本文是CVPR17年的文章,微软和中科大合作的作品,事实上本文与低剂量CT重建并不是同样的任务,但是文中的APN和检测网络接连作用的模式值得学习。
文章是针对细粒度特征学习所做,文章提出一种RA-CNN(recurrent attention convolutional neural network),在每个规模的图像下都有两个网络分类网和APN(attention proposal sub-network),从大尺度图像开始迭代至精细部分,相互学习完成细粒度的目标。实验显示本文所提出的RA-CNN在三项细粒度项目里达到最好结果。
传统的细粒度识别一般包括两个步骤:1)以非监督方式通过分析来自神经网络的卷积响应或通过使用监督的边界框/部分来识别可能的目标区域注释,2)从每个区域提取区别性特征并将它们编码成紧凑型载体以供识别。但传统的方法存在很大的问题,就是人为标定或者机器学习的区域不一定是机器学习的最佳结果。而且作者发现了区域检测和细粒度特征学习是互相关联,因此可以相互补充,由此作者提出了RA-CNN。
针对细粒度图像识别问题研究一般从两个方向展开:判别特征学习和复杂部位定位。本文框架如下图所示:

a1是一开始输入的全局图像,然后到b1共享卷积层,接着分两路一个到分类网络得到此步分类结果,另一路经过APN的位置信息结合a1得到局部区域图像;a2、a3过程和a1相同,只是在更精细的局部区域进行。模型在每一步骤到分类损失和相邻尺度上的排序损失下学习。
APN:文中所说的multi-task指的是每一个scale图像下的分类网络和APN网络两个task,task1分类网络可以用下述公式描述,X是输入图像,WC是网络参数,*表示卷积过程:
而task2的作用是产生局部区域的位置参数,一个正方形区域的三个参数,表示如下:
其中tx,ty分别表示以x和y轴为单位的正方形中心坐标,tl表示正方形边长的一半。假设原始图像的左上角是坐标系的起点,用符号tl表示左上角这个点,用符号br表示右下角这个点,那么根据APN网络得到的tx、ty和tl可计算得到crop得到的区域的左上角点和右下角点的x轴(tx(tl)、tx(br))和y轴(ty(tl)、ty(br))坐标分别如下式所示:

也就是图像crop过程可以通过原始图像和APN得到:
上式中MASK部分公式是:
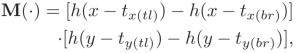
其中h(.)是系数为k(很大的正整数)是sigmod函数:
针对这个h函数因为k比较大,所以就相当于一个阶跃函数,当x>0时为1,否则为0。
那么在M函数里,就只有当x在tx(tl)和tx(br)之间且y在ty(tl)和ty(br)之间时,M函数才趋于1*1=1,其余都为0。这就使得一个0-1问题连续化,可以进行end 2 end训练。这一点也是本文的一个精妙之处。
确定了裁剪区域之后就要对该区域进行放大,文中所用是双线性插值:
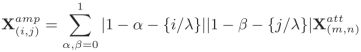
损失函数前面已经说过,有两部分组成,每个scale下的分类损失,和相邻scale下的排序损失,如下式:
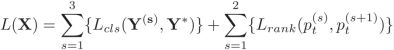
前一部分是分类损失,Y(s)表示预测的类别概率,Y*表示真实类别,后一部分排序损失具体算法是:
输入中pt(s)中的t表示真实标签类别,s表示scale,从Lrank损失函数可以看出,当更后面的scale网络的pt大于相邻的前面的scale网络的pt时,损失较小,也就是模型的训练目标是希望更后面的scale网络的预测更准。margin参数在实验中设置为0.05。
最终不同scale下的网络就可以得到不同的输出:
然后将这些输出连接在一起形成具有softmax函数的完全连接的融合层,用于最终分类。
训练策略分为三个步骤:1)用ImageNet预训练的VGG初始化网络里的特征提取和分类部分;2)通过APN产生的tx,ty,tl获得下一个scale的图像继续学习;3)轮流训练分类损失和APN参数,每个尺度的tl被限制为不小于前一个tl的粗尺度的三分之一,以避免当tl太小时物体结构的不完整性。
APN的梯度更新:通过tx,ty,tl上的导数来展示APN的机制,以tx为例,导数通过反向传播的链式法则求得,如下式:
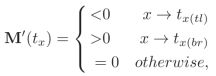
当导数小于0时,tx增加,否则减小,过程图如下,第一行的两个图分别表示两个不同scale网络的输入,第二行表示在训练网络时回传的梯度值分布情况,箭头就是表示梯度的更新方向,比如右下角图中的tx和ty的更新方向是趋于输入图像的右下角区域,tl的更新方向是变得更大。

实验:
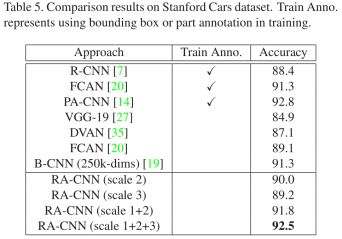
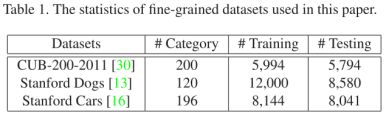
作者在三个细粒度数据集上进行了实验,Caltech-UCSD Birds (CUB-200-2011) , Stanford Dogs and Stanford Cars。结果如下表所示:
在CUB-200-2011数据集上关于attention localization的效果对比:

在CUB-200-2011数据集上几个算法的结果对比:
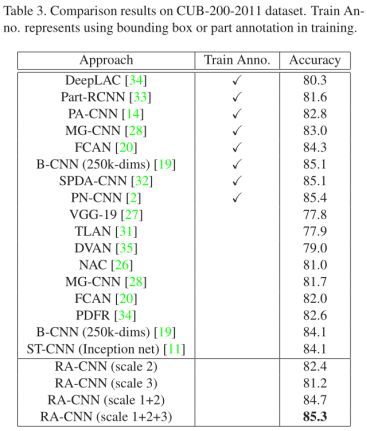
可以看出RA-CNN的效果基本上和细粒度分类中最优秀的监督式算法的效果差不多。另外和其他非监督式算法相比,即便是B-CNN采用了超高的维度,ST-CNN采用了更好的主网络(Inception),RA-CNN的效果也要好很多。其他方面,从RA-CNN不同scale的对比可以看出,scale 2的效果要优于scale 1和scale 3,前者是因为关键区域的定位起了效果,后者是因为丢失了部分全局信息。在Stanford Dogs数据集上的对比结果如Table4所示:

在Stanford Cars数据集上的对比结果: