python爬取book118中的书籍
文章目录
- 前言
- 新版
- 网站分析
- 提取内嵌html
- 分析内嵌html
- 获取图片链接
- 代码
- 下载
- 合并pdf
- 旧版
- 网站分析
- 提取内嵌html
- 分析内嵌html
- 获取图片链接
- 代码展示
- 运行结果
- 下载并合成pdf
前言
不满足于上次从360doc爬取了概率论的答案,这次便研究了一下book118,爬取了里面我需要的答案书。不过由于网站的设计比360doc的复杂,我又不擅长java的爬虫,所以这次用python获取图片链接,接着用之前写的java下载图片并合并成pdf。
2019.8.17
针对网站的变化,采取了新的方式进行爬取
完善了python下载图片并合成pdf的代码
新版
网站分析
提取内嵌html
与旧版不同的是,现在换成了一个php页面进行的预览。
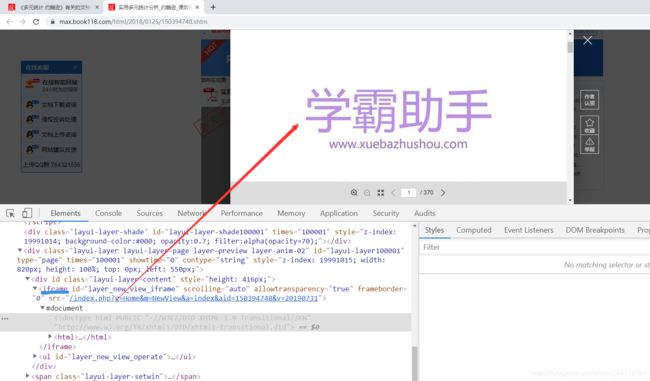
分析内嵌html
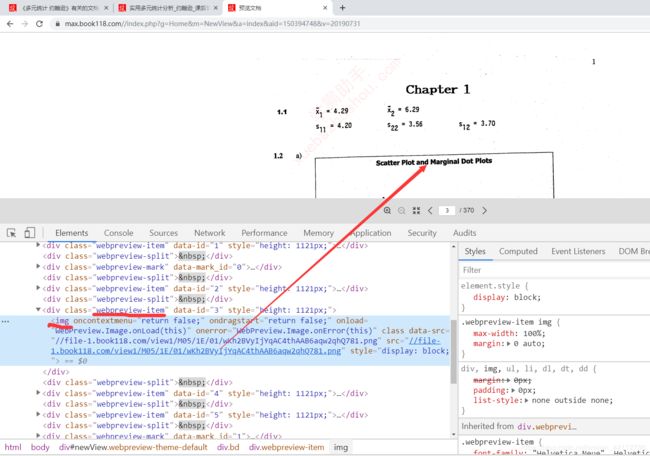
图片链接也很容易拿到,通过class选择webpreview-split可以定位到每张图,再获取img的src即可。
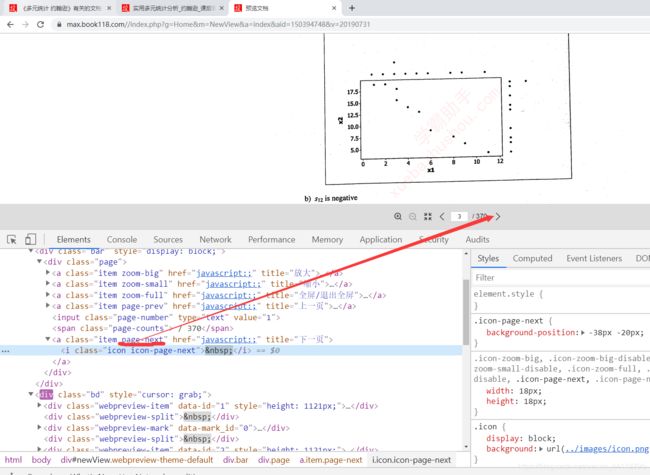
其实进这个页面就是为了翻页的方便,很容易找到翻页按钮,通过class选择器page-next就可以选中。
获取图片链接
代码
这里我为了学习一下xpath用到了etree,不会的可以用我之前分析出的class选择器用beautifulsoup4或者pyquery进行元素定位。
from lxml import etree
import time
from selenium import webdriver
from save_mongo import save_to_mongo
browser = webdriver.Chrome()
browser.get("https://max.book118.com//index.php?g=Home&m=NewView&a=index&aid=150394748&v=20190731")
# 先翻页
nextpage = browser.find_element_by_class_name('page-next')
for i in range(0, 370):
nextpage.click()
time.sleep(1) # 等待图片加载
# 再解析
page_text=browser.page_source
# 解析页面数据(获取页面中的图片链接)
# 创建etree对象
tree = etree.HTML(page_text)
div_list = tree.xpath("//div[@class='webpreview-item']")
urls = []
# 解析获取图片地址和图片的名称
for div in div_list:
urls.append(div.xpath('.//img/@src'))
for i in range(len(urls)):
print(urls[i])
save_to_mongo("information", {"page": str(i+1), "url": urls[i]})
下载
其实可以直接不保存到MongoDB,直接下载;不过旧版的链接保存到了MongoDB,再接着从MongoDB下载。这里延续之前的操作,也可以巩固巩固自己python读取MongoDB的操作吧。
import pymongo
import requests
# 连接MongoDB,创建集合
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["book118"]
mycol = mydb["statistics"]
# 遍历集合
for item in mycol.find():
page = item['page'].zfill(3) # 用0补齐,为了合并的时候字典序不乱
if len(item['url']) > 0:
url = "http:"+item['url'][0]
response = requests.get(url)
with open('./image/statistics/'+page+'.png', 'wb') as f:
f.write(response.content)
else:
print(page) # 打印未加载出来的页面
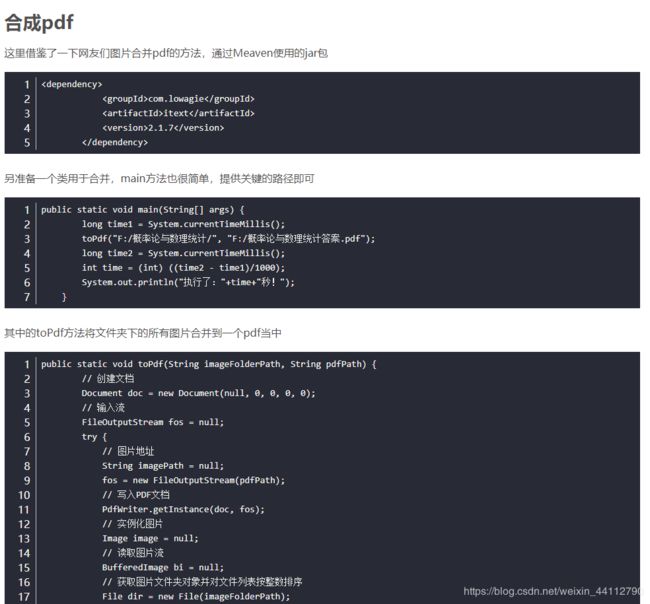
合并pdf
这里直接改了网上的一段代码
import os
from PIL import Image
# 读取图片列表
picPath = "./image/statistics"
file_list = os.listdir(picPath)
pic_name = []
im_list = []
for x in file_list:
if "jpg" in x or 'png' in x or 'jpeg' in x:
pic_name.append(picPath+"/"+x)
pic_name.sort()
# 合并为pdf
im1 = Image.open(pic_name[0])
pic_name.pop(0)
for i in pic_name:
img = Image.open(i)
if img.mode == "RGBA":
img = img.convert('RGB')
im_list.append(img)
else:
im_list.append(img)
im1.save("实用多元统计答案.pdf", "PDF", resolution=100.0, save_all=True, append_images=im_list)
旧版
网站分析
提取内嵌html
任意打开一本书,开始预览全文

F12调出chrome的控制台,开始寻找图片的链接
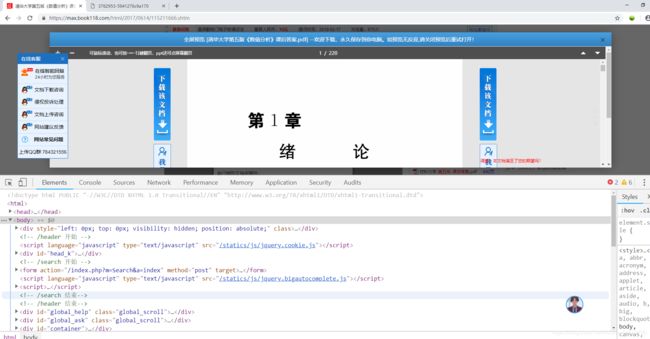
取样移动到图片上,可以看到这里获得的就是图片的链接,我们根据这个url就能获得图片资源了。

为了获取链接的方便,我准备将预览的html提取出来,直接进去爬取链接。因为这个预览其实是加载了另一个html,它的地址如下。

直接从浏览器访问这个地址,可以进入一个更简洁的预览状态。
分析内嵌html
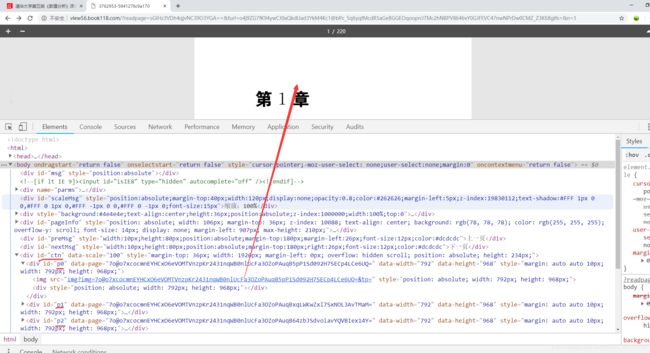
继续F12来分析网站,可以发现图片在id为ctn的div下,其中的p0、p1、p2即为对应页数。
仔细查看发现,它并未全部加载完,而且图片链接毫无规律,所以我打算用selenium翻页一张张获取
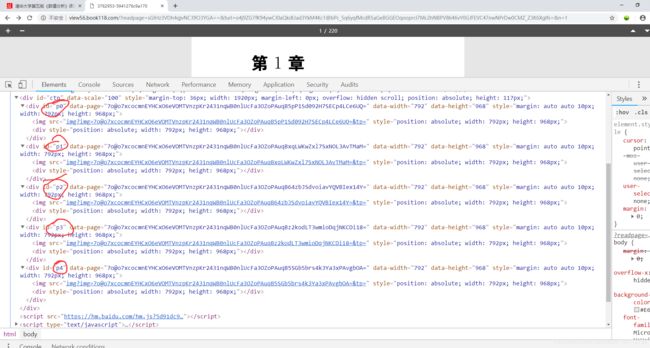
不难找到翻页按钮的id
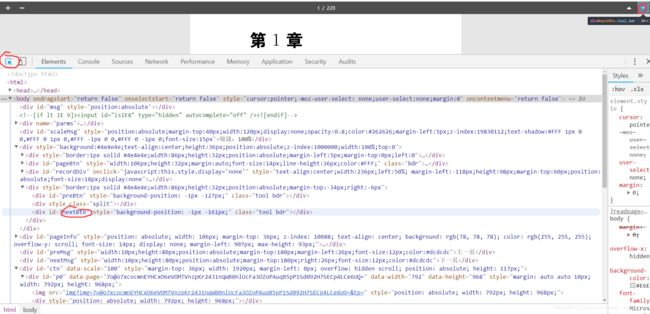
手动翻页看看,后面的图片也一点点被加载出来了。
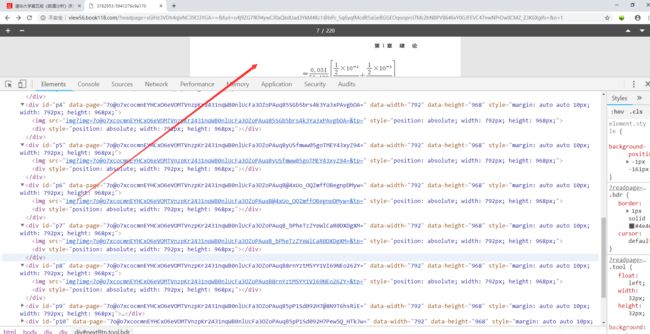
这样以来根据id的顺序,循环起来便可以获得所有的图片链接啦,不再过多分析,上代码吧。
获取图片链接
代码展示
我的代码只是获取了所有图片链接并存到MongoDB便于我java去使用,擅长python的话,可以继续用python下载这些链接的图片也不算麻烦。
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from save_mongo import save_to_mongo #这是我自己封装的工具包
browser = webdriver.Chrome()
wait = WebDriverWait(browser, 60)
# 这里的url是内嵌的html地址
browser.get('http://view56.book118.com/?readpage=sGIHz3VDh4qjvNC39O3YGA==&furl=o4j9ZG7fK94ywCJ0aQkdUad3YkM4Kc1@bPc_5q6yqfMcdR5aGeBGGEOqooprci7Mc2hNBPV8646vY0GJFEVC47nwNPrDw0CMZ_Z3K6Xglfs=&n=1')
# 获取翻页按钮
nextpage = browser.find_element_by_id('nextBtn')
for i in range(0, 220):
try:
# 获取相应页面
item = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#p'+str(i)))
)
# 获取页面中的图片链接并打印
img = item.find_element_by_tag_name('img')
url = img.get_attribute('src')
print(url)
# save_to_mongo("book118", {"page": str(i+1), "url": url}) #这是我自己封装的工具方法
nextpage.click()
except TimeoutException:
print("加载出错")
break
运行结果
可以看到图片的链接都获取到了

随便点开一个查看,就是对应页面的图片,只需要将其下载下即可

220条全都成功存到了MongoDB当中

下载并合成pdf
关于合成pdf的操作,我在之前的文档已经演示过;以后有时间再来完善python的这个操作。
https://blog.csdn.net/weixin_44112790/article/details/86775221