Hadoop的核心组件——MR
# Hadoop的核心组件——MR
## 一、MapReduce(MR)的概述
[TOC]
### 1.MapReduce的介绍
- Hadoop的分布式计算框架(MapReduce)
- MapReduce是分布式计算框架的一种,适合做离线计算框架;Strom适合做流式计算框架,更加适合做实时计算框架,stark是内存计算框架,适合做快速得到结果的计算
### 2.MapReduce的计算理念
- 何为分布式计算
- 移动计算,而不是移动数据(就是分析计算的程序分别拷贝一份到不同的机器上,但是数据不移动)
### 3.计算框架MR
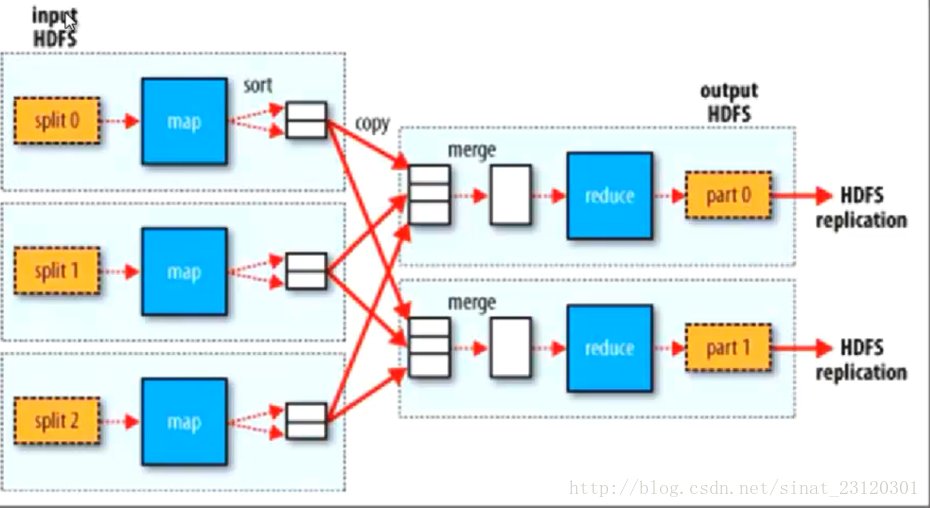
1. 从HDFS上存储的数据作为数据的输入,并且进行处理,成为一个个的split(片段)
2. 每一个片段由一个MAP线程去执行(并发的去执行)
3. 从map的执行结束到reduce的执行之前都是Shuffling
4. 然后就是Reduce进行执行。执行后的数据保存在HDFS中的
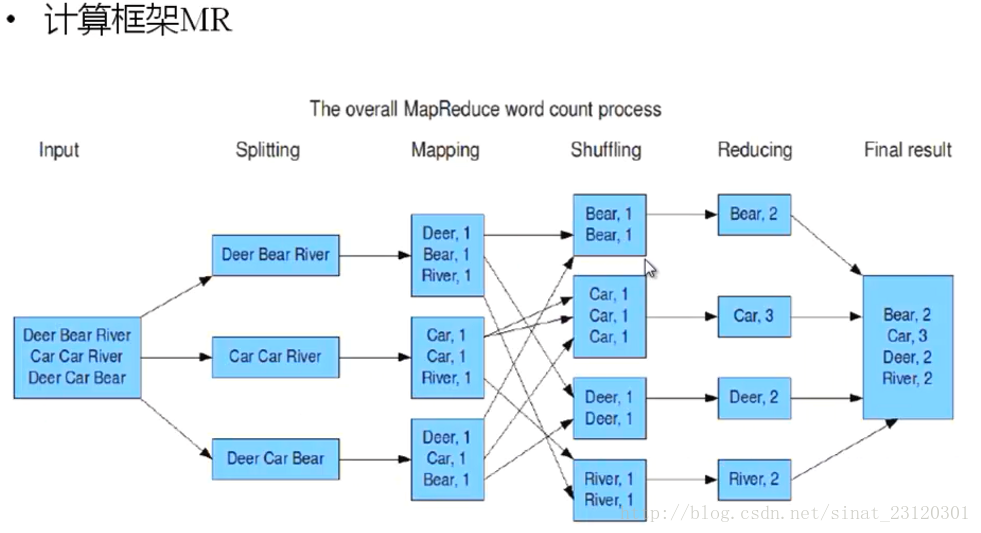
### 4.Hadoop计算框架Shuffler
- 在mapper和reduce中间的一个步骤
- 可以把mapper的输出按照某种key值重新切分和组合成n份,把key值符合某种范围的输出送到特定的reducer那里去
- 可以简化reducer的过程
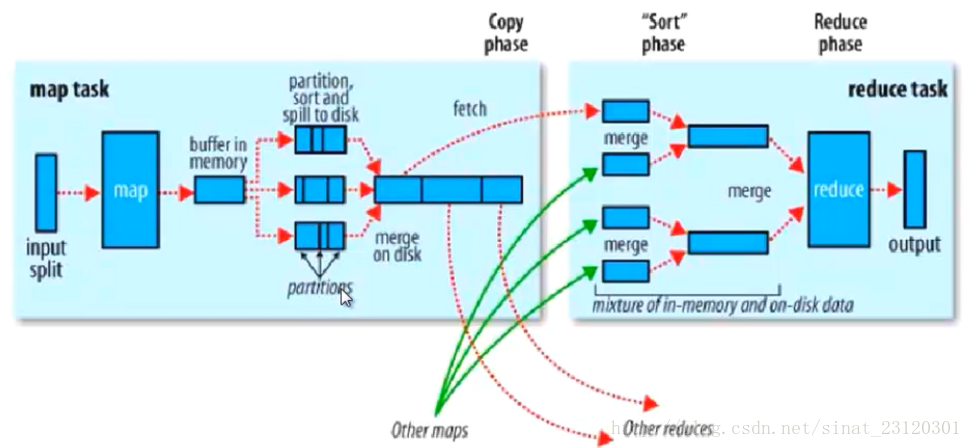
- map是一段java程序,输出的结果在内存中,内存有一定的阈值,当到达阈值后,溢写到磁盘中
- map的输出首先进行partition(分区)。然后进行sort(排序),spill to disk溢写到磁盘
- 当前的操作在map节点的本地
- 分区的作用?
- 默认的分区规则,哈希模运算来进行分区,获取hash值,所有的map的输出的数据,经过partition后得到0和1,所有的数据要么分到零区,要么分到1区,刚好reduce有两个,所以0区和1区对应两个不同的reduce,可以解决负载均衡,数据倾斜问题(一个节点计算的数据多,一个节点计算的数据小)
- 优化和设计好partition可以解决数据的倾斜问题
- 默认的排序是按照对象对应的ASCII的值进行排序,按照字典进行排序的,
- 在fetch的时候数据根据自己的区分开了
- 可以自定义合并Combiner,目的是减少map的输出
- reduce拷贝从map上分给它的数据,然后key相同的又进行一次合并,相同key的数据传给reduce进行执行
### 5.Hadoop计算框架shuffle过程详解
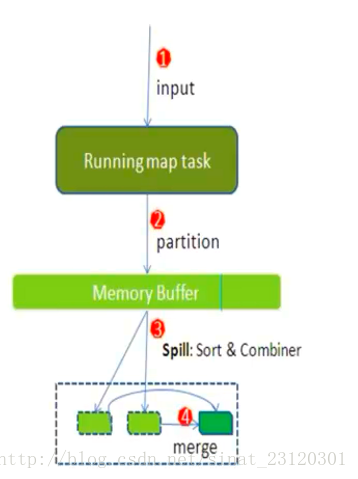
- 每一个map task 都有一个内存缓冲区(默认的是100MB),存储着map的输出的结果
- 当缓冲区快满的时候需要将缓冲区的数据以临时文件的方式存放在磁盘中(Spill)
- 溢写是由单独线程来完成的,不影响往缓冲区中写map结果的线程(spill.precent,默认的大小是0.8)
- 当溢写线程启动后,需要对这80MB的空间内的Key进行排序(sort)
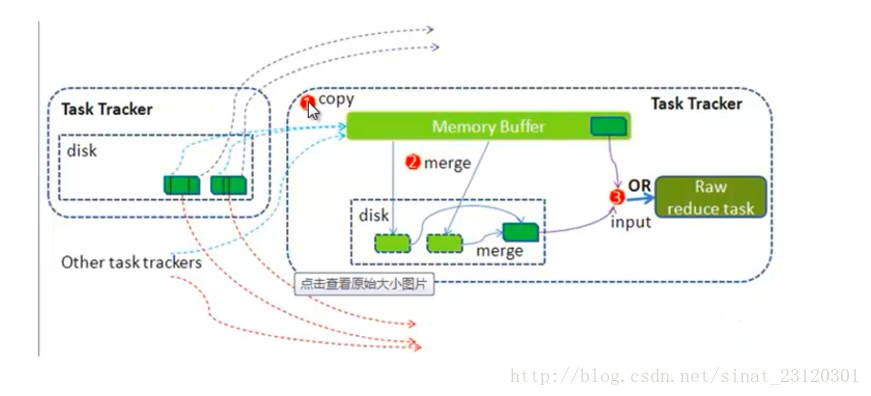
merge是按照key相同进行合并
### 6.MapReduce的Split的大小
- max.split(100M)
- min.split(10M)
- block(64M)
- max(min.split,min(max.split,block))
## 二、MapReduce的搭建
### 1.MapReduce的架构
- 一主多从架构
- 主Jobtracker
- 负责调度分配每一个子任务task运行于TaskTracker上,如果发现有失败的task就重新分配其任务到其他的节点上,每一个hadoop集群中只有一个JobTracker一般它运行在Master的节点上
- 从TaskTracker
- TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务,为了减少网络带宽与TaskTracker最好运行在HDFS的DataNode上
### 2.修改配置文件
- vi /home/hadoop-1.2/conf/mapred-site.xml
-
```xml
mapred.job.tracker
localhost:9001
```
- scp ./* [email protected]:/home/hadoop-1.2/conf/
- scp ./* [email protected]:/home/hadoop-1.2/conf/
### 3.启动
- ./stop-dfs.sh
- ./start-all.sh
- 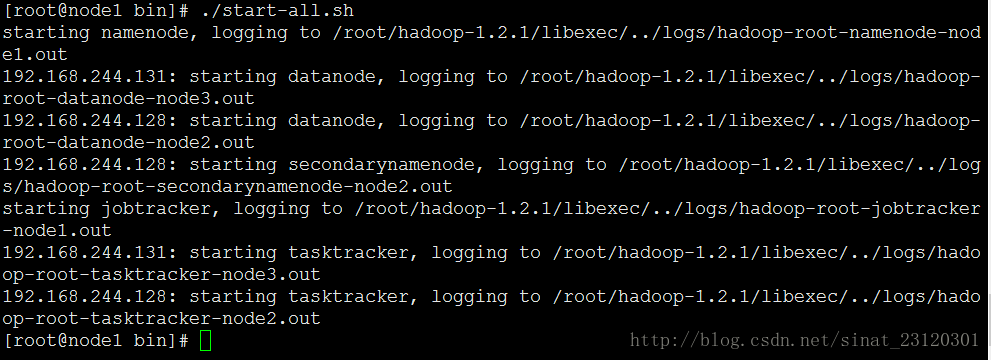
- ==注意一个问题是;如果在我的机器的情况下出现了NameNode和JobTracker但是在DateNode下面没有出现TaskTracker,很有可能是出现了在hadoop的conf配置文件中的mapred-site.xml 没有内容,此时把配置好的Node1上的mapred-site.xml 里面的东西复制进去scp ./mapred-site.xml [email protected]:~/hadoop-1.2.1/conf/==
## 3.MapReduce的程序
#### 3.1所有需要注意的事项
- 在上传文件的时候记得需要关闭防火墙和seLinux,可以参考博客 [关闭LInux的防火墙和seLinux](http://blog.csdn.net/shangdiyisi/article/details/9430965)
### 3.2、广告的精准的推送
#### 3.2.1、关注度的算法TF-IDF加权Mahout
- Term Frequency - Inverse Document Frequency
- 词频
- 逆文档频率
- 就是说,如果一个单词在所有的文档中被使用的越频繁,那它对向量中的值得作用就会被抵消的越多
- 文档向量中单词的权重:
W~i~=TF~i~*log(N/DF~i~)
- TF~i~:总词频DF:词在文章中出现股,在一个文章中出现多次,只计算一次N:总文章数;当前的关键字在该条微博中出现的次数
- DF表示的是当前的关键字在所有的微博内容中出现的微博条数; 比如九阳。在某条微博中出现4次,只计算为一条
- N:是微博的总条数
## 一、MapReduce(MR)的概述
[TOC]
### 1.MapReduce的介绍
- Hadoop的分布式计算框架(MapReduce)
- MapReduce是分布式计算框架的一种,适合做离线计算框架;Strom适合做流式计算框架,更加适合做实时计算框架,stark是内存计算框架,适合做快速得到结果的计算
### 2.MapReduce的计算理念
- 何为分布式计算
- 移动计算,而不是移动数据(就是分析计算的程序分别拷贝一份到不同的机器上,但是数据不移动)
### 3.计算框架MR

1. 从HDFS上存储的数据作为数据的输入,并且进行处理,成为一个个的split(片段)
2. 每一个片段由一个MAP线程去执行(并发的去执行)
3. 从map的执行结束到reduce的执行之前都是Shuffling
4. 然后就是Reduce进行执行。执行后的数据保存在HDFS中的

### 4.Hadoop计算框架Shuffler
- 在mapper和reduce中间的一个步骤
- 可以把mapper的输出按照某种key值重新切分和组合成n份,把key值符合某种范围的输出送到特定的reducer那里去
- 可以简化reducer的过程

- map是一段java程序,输出的结果在内存中,内存有一定的阈值,当到达阈值后,溢写到磁盘中
- map的输出首先进行partition(分区)。然后进行sort(排序),spill to disk溢写到磁盘
- 当前的操作在map节点的本地
- 分区的作用?
- 默认的分区规则,哈希模运算来进行分区,获取hash值,所有的map的输出的数据,经过partition后得到0和1,所有的数据要么分到零区,要么分到1区,刚好reduce有两个,所以0区和1区对应两个不同的reduce,可以解决负载均衡,数据倾斜问题(一个节点计算的数据多,一个节点计算的数据小)
- 优化和设计好partition可以解决数据的倾斜问题
- 默认的排序是按照对象对应的ASCII的值进行排序,按照字典进行排序的,
- 在fetch的时候数据根据自己的区分开了
- 可以自定义合并Combiner,目的是减少map的输出
- reduce拷贝从map上分给它的数据,然后key相同的又进行一次合并,相同key的数据传给reduce进行执行
### 5.Hadoop计算框架shuffle过程详解

- 每一个map task 都有一个内存缓冲区(默认的是100MB),存储着map的输出的结果
- 当缓冲区快满的时候需要将缓冲区的数据以临时文件的方式存放在磁盘中(Spill)
- 溢写是由单独线程来完成的,不影响往缓冲区中写map结果的线程(spill.precent,默认的大小是0.8)
- 当溢写线程启动后,需要对这80MB的空间内的Key进行排序(sort)

merge是按照key相同进行合并
### 6.MapReduce的Split的大小
- max.split(100M)
- min.split(10M)
- block(64M)
- max(min.split,min(max.split,block))
## 二、MapReduce的搭建
### 1.MapReduce的架构
- 一主多从架构
- 主Jobtracker
- 负责调度分配每一个子任务task运行于TaskTracker上,如果发现有失败的task就重新分配其任务到其他的节点上,每一个hadoop集群中只有一个JobTracker一般它运行在Master的节点上
- 从TaskTracker
- TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务,为了减少网络带宽与TaskTracker最好运行在HDFS的DataNode上
### 2.修改配置文件
- vi /home/hadoop-1.2/conf/mapred-site.xml
-
```xml
```
- scp ./* [email protected]:/home/hadoop-1.2/conf/
- scp ./* [email protected]:/home/hadoop-1.2/conf/
### 3.启动
- ./stop-dfs.sh
- ./start-all.sh
- 
- ==注意一个问题是;如果在我的机器的情况下出现了NameNode和JobTracker但是在DateNode下面没有出现TaskTracker,很有可能是出现了在hadoop的conf配置文件中的mapred-site.xml 没有内容,此时把配置好的Node1上的mapred-site.xml 里面的东西复制进去scp ./mapred-site.xml [email protected]:~/hadoop-1.2.1/conf/==
## 3.MapReduce的程序
#### 3.1所有需要注意的事项
- 在上传文件的时候记得需要关闭防火墙和seLinux,可以参考博客 [关闭LInux的防火墙和seLinux](http://blog.csdn.net/shangdiyisi/article/details/9430965)
### 3.2、广告的精准的推送
#### 3.2.1、关注度的算法TF-IDF加权Mahout
- Term Frequency - Inverse Document Frequency
- 词频
- 逆文档频率
- 就是说,如果一个单词在所有的文档中被使用的越频繁,那它对向量中的值得作用就会被抵消的越多
- 文档向量中单词的权重:
W~i~=TF~i~*log(N/DF~i~)
- TF~i~:总词频DF:词在文章中出现股,在一个文章中出现多次,只计算一次N:总文章数;当前的关键字在该条微博中出现的次数
- DF表示的是当前的关键字在所有的微博内容中出现的微博条数; 比如九阳。在某条微博中出现4次,只计算为一条
- N:是微博的总条数