单的优化规则,实现功能:如果我们select 的一个数值类型的字段去乘以 1.0 这个字符串,我们把这个乘法计算给优化掉。
编写优化规则
import org.apache.spark.internal.Logging
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
import org.apache.spark.sql.catalyst.rules.Rule
import org.apache.spark.sql.catalyst.expressions._
object MultiplyOptimizationRule extends Rule[LogicalPlan] with Logging {
def apply(plan: LogicalPlan): LogicalPlan = plan transformAllExpressions {
case Multiply(left,right) if right.isInstanceOf[Literal] &&
right.asInstanceOf[Literal].value.asInstanceOf[Double] == 1.0 =>
logInfo("MyRule 优化规则生效")
left
}
}
注册优化规则
通过spark提供的接口来注册我们编写好的优化规则
spark.experimental.extraOptimizations = Seq(MultiplyOptimizationRule)
测试结果
我们在命令行中测试一下,我们可以看到 Project 选择的字段中,(cast(id#7L as double) * 1.0) AS id2#12 已经被优化为 cast(id#7L as double) AS id2#14
scala> val df = spark.range(10).selectExpr("id", "concat('wankun-',id) as name")
df: org.apache.spark.sql.DataFrame = [id: bigint, name: string]
scala> val multipliedDF = df.selectExpr("id * cast(1.0 as double) as id2")
multipliedDF: org.apache.spark.sql.DataFrame = [id2: double]
scala> println(multipliedDF.queryExecution.optimizedPlan.numberedTreeString)
00 Project [(cast(id#7L as double) * 1.0) AS id2#12]
01 +- Range (0, 10, step=1, splits=Some(1))
import org.apache.spark.internal.Logging
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
import org.apache.spark.sql.catalyst.rules.Rule
import org.apache.spark.sql.catalyst.expressions._
object MultiplyOptimizationRule extends Rule[LogicalPlan] with Logging {
def apply(plan: LogicalPlan): LogicalPlan = plan transformAllExpressions {
case Multiply(left,right) if right.isInstanceOf[Literal] &&
right.asInstanceOf[Literal].value.asInstanceOf[Double] == 1.0 =>
logInfo("MyRule 优化规则生效")
left
}
}
scala> spark.experimental.extraOptimizations = Seq(MultiplyOptimizationRule)
spark.experimental.extraOptimizations: Seq[org.apache.spark.sql.catalyst.rules.Rule[org.apache.spark.sql.catalyst.plans.logical.LogicalPlan]] = List(MultiplyOptimizationRule$@675d209c)
scala>
scala> val multipliedDFWithOptimization = df.selectExpr("id * cast(1.0 as double) as id2")
multipliedDFWithOptimization: org.apache.spark.sql.DataFrame = [id2: double]
scala> println(multipliedDFWithOptimization.queryExecution.optimizedPlan.numberedTreeString)
00 Project [cast(id#7L as double) AS id2#14]
01 +- Range (0, 10, step=1, splits=Some(1))
添加钩子和扩展点功能
通过上面的实例,我们通过spark提供的接口编程,可以实现来添加我们自定义的优化规则。
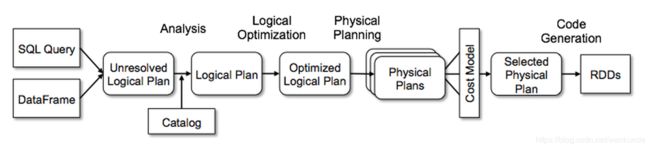
但是我们的spark-sql工具并不能允许我们进行直接编程添加规则,另外,catalyst 内部还有 Analysis, Logical Optimization, Physical Planning 多个阶段,如果我们想在这些地方做一个功能扩展,就不方便了。所以在Spark 2.2 版本又引入了一个更加强大的特性,添加钩子和扩展点。
编写自定义优化规则和扩展点
还是以实现功能的功能为例:
package com.wankun.sql.optimizer
import org.apache.spark.internal.Logging
import org.apache.spark.sql.catalyst.expressions.{Literal, Multiply}
import org.apache.spark.sql.{SparkSession, SparkSessionExtensions}
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
import org.apache.spark.sql.catalyst.rules.Rule
import org.apache.spark.sql.types.Decimal
/**
* @author kun.wan
* @date 2020-03-03.
*/
case class MyRule(spark: SparkSession) extends Rule[LogicalPlan] with Logging {
override def apply(plan: LogicalPlan): LogicalPlan = {
logInfo("开始应用 MyRule 优化规则")
plan transformAllExpressions {
case Multiply(left, right) if right.isInstanceOf[Literal] &&
right.asInstanceOf[Literal].value.isInstanceOf[Decimal] &&
right.asInstanceOf[Literal].value.asInstanceOf[Decimal].toDouble == 1.0 =>
logInfo("MyRule 优化规则生效")
left
}
}
}
class MyExtensions extends (SparkSessionExtensions => Unit) with Logging {
def apply(e: SparkSessionExtensions): Unit = {
logInfo("进入MyExtensions扩展点")
e.injectResolutionRule(MyRule)
}
}
将上述代码打包为 spark-extensions-1.0.jar
配置并启用自定义Spark扩展
spark-sql --master local --conf spark.sql.extensions=com.wankun.sql.optimizer.MyExtensions --jars /Users/wankun/ws/wankun/spark-extensions/target/spark-extensions-1.0.jar
测试优化规则
可以看到 plan 被 Analyzed 之后,乘法运算消失,已经自定义优化规则已经生效。
spark-sql> explain extended
> with stu as (
> select 1 as id, 'wankun-1' as name
> union
> select 2 as id, 'wankun-2' as name
> union
> select 3 as id, 'wankun-3' as name
> )
> select id * 1.0
> from stu;
20/03/04 01:56:16 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) 开始应用 MyRule 优化规则
20/03/04 01:56:17 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) 开始应用 MyRule 优化规则
20/03/04 01:56:17 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) 开始应用 MyRule 优化规则
20/03/04 01:56:17 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) MyRule 优化规则生效
20/03/04 01:56:17 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) 开始应用 MyRule 优化规则
20/03/04 01:56:17 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) 开始应用 MyRule 优化规则
20/03/04 01:56:17 INFO MyRule: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) 开始应用 MyRule 优化规则
20/03/04 01:56:18 INFO CodeGenerator: org.apache.spark.internal.Logging$class.logInfo(Logging.scala:54) Code generated in 156.862003 ms
== Parsed Logical Plan ==
CTE [stu]
: +- SubqueryAlias `stu`
: +- Distinct
: +- Union
: :- Distinct
: : +- Union
: : :- Project [1 AS id#0, wankun-1 AS name#1]
: : : +- OneRowRelation
: : +- Project [2 AS id#2, wankun-2 AS name#3]
: : +- OneRowRelation
: +- Project [3 AS id#4, wankun-3 AS name#5]
: +- OneRowRelation
+- 'Project [unresolvedalias(('id * 1.0), None)]
+- 'UnresolvedRelation `stu`
== Analyzed Logical Plan ==
id: decimal(10,0)
Project [cast(id#0 as decimal(10,0)) AS id#8]
+- SubqueryAlias `stu`
+- Distinct
+- Union
:- Distinct
: +- Union
: :- Project [1 AS id#0, wankun-1 AS name#1]
: : +- OneRowRelation
: +- Project [2 AS id#2, wankun-2 AS name#3]
: +- OneRowRelation
+- Project [3 AS id#4, wankun-3 AS name#5]
+- OneRowRelation
== Optimized Logical Plan ==
Aggregate [id#0, name#1], [cast(id#0 as decimal(10,0)) AS id#8]
+- Union
:- Project [1 AS id#0, wankun-1 AS name#1]
: +- OneRowRelation
:- Project [2 AS id#2, wankun-2 AS name#3]
: +- OneRowRelation
+- Project [3 AS id#4, wankun-3 AS name#5]
+- OneRowRelation
== Physical Plan ==
*(5) HashAggregate(keys=[id#0, name#1], functions=[], output=[id#8])
+- Exchange hashpartitioning(id#0, name#1, 200)
+- *(4) HashAggregate(keys=[id#0, name#1], functions=[], output=[id#0, name#1])
+- Union
:- *(1) Project [1 AS id#0, wankun-1 AS name#1]
: +- Scan OneRowRelation[]
:- *(2) Project [2 AS id#2, wankun-2 AS name#3]
: +- Scan OneRowRelation[]
+- *(3) Project [3 AS id#4, wankun-3 AS name#5]
+- Scan OneRowRelation[]
Time taken: 1.945 seconds, Fetched 1 row(s)
sparkSession 中给用户留了扩展点,Spark catalyst的扩展点在SPARK-18127中被引入,Spark用户可以在SQL处理的各个阶段扩展自定义实现,非常强大高效
- injectOptimizerRule – 添加optimizer自定义规则,optimizer负责逻辑执行计划的优化,我们例子中就是扩展了逻辑优化规则。
- injectParser – 添加parser自定义规则,parser负责SQL解析。
- injectPlannerStrategy – 添加planner strategy自定义规则,planner负责物理执行计划的生成。
- injectResolutionRule – 添加Analyzer自定义规则到Resolution阶段,analyzer负责逻辑执行计划生成。
- injectPostHocResolutionRule – 添加Analyzer自定义规则到Post Resolution阶段。
- injectCheckRule – 添加Analyzer自定义Check规则。
参考文档
- Catalyst: Allow adding custom optimizers
- Add hooks and extension points to Spark
- How to Extend Apache Spark with Customized Optimizations
- Introduction to Spark 2.0 - Part 6 : Custom Optimizers in Spark SQL
- 理解spark sql 优化策略的最好方法就是自己实现一个