Hadoop--HDFS的安装及配置使用
下载 Hadoop,
[http://hadoop.apache.org/releases.html ](http://hadoop.apache.org/releases.html)
上传:上传到master机器节点的目录~/bigdata下(可以用FileZilla等ftp工具上传)
需要预先在master节点中的hadoop-jrq用户下的主目录下创建bigdata目录:
即执行mkdir bigdata
cd ~/bigdata
解压hadoop-2.7.5 tar: tar -zxvf ~/bigdata/hadoop-2.7.5.tar.gz
修改配置文件(在~/bigdata/hadoop-2.7.5/etc/hadoop下):
cd ~/bigdata/hadoop-2.7.5/etc/hadoop
修改core-site.xml
fs.defaultFS
hdfs://master:9999
表示HDFS的基本路径
修改hdfs-site.xml
dfs.replication
2
表示数据块的备份数量,不能大于DataNode的数量
dfs.namenode.name.dir
/home/hadoop-jrq/bigdata/dfs/name
表示NameNode需要存储数据的地方
dfs.datanode.data.dir
/home/hadoop-jrq/bigdata/dfs/data
DataNode存放数据的地方
在master上创建创建nameNode和dataNode需要的文件目录
mkdir -p ~/bigdata/dfs/name
mkdir -p ~/bigdata/dfs/data
修改 hadoop-env.sh
在hadoop-env.sh中添加JAVA_HOME:
export JAVA_HOME=你的java路径
修改~/bigdata/hadoop-2.7.5/etc/hadoop/slaves,在slaves文件中写入如下内容:
slave1
slave2
在slave1和slave2节点中的hadoop-jrq用户下的主目录下创建bigdata目录:
即执行mkdir bigdata
将master上配置好的hadoop分发到每一个slave上
scp -r ~/bigdata/dfs hadoop-jrq@slave1:~/bigdata
scp -r ~/bigdata/dfs hadoop-jrq@slave2:~/bigdata
scp -r ~/bigdata/hadoop-2.7.5 hadoop-jrq@slave1:~/bigdata
scp -r ~/bigdata/hadoop-2.7.5 hadoop-jrq@slave2:~/bigdata
在master上切换到hadoop-jrq用户,然后添加环境变量, vi ~/.bash_profile:
export HADOOP_HOME=~/bigdata/hadoop-2.7.5
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bash_profile
which hdfs看看输出是否是:~/bigdata/hadoop-2.7.5/bin/hdfs
如果不是可能需要退出xshell,重新登录
运行hdfs
格式化: hdfs namenode -format
启动hdfs: 运行start-dfs.sh
http://master:50070看下是否部署成功
停止hdfs: 运行stop-dfs.sh
HDFS文件目录结构及其常用操作命令
HDFS文件目录结构和Linux文件目录结构类似
$HADOOP_HOME/bin/hadoop fs == $HADOOP_HOME/bin/hdfs dfs
创建目录:
hadoop fs -mkdir [-p] hdfs://master:9999/user/hadoop-jrq/cmd
上传文件:
hadoop fs -put [-f -d] [localFile1...localFile2] hdfs://master:9999/user/hadoop-jrq/cmd
hadoop fs -put - hdfs://master:9999/user/hadoop-jrq/cmd/out.txt => 从标准流中上传数据
hadoop fs -copyFromLocal [-f -d] localFile hdfs://master:9999/user/hadoop-jrq/cmd
查看文件内容:
hadoop fs -cat hdfs://master:9999/user/hadoop-jrq/cmd/word.txt
查看文件目录:
hadoop fs -ls [-d -h -r] hdfs://master:9999/user/hadoop-jrq/cmd
修改文件权限:
hadoop fs -chmod [-R] 777 hdfs://master:9999/user/hadoop-jrq/cmd
创建新文件:
hadoop fs -touchz hdfs://master:9999/user/hadoop-jrq/cmd/flag.txt
查看文件大小:
hadoop fs -du [-s -h] hdfs://master:9999/user/hadoop-jrq/cmd
查看集群容量使用情况
hadoop fs -df [-h] hdfs://master:9999/
移动文件:
hadoop fs -mv hdfs://master:9999/user/hadoop-jrq/cmd/file hdfs://master:9999/user/hadoop-jrq/cmd
下载文件:
hadoop fs -get [-f] hdfs://master:9999/user/hadoop-jrq/cmd
删除文件:
hadoop fs -rm [-r -skipTrash] hdfs://master:9999/user/hadoop-jrq/cmd/word.txt
默认文件删除就恢复不出来了
如果想恢复出来的话,需要配置Trash机制,在core-site.xml中配置:
fs.trash.interval
3
3表示3分钟内可以恢复
scp core-site.xml hadoop-jrq@slave1:~/bigdata/hadoop-2.7.5/etc/hadoop/
scp core-site.xml hadoop-jrq@slave2:~/bigdata/hadoop-2.7.5/etc/hadoop/
重启Hadoop集群
恢复删除的文件
hadoop fs -rm -r /user/hadoop-jrq/cmd-20180326
hadoop fs -cp hdfs://master:9999/user/hadoop-jrq/.Trash/180326230000/user/hadoop-jrq/* /user/hadoop-jrq => 从Trash中恢复出来
hadoop fs -rm -r -skipTrash /user/hadoop-jrq/cmd-20180326 => 删除的文件不放在Trash中
使用WebHDF访问HDFS
在hdfs-site.xml中增加如下配置,然后重启HDFS:
dfs.webhdfs.enabled
true
使得可以使用http的方式访问HDFS
使用http访问:
http://master:50070/webhdfs/v1/user/hadoop-jrq/cmd/error.txt?op=LISTSTATUS
支持的op见:
[http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-hdfs/WebHDFS.html](http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-hdfs/WebHDFS.html)
HDFS中的数据块(Block)
数据块的默认大小为: 128M
设置数据块的大小为: 256M * 1024 * 1024
在${HADOOP_HOME}/etc/hadoop/hdfs-site.xml中加上配置:
```
dfs.block.size
268435456
```
数据块的默认备份数是3
单独设置数据块的备份数
hadoop fs -setrep 2 /users/hadoop-jrq/cmd/word.txt 备份两份
数据块都是存储在每一个DataNode所在的机器本地磁盘文件中
DataNode
1、register : 将自身的一些信息(hostname, version等)告诉name node,name node经过check后使其成为集群中的一员
2、block report :将block的信息汇报给name node,使得name node可以维护数据块和数据节点之间的映射关系
3、定期的send heartbeat :
3.1 :告诉name node我还活着,我的存储空间还有多少等信息
3.2 :执行name node通过heartbeat传过来的指令,比如删除数据块
NameNode
名字节点中维护了两层关系:
1、HDFS文件系统的文件目录树,以及文件数据块的索引,即每一个文件对应的数据块列表
2、数据块与数据节点的关系,即某一数据块保存在哪些数据节点中
1、/user/hadoop-jrq/cmd/word.txt => b1,b2,b3
2、/user/hadoop-jrq/cmd/temp.txt => b4,b5
为了使得客户端访问的速度最快,那么这些数据放在内存中
但是,如果NameNode进程崩溃或者所在机器断电,那么上述的数据全部丢失,系统无法恢复
所以,上述的数据必须保存在磁盘中(也就说内存保存一份,磁盘保存一份)
编辑日志(EditsLog):保存着所有对元数据的改动日志
命名空间镜像(FSImage):负责将内存中的数据按照合理的格式定期的保存在磁盘中
保存着某一时刻的目录信息
FSImage是某一时刻的内存元数据的真实组织情况,
而EditsLog则是记录了该时刻后所有元数据的改动
从而保证NameNode中的数据不会丢掉,可以从磁盘中恢复出来
SecondNameNode
用于给NameNode
来合并Edits日志和FsImage的
HDFS各组件总结
1、NameSpace用于存储树状文件目录等、还支持创建、删除以及查询文件目录等操作
2、Block Storage包括了数据块的管理、数据块的存储等
3.Block Pool: 一个NameSpace的数据块池,每一个Block Pool是独立管理的,互不影响
federation
增加namenode:当集群很大的时候,一台机器需要保存很多信息,这些信息都是保存在内存中,显然对master的压力很大,因此需要增加namenode
配置hdfs-site.xml:
在slave1上增加一个namenode的配置如下:
dfs.nameservices
ns1,ns2
dfs.namenode.rpc-address.ns1
master:9999
dfs.namenode.http-address.ns1
master:50070
dfs.namenode.secondary.http-address.ns1
master:9001
dfs.namenode.rpc-address.ns2
slave1:9999
dfs.namenode.http-address.ns2
slave1:50070
dfs.namenode.secondary.http-address.ns2
slave1:9001
拷贝hdfs.xml到slave1和slave2:
scp hdfs-site.xml hadoop-jrq@slave1:~/bigdata/hadoop-2.7.5/etc/hadoop/
scp hdfs-site.xml hadoop-jrq@slave2:~/bigdata/hadoop-2.7.5/etc/hadoop/
修改slave1中的core-site.xml:
fs.defaultFS
hdfs://slave1:9999
表示HDFS的基本路径
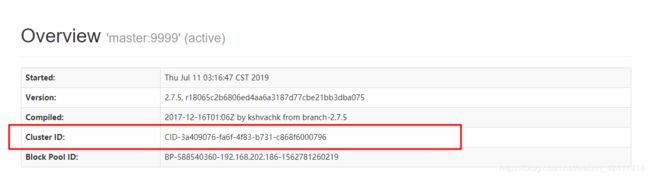
bin/hdfs namenode -format -clusterId CID-1cd5229f-4586-457a-8b09-487e879cf1ad
clusterId :一个集群的ID是一样的
viewFs配置
上述操作虽然增加了一个namenode但是slave1却成为了一个单独的namenode,上传到master的目录,slave1是查看不到的,slave1的namenodemaster也是看不到的,这不是我们希望的
配置core-site.xml:
将之前的:注释掉
```
fs.defaultFS
hdfs://master:9999
表示HDFS的基本路径
```
换成如下:
```
fs.default.name
viewfs://my-cluster // 这个名字是自己起的
```
增加mountTable.xml:
```
fs.viewfs.mounttable.my-cluster.link./user
hdfs://master:9999/user // user是目录名,配置后两者共享 有多少个目录,就配置多少
fs.viewfs.mounttable.my-cluster.link./tmp
hdfs://master:9999/tmp
fs.viewfs.mounttable.my-cluster.link./projects/foo
hdfs://slave1:9999/projects/foo
fs.viewfs.mounttable.my-cluster.link./projects/bar
hdfs://slave1:9999/projects/bar
```
scp core-site.xml mountTable.xml hadoop-jrq@slave1:~/bigdata/hadoop-2.7.5/etc/hadoop/
scp core-site.xml mountTable.xml hadoop-jrq@slave2:~/bigdata/hadoop-2.7.5/etc/hadoop/
重启hdfs集群
现在在哪里执行hadoop fs -ls / 都是一样的
snapshot(快照,用于数据备份、保护数据不被破坏)
hdfs dfsadmin -allowSnapshot /user/hadoop-jrq/cmd => 允许这个文件路径可以创建snapshots
hdfs dfs -createSnapshot /user/hadoop-jrq/cmd cmd-20180326-snapshot => 创建snapshots
hdfs dfs -ls /user/hadoop-jrq/cmd/.snapshot/cmd-20180326-snapshot => 查看snapshots
hdfs dfs -touchz /user/hadoop-jrq/cmd/test1.txt => 不小心往文件中写入了一个错误数据文件
hdfs dfs -touchz /user/hadoop-jrq/cmd/test2.txt => 不小心往文件中写入了一个错误数据文件
hdfs dfs -createSnapshot /user/hadoop-jrq/cmd cmd-20180327-snapshot => 创建snapshots
hdfs snapshotDiff /user/hadoop-jrq/cmd cmd-20180326-snapshot cmd-20180327-snapshot
hdfs dfs -cp -ptopax /user/hadoop-jrq/cmd/.snapshot/cmd-20180326-snapshot /user/hadoop-jrq/ => 恢复文件
hdfs dfs -deleteSnapshot /user/hadoop-jrq/cmd cmd-20180327-snapshot => 删除snapshots
hdfs dfs -renameSnapshot /user/hadoop-jrq/cmd cmd-20180327-snapshot new_snapshot => 重命名snapshots
hdfs lsSnapshottableDir => 查看所有的snapshots
hdfs dfsadmin -disallowSnapshot => 不允许这个path创建snapshots
rebalance — 数据平衡
hdfs balancer
[-threshold => 默认是10,表示每一个datanode的存储使用率和整个集群存储的使用率的差值]
[-policy => 默认是datanode表示对datanode的存储进行平衡,还有一个值为blockpool,表示每一个datanode中的 blockpool平衡就行]
[-exclude [-f | ]]
[-include [-f | ]]
[-idleiterations => 默认是5,表示退出之前几次空的迭代]
safemode – 安全模式
当集群处于Safemode状态的时候,我们是不能对集群的数据进行更改的(删除和增加)
hdfs dfsadmin -safemode get => 查询safemode的状态
hdfs dfsadmin -safemode enter => 进入到savemode状态
hdfs dfs -mkdir /user/hadoop-jrq/savemode => 在savemode状态下不能修改集群的数据
hdfs dfsadmin -safemode leave => 离开savemode状态
集群刚启动的时候会是SaveMode状态
我们对集群进行维护的时候,不想客户端更改集群任何数据的时候