为什么80%的码农都做不了架构师?>>> 
使用类、函数,对代码优化:
# -*- coding: utf-8 -*-
# Python3.5爬取豆瓣top250
import time
import requests
from bs4 import BeautifulSoup
import xlsxwriter
class DouBan(object):
def __init__(self):
self.movie_rating = []
self.movie_name = []
self.movie_score = []
self.url_list = []
self.base_url = 'https://movie.douban.com/top250?start={0}&filter='
self.headers = {
'User-Agent': '(Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36)',
}
# 获取页面内容
def get_html(self, url):
try:
response = requests.get(url, headers=self.headers)
html = response.text
return html
except Exception as e:
print(e)
return None
def get_data(self):
try:
for k in range(0, 250, 25):
url = self.base_url.format(k)
html = self.get_html(url)
soup = BeautifulSoup(html, 'html.parser')
span_rating_list = soup.findAll('em', attrs={'class': ''}) # 解析需要的参数
span_name_list = soup.findAll('span', attrs={'class': 'title'})
span_score_list = soup.findAll('span', attrs={'class': 'rating_num'})
for span_rating in span_rating_list: # 电影排名
span_rating = span_rating.string
self.movie_rating.append(span_rating)
# print(movie_rating)
for span_name in span_name_list: # 电影名称
span_name = span_name.string
if span_name.find('/') == -1:
span_name = span_name
self.movie_name.append(span_name)
# print(movie_name)
for span_score in span_score_list: # 电影评分
span_score = span_score.string
self.movie_score.append(span_score)
# print(movie_score)
data_list = []
data_list.append(self.movie_rating)
data_list.append(self.movie_name)
data_list.append(self.movie_score)
return data_list
except Exception as e:
print(e)
return None
def excel_data(self, data_list):
try:
workbook = xlsxwriter.Workbook('豆瓣top250.xlsx')
worksheet = workbook.add_worksheet('豆瓣top250数据分析')
bold = workbook.add_format({'bold': True})
col = ('排名', '电影名称', '评分', '读取时间')
tsp = time.strftime('%Y%m%d %H:%M:%S', time.localtime())
for v in range(0, 4):
worksheet.write(0, v, col[v], bold) # i写入列名
worksheet.write(1, 3, tsp)
for i in range(0, 250):
for j in range(0, 3):
worksheet.write(i + 1, j, data_list[j][i])
worksheet.write(i + 1, j, data_list[j][i])
worksheet.write(i + 1, j, data_list[j][i])
worksheet.set_column(i, 1, 20) # 设置第二列列宽为20
workbook.close()
print('数据已保存到豆瓣top250.xlsx')
except Exception as e:
print(e)
def run(self):
print("正在爬取豆瓣top250的数据,请耐心等待。。。")
self.get_data()
data_list = self.get_data()
self.excel_data(data_list)
if __name__ == '__main__':
spider = DouBan()
spider.run()
运行结果:

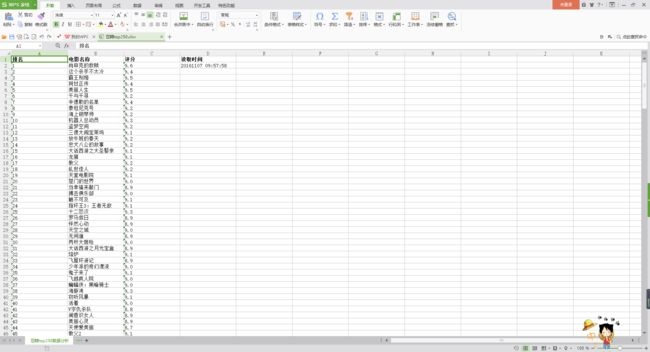
Excel保存的数据: