Ambari在不升级情况下整合高版本spark2.x框架
一.背景介绍
大家都知道spark在2.x之后实现了一系列更方便快捷的改进,spark目前社区已经更新到了2.3.1版本,笔者发现spark在2.2.x版本之后,对于spark-ml的功能有显著增强。而笔者用的大数据实验环境是基于Ambari搭建的,版本为2.2.2,对应采用的HDP的版本为2.4.x。笔者杯具的发现,这个版本对于spark2.x还不能完全支持,自然就无法使用spark2.x以后带来的各方面功能提升了。那么问题来了,该如何将spark高版本的框架整合进ambari呢?
二.整合方案
1.方案1:ambari与HDP双向升级
一种方法自然是升级ambari本身的版本到2.4后(最新已经到2.6.x版本),这种大升级情况需要谨慎操作,建议完全参照hortonworks document上面的官方文档进行,否在可能导致集群崩盘。同时由于依赖需要科学上网,所以建议建立本地repos源进行升级操作。部分版本过低的用户可能需要二连跳操作(先升级到2.2,再升级到更高版本)。整体升级的方案略提一下,不作为重点介绍,下面介绍一下更为安全的在不升级的情况下整合ambari与spark2.x框架。
2.方案2:ambari与spark2.x不升级整合
1.spark版本根据ambari集群的hadoop版本重新编译后,解压到集群的某节点上(一个或者多个,无需太多,根据实际提交任务的节点约束)。笔者自己编译的版本为spark-2.2.0-bin-hadoop2.7。
2.修改spark-env.sh文件,加入如下内容:注意HDP版本的HADOOP_CONF_DIR区别与apache版本以及CDH版本,为对应版本号下面的/hadoop/conf文件夹,而非/etc/hadoop
*JAVA_HOME
export JAVA_HOME=/usr/local/app/jdk1.8.0_144
*HADOOP_CONF_DIR
export HADOOP_CONF_DIR=/usr/hdp/2.4.2.0-258/hadoop/conf3.分别拷贝core-site.xml与hdfs-site.xml到spark的conf目录下,如果需要整合spark与已有hive或者将hive作为外部数据源使用spark-sql,还需将hive-site.xml文件拷贝进conf目录。
4.解决jersey包版本冲突问题:集群hadoop-yarn的jersey依赖包版本低于spark的对应的包版本,所以这里必须将spark的相关依赖包替换成hadoop对应版本的。具体为将/usr/hdp/2.4.2.0-258/hadoop-yarn/lib目录下的jersey-core-1.9.jar、jersey-client-1.9.jar这两个依赖包拷贝到spark的lib目录下,同时将spark的lib目录下对应的高版本包去掉,修改后的spark的lib目录如下图:

5.经过以上四步,spark已经可以在ambari上面以local、standalone、yarn的client模式提交运行任务,但是以yarn的cluster mode执行任务时,会出现如下报错:
18/07/21 20:55:40 INFO yarn.Client: Application report for application_1531149311507_0180 (state: ACCEPTED)
18/07/21 20:55:41 INFO yarn.Client: Application report for application_1531149311507_0180 (state: ACCEPTED)
18/07/21 20:55:42 INFO yarn.Client: Application report for application_1531149311507_0180 (state: ACCEPTED)
18/07/21 20:55:43 INFO yarn.Client: Application report for application_1531149311507_0180 (state: FAILED)
18/07/21 20:55:43 INFO yarn.Client:
client token: N/A
diagnostics: Application application_1531149311507_0180 failed 2 times due to AM Container for appattempt_1531149311507_0180_000002 exited with exitCode: 1
For more detailed output, check application tracking page:http://bdp03.szmg.com.cn:8088/cluster/app/application_1531149311507_0180Then, click on links to logs of each attempt.
Diagnostics: Exception from container-launch.
Container id: container_e22_1531149311507_0180_02_000001
Exit code: 1
Exception message: /hadoop/yarn/local/usercache/root/appcache/application_1531149311507_0180/container_e22_1531149311507_0180_02_000001/launch_container.sh: line 22: $PWD:$PWD/__spark_conf__:$PWD/__spark_libs__/*:$HADOOP_CONF_DIR:/usr/hdp/current/hadoop-client/*:/usr/hdp/current/hadoop-client/lib/*:/usr/hdp/current/hadoop-hdfs-client/*:/usr/hdp/current/hadoop-hdfs-client/lib/*:/usr/hdp/current/hadoop-yarn-client/*:/usr/hdp/current/hadoop-yarn-client/lib/*:$PWD/mr-framework/hadoop/share/hadoop/mapreduce/*:$PWD/mr-framework/hadoop/share/hadoop/mapreduce/lib/*:$PWD/mr-framework/hadoop/share/hadoop/common/*:$PWD/mr-framework/hadoop/share/hadoop/common/lib/*:$PWD/mr-framework/hadoop/share/hadoop/yarn/*:$PWD/mr-framework/hadoop/share/hadoop/yarn/lib/*:$PWD/mr-framework/hadoop/share/hadoop/hdfs/*:$PWD/mr-framework/hadoop/share/hadoop/hdfs/lib/*:$PWD/mr-framework/hadoop/share/hadoop/tools/lib/*:/usr/hdp/${hdp.version}/hadoop/lib/hadoop-lzo-0.6.0.${hdp.version}.jar:/etc/hadoop/conf/secure: bad substitution
Stack trace: ExitCodeException exitCode=1: /hadoop/yarn/local/usercache/root/appcache/application_1531149311507_0180/container_e22_1531149311507_0180_02_000001/launch_container.sh: line 22: $PWD:$PWD/__spark_conf__:$PWD/__spark_libs__/*:$HADOOP_CONF_DIR:/usr/hdp/current/hadoop-client/*:/usr/hdp/current/hadoop-client/lib/*:/usr/hdp/current/hadoop-hdfs-client/*:/usr/hdp/current/hadoop-hdfs-client/lib/*:/usr/hdp/current/hadoop-yarn-client/*:/usr/hdp/current/hadoop-yarn-client/lib/*:$PWD/mr-framework/hadoop/share/hadoop/mapreduce/*:$PWD/mr-framework/hadoop/share/hadoop/mapreduce/lib/*:$PWD/mr-framework/hadoop/share/hadoop/common/*:$PWD/mr-framework/hadoop/share/hadoop/common/lib/*:$PWD/mr-framework/hadoop/share/hadoop/yarn/*:$PWD/mr-framework/hadoop/share/hadoop/yarn/lib/*:$PWD/mr-framework/hadoop/share/hadoop/hdfs/*:$PWD/mr-framework/hadoop/share/hadoop/hdfs/lib/*:$PWD/mr-framework/hadoop/share/hadoop/tools/lib/*:/usr/hdp/${hdp.version}/hadoop/lib/hadoop-lzo-0.6.0.${hdp.version}.jar:/etc/hadoop/conf/secure: bad substitution
at org.apache.hadoop.util.Shell.runCommand(Shell.java:576)
at org.apache.hadoop.util.Shell.run(Shell.java:487)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:753)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:212)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:303)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
查看yarn日志,定位到问题出现在如下语句:找不到类
Error: Could not find or load main class org.apache.spark.deploy.yarn.ApplicationMaster解决办法:
1)在spark的conf文件下spark-default.xml 增加对于HDP版本的支持
spark.driver.extraJavaOptions -Dhdp.version=2.4.2.0-258
spark.yarn.am.extraJavaOptions -Dhdp.version=2.4.2.0-258
注意这里的版本号2.4.2.0-258就是/usr/hdp下面的对应文件夹名,而非执行hadoop version的对应hadoop版本号!
2)在HADOOP_CONF_DIR下面的mapred-site.xml 文件夹中使用当前版本替换hdp.version信息,使用sid批量替换:
sed -i 's/${hdp.version}/2.4.2.0-258/g' mapred-site.xml三.总结
编写一个wordcount程序测试spark on yarn cluster模式:
/usr/local/app/spark-2.2.0-bin-hadoop2.7/bin/spark-submit \
--class com.szmg.SparkWordCount \
--master yarn \
--deploy-mode cluster \
--driver-memory 2G \
--num-executors 4 \
--executor-memory 4G \
--executor-cores 5 \
--conf spark.app.coalesce=1 \
/usr/local/app/spark_test_projects/word_count/jar/scalaProject.jar \
/testdata/README.md \
/testdata/output2
提交到yarn上面执行:成功!
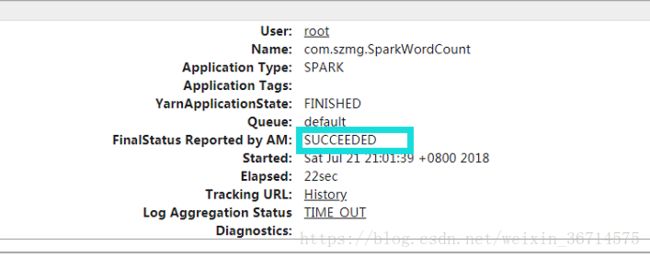
至此,实现了ambari与任意版本高版本spark的兼容,笔者测试了spark2.2.x与spark2.3.x,都成功实现了spark on yarn cluster的模式,从而实现了ambari集群对于不同版本spark的支持。