论文阅读《Wide-Context Semantic Image Extrapolation》与代码实现
1:介绍
作者首先介绍了一下自己的方法可以从一小部分面部生成具有头发和背景的完整肖像,根据体形创建鸟头和尾部(图1)或仅生成完整的人体上半身信息。算法需要适应考虑每个不完整图像的非常不同的上下文并且预测多达未知像素的三倍。
改变图像大小将图像大小扩展到边界之外类似的是超分辨率重建,就是从馈入网络之前对输入进行上采样,或者是在网络中使用空间扩展模块。
单侧约束上下文的边界条件只有一侧,如图1所示,黑色表示推理方向。远离图像边界的未知像素比边界附近的像素受到的约束更少,可能会累计错误或重复模式。所以设计了相对空间变异损失,上下文对抗损失和上下文归一化来规范生成的过程。
 所以最后作者提出了语义再生网络(SRN),从一小部分重新生成完整的图像,直接从小尺寸输入中学习语义特征,SRN包含了特征扩展网络(FEN)和上下文预测网络(CPN),FEN将小尺寸图像作为输入并提取特征。这些特征和外推指标被亏松到CPN以重建最终扩展结构。此外,设计的损失和其他处理模块使得我们的网络适应单侧约束,产生具有意义的结构和自然纹理。
所以最后作者提出了语义再生网络(SRN),从一小部分重新生成完整的图像,直接从小尺寸输入中学习语义特征,SRN包含了特征扩展网络(FEN)和上下文预测网络(CPN),FEN将小尺寸图像作为输入并提取特征。这些特征和外推指标被亏松到CPN以重建最终扩展结构。此外,设计的损失和其他处理模块使得我们的网络适应单侧约束,产生具有意义的结构和自然纹理。
2:方法
给定一个输入图像
![]()
和填充边界
![]()
而后生成了一个令人相信的![]() ,
,![]()
W’=W+left+right,同时h’=r1h w’=r2w
3:框架
FEN从给定的图像中提取深度特征,并且CPN将这些特征解码为考虑填充边界和尺寸。输入包含一个图像X和一个边距变量m=(top,left,bottom,right)表示扩展。
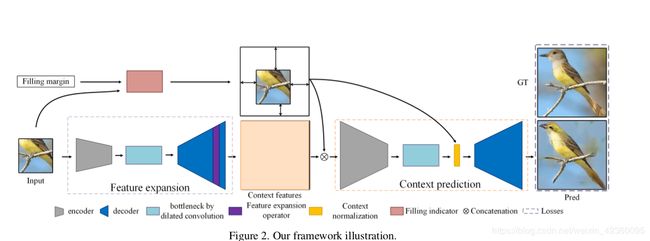
3.1:特征扩展模块
该模块类似编码器-解码器,输入仅为大小为hXwXc的X,输出大小是r 1 h × r 2 w × c ‘.那么如何增大图像的尺寸呢,这边用到了一个超分辨率重建里面的子像素卷积,给定一个特征映射,![]() ,然后接着是“重新排列操作”,定义为
,然后接着是“重新排列操作”,定义为
![]()
![]() ,i,j,k 分别表示为索引高度,宽度和通道。
,i,j,k 分别表示为索引高度,宽度和通道。
FEN用于学习潜在的上下文功能,实验表明,早期批次中的填充像素是后期生成的一种先验,直接以可用像素为条件的计算机可以在保真度和视觉自然度方面产生更好的表现。所以作者的模型直接推断给定的视觉数据而美亚预定义的先验。
3
3.2:上下文预测
也是类似编码器解码器的网络,输入是f(x)和填充指示符的串联,即二进制掩码。输出为Y^,大小为r 1 h × r 2 w × c,还有个上下文归一化模块,用于协调填充区域和已知区域之间的特征分布。
CPN网络包含FEN中排除的填充边际,以指示预测未知,其次除了填充余量之外,对网络的输入还包括由FEN而不是粗略预测学习的上下文特征,通过编码器-解码器和设计的上下文归一化模块进行压缩可以正确处理这些功能。
上下文规范化是为了提高生成的图像的样式一致性,CN函数定义为:

![]() 分别表示为已知和未知区域。f()在输入扩展的特征图上提取“瓶颈”特征,ρ ∈ [0, 1],↓ 表示最近邻的下采样运算符。 M↓与f(x)具有相同的高度和宽度。 μ(·) and σ(·)计算平均差和标准差。本质上来说它将已知特征的均值和方差转移到未知区域,这使得生成的内容超出了一些约束。
分别表示为已知和未知区域。f()在输入扩展的特征图上提取“瓶颈”特征,ρ ∈ [0, 1],↓ 表示最近邻的下采样运算符。 M↓与f(x)具有相同的高度和宽度。 μ(·) and σ(·)计算平均差和标准差。本质上来说它将已知特征的均值和方差转移到未知区域,这使得生成的内容超出了一些约束。
4:损失函数
4.1 相对空间变异损失
它通过提供像素监督来稳定训练过程,由于内容外推,需要空间变异监督,所以设计了相对空间变量(RSV)重建损失以结合这种空间正则化,表示为
![]() ,g是归一化高斯滤波器,
,g是归一化高斯滤波器,
![]() ,是哈达玛积运算符
,是哈达玛积运算符
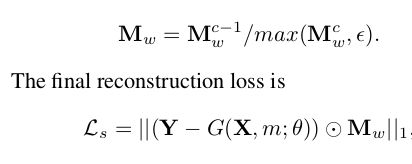 ,权重矩阵和最后的重建损失定义。
,权重矩阵和最后的重建损失定义。
G(X, m; θ) 是G的输出,Y是对应的真实,θ是可学习的参数。
4.2 隐式多样化MRF损失
通过G(X, m)和 Y的近似特征分布来创建清晰纹理。
![]()
使用这两个来表示从中提取的特征,Ŷ Ω表示要填充的区域的预测。
![]()
这两个之间的ID-MRF损失定义为:

Z是归一化因子。(8) 是Eq的标准化版本 (9) 分别定义了来自Ŷ Ω和YL的两个提取补丁V和S的相似性。
β(·, ·) 是余弦相似度. r ∈ ρ s (Y L ) 表示除S以外的属于Y L 的r 。h和E是两个正常数。
如果v比YL中的其他神经斑块更像 , RS(v, s)就变大。

ID-MRF损失通过引用其最基本相似的补丁来加强局部图像细节。
4.3 情境对抗性损失
Ŷ输入预测定义为:

d context ( Ŷ)表示Ŷ的特征图,↓表示最大池化算子,对于SRN,全局/上下文对抗性损失定义为:


最终的网络模型为:

![]() 分别用于平衡回归,局部结构正则化和对抗性训练之间系数。
分别用于平衡回归,局部结构正则化和对抗性训练之间系数。
5:代码实现
https://github.com/shepnerd/outpainting_srn
Key components
Small-to-large scheme
Context normalization
Relative spatial variant loss
Prerequisites
Python3.5 (or higher)
Tensorflow 1.6 (or later versions, excluding 2.x) with NVIDIA GPU or CPU
OpenCV
numpy
scipy
easydict
测试:
下载CelebA-HQ的预训练模型,并且把他们解压到checkpoints下,命名为celebahq-srn-subpixel文件夹,三个文件都要下
CelebA-HQ_256 examples in the imgs/celebahq-256/. 举个例子
python test.py --dataset celebahq-256 --data_file ./imgs/celebahq-256/ --load_model_dir ./checkpoints/celebahq-srn-subpixel --random_mask 1 --model srn
结果最后都会被保存在 ./test_results/.
训练:
首先是重建损失(set the opinion --pretrain_network 1),然后是fine-tuning模型带着所有的损失函数(–pretrain_network 0 and --load_model_dir [Your model path])
两个过程之后来准备预训练网络,
python train.py --dataset [DATASET_NAME] --data_file [DATASET_TRAININGFILE] --gpu_ids [NUM] --pretrain_network 1 --batch_size 16
[DATASET_TRAININGFILE] 包含了一个存储所有训练图片路径的文件.举个例子:
python train.py --dataset celebahq-256 --data_file …/celebahq-256_train.txt --gpu_ids 0 --img_shapes 256,256 --pretrain_network 1 --batch_size 8
接着是fineture网络
python train.py --dataset [DATASET_NAME] --data_file [DATASET_TRAININGFILE] --gpu_ids [NUM] --pretrain_network 0 --load_model_dir [PRETRAINED_MODEL_PATH] --batch_size 8

