Python爬虫实战之爬取豆瓣详情以及影评
爬取豆瓣详情分为三步:
1.爬取豆瓣电影的所有标签,遍历标签,通过分析网址结构获得每一类标签下的电影url
2.通过url 爬取电影详情
3.导入数据库
爬虫代码如下:
from urllib import parse
import urllib
import random
from urllib.error import URLError
from urllib.request import ProxyHandler, build_opener
import json
from bs4 import BeautifulSoup
from urllib import request
import re
import pymysql
class Spider(object):
def get_ip(self):
fr=open('ip.txt','r')##代理ip文件
ips=fr.readlines()
new=[]
for line in ips:
temp=line.strip()
new.append(temp)
ip=random.choice(new)
proxy =ip
proxy_handler = ProxyHandler({
'http': 'http://' + proxy,
'https': 'https://' + proxy
})
opener = build_opener(proxy_handler)
self.get_info(opener)
def get_info(self,opener):
url='https://movie.douban.com/j/search_tags?type=movie&source='
try:
headers={'User-Agent':' Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
req=urllib.request.Request(url,headers=headers)
data=opener.open(req).read().decode('utf-8')
json_res=json.loads(data)
tags=json_res['tags']
i=0
for tag in tags:
print("正在爬取" + str(tag))
#tag={
# 'tag':tag,
# 'page_star':i
#}
start=0
step=1001 #控制长度
for i in range(start,21,step):
tag = urllib.request.quote(tag)
tag_url='https://movie.douban.com/j/search_subjects?type=movie&tag='+tag+'&sort=recommend&page_limit=20&page_start='+str(i)
req = request.Request(tag_url, headers=headers)
response=opener.open(tag_url).read().decode('utf-8')
response_dict=json.loads(response)
subjects=response_dict['subjects']
try:
for subject in subjects:
movie_id = subject['id']
movie_title = subject['title']
movie_rate=subject['rate']
movie_cover =subject['cover']
movie_url=subject['url']
print(movie_id)
print(movie_title)
print(movie_url)
html=request.urlopen(movie_url).read().decode('utf-8')
html = html[1:len(html) + 1]
bs = BeautifulSoup(html, 'lxml')
# print(bs.find(attrs={'id':'info'}).text)#电影信息
# print(bs.find('h2').text)
# print(bs.find_all('h2')[0].text)#简介列表
# print(bs.find(attrs={'class':'related-info'}).text.strip())
filmName = bs.h1.span.text
fileDIV = bs.find(attrs={'id': 'info'})
file1 = fileDIV.findAll(class_='p1')
spans = fileDIV.findAll('span')
span_atters = fileDIV.findAll(class_='attrs')
director_span = span_atters[0]
screenwriter_span = span_atters[1]
staring_span = span_atters[2]
director_str = ''
screenwriter_str = ''
staring_str = ''
director_a = director_span.findAll('a')
for director_a in director_a:
director_str = director_str + director_a.text + ';'
print(director_str) #导演
screenwriter_span = screenwriter_span.findAll('a')
for screenwriter_a in screenwriter_span:
screenwriter_str = screenwriter_str + screenwriter_a.text + ';'
print(screenwriter_str) #编剧
staring_span = staring_span.findAll('a')
for staring_a in staring_span:
staring_str = staring_str + staring_a.text + ';'
print(staring_str) #主演
file_type = ''
file_type_spans = bs.find_all('span', {'property': "v:genre"})
for file_type_span in file_type_spans:
file_type = file_type + file_type_span.text + ';'
print(file_type) #类型
pattern = re.compile("制片国家/地区:(.*)")
movie_country=pattern.findall(fileDIV.text)[0]
print(movie_country)
pattern2 = re.compile("语言:(.*)")
movie_language=pattern2.findall(fileDIV.text)[0]
print(movie_language)
movie_release_date = bs.find('span', {'property': 'v:initialReleaseDate'}).text
print(movie_release_date) #日期
movie_length = bs.find('span', {'property': "v:runtime"}).text
print(movie_length) #电影长度
pattern3 = re.compile("又名:(.*)")
movie_alias=pattern3.findall(fileDIV.text)[0]
print(movie_alias) #名字
pattern4 = re.compile("IMDb链接:(.*)")
imdb=pattern4.findall(fileDIV.text)[0]
print(imdb)
#brief=bs.find('span', {'property': 'v:summary'}).text.strip()
#print(brief.replace(' ', ''))
movies =(movie_id,movie_title,director_str,screenwriter_str,staring_str,file_type,movie_country,movie_language,movie_release_date,movie_length,movie_alias,imdb)
self.con_mysql(movies,movie_title,movie_id)
except URLError as e:
print(e.reason)
except URLError as e:
print(e.reason)
def con_mysql(self,movies,movie_title,movie_id):
try:
host = 'localhost'
user = 'root'
pwd = ''
database = 'douban'
db = pymysql.connect(host, user, pwd, database,charset="utf8")
cursor = db.cursor() # 获取一个邮标,增删减除
sql = "select * from movie3 where movie_id=%s" % movie_id
cursor.execute(sql)
one = cursor.fetchone() # 返回单个元组
db.commit()
if (one is not None):
print(str(movie_title)+"已存在该ID")
pass
else:
cursor.execute("insert ignore into movie3 values('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')" % movies)
two=cursor.fetchone()
db.commit()
if (two is None):
print('插入失败')
else:
print(str(movie_title) + "插入成功")
except URLError as e:
print(e.reason)
spider=Spider()
spider.get_ip()
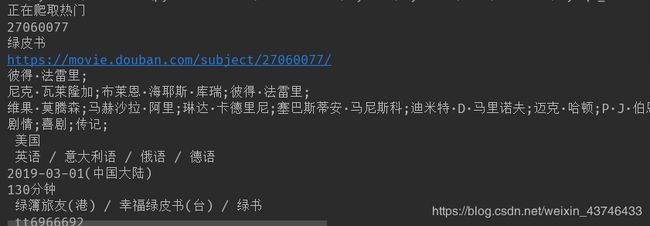
运行结果如下: