flowable学习(Ⅱ) ----Flowable的流程引擎配置
配置ProcessEngine
- 通过默认的流程配置文件flowable.cfg.xml配置:
虽然是一个Spring文件但是其实并非必须要使用Spring环境才可以使用,在Flowable中使用Spring的解析xml与依赖注入的功能
- 使用编码的方式:
·使用编码+配置文件,可以指定生成的配置文件的bean名
ProcessEngineConfiguration.
createProcessEngineConfigurationFromResourceDefault();
createProcessEngineConfigurationFromResource(String resource);
createProcessEngineConfigurationFromResource(String resource, String beanName);
createProcessEngineConfigurationFromInputStream(InputStream inputStream);
createProcessEngineConfigurationFromInputStream(InputStream inputStream, String beanName);
使用编码,但不使用配置文件的方式
ProcessEngineConfiguration
.createStandaloneProcessEngineConfiguration();
.createStandaloneInMemProcessEngineConfiguration();
此时ProcessEngineConfiguration使用默认配置信息,可以进行后续的修改操作,方式如:
ProcessEngineConfiguration config=ProcessEngineConfiguration.createStandaloneInMemProcessEngineConfiguration()
.setDatabaseSchemaUpdate(ProcessEngineConfiguration.DB_SCHEMA_UPDATE_TRUE)
.setJdbcUrl("jdbc:h2:mem:my-own-db;DB_CLOSE_DELAY=1000")
.setAsyncExecutorActivate(false);
使用此方式时候需要注意,数据库的表版本要与流程引擎版本一致否则报错误:FlowableWrongDbException
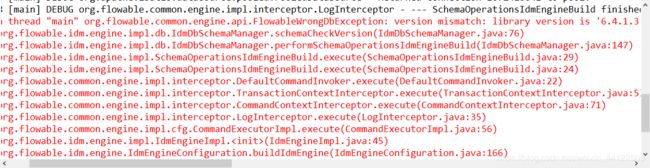
解决方式:
修改表结构,或者在后续配置的过程中,
setDatabaseSchemaUpdate(ProcessEngineConfiguration.DB_SCHEMA_UPDATE_TRUE)
使表结构自行修改
flowable.cfg.xml说明
flowable.cfg.xml文件中必须包含一个id为’processEngineConfiguration’的bean。
其class可以有四个选择,分别对应四个环境:
-
org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration:流程引擎独立运行。Flowable自行处理事务。在默认情况下,数据库检查只在引擎启动时进行(如果Flowable表结构不存在或表结构版本不对,会抛出异常)。
-
org.flowable.engine.impl.cfg.StandaloneInMemProcessEngineConfiguration:这是一个便于使用单元测试的类。Flowable自行处理事务。默认使用H2内存数据库。数据库会在引擎启动时创建,并在引擎关闭时删除。使用这个类时,很可能不需要更多的配置(除了使用任务执行器或邮件等功能时)。
-
org.flowable.spring.SpringProcessEngineConfiguration:在流程引擎处于Spring环境时使用。查看Spring集成章节了解更多信息。
-
org.flowable.engine.impl.cfg.JtaProcessEngineConfiguration:用于引擎独立运行,并使用JTA事务的情况。
配置数据库
- JDBC方式
数据库基本参数:
jdbcUrl: 数据库的JDBC URL。
jdbcDriver: 对应数据库类型的驱动。
jdbcUsername: 用于连接数据库的用户名。
jdbcPassword: 用于连接数据库的密码。
jdbcMaxActiveConnections: 连接池能够容纳的最大活动连接数量。默认值为10.
jdbcMaxIdleConnections: 连接池能够容纳的最大空闲连接数量。
jdbcMaxCheckoutTime: 连接从连接池“取出”后,被强制返回前的最大时间间隔,单位为毫秒。默认值为20000(20秒)。
jdbcMaxWaitTime: 在连接池获取连接的时间异常长时,打印日志并尝试重新获取连接。默认值为20000(20秒)。
可额外选择的参数:
databaseType:可选
oracle, postgres, mssql,db2。这个选项会决定创建、删除与查询时使用的脚本databaseSchemaUpdate: 用于设置流程引擎启动关闭时使用的数据库表结构控制策略。
false (默认): 当引擎启动时,检查数据库表结构的版本是否匹配库文件版本。版本不匹配时抛出异常。
true:构建引擎时,检查并在需要时更新表结构。表结构不存在则会创建。
create-drop:引擎创建时创建表结构,并在引擎关闭时删除表结构。
例子一:
例子二:(效率相对较高)
Flowable生成的表说明
ACT_RE_*: 'RE’代表repository。带有这个前缀的表包含“静态”信息,例如流程定义与流程资源(图片、规则等)。
ACT_RU_*: 'RU’代表runtime。这些表存储运行时信息,例如流程实例(process instance)、用户任务(user task)、变量(variable)、作业(job)等。Flowable只在流程实例运行中保存运行时数据,并在流程实例结束时删除记录。这样保证运行时表小和快。
ACT_HI_*: 'HI’代表history。这些表存储历史数据,例如已完成的流程实例、变量、任务等。
ACT_GE_*: 通用数据。在多处使用。
设置Flowable生成的数据库表,表升级
修改配置文件flowable.cfg.xml
配置异步执行器
Java EE 7下运行,容器还可以使用符合JSR-236标准的ManagedAsyncJobExecutor来管理线程。要启用这个功能,需要在配置中如下加入线程工厂:
如果没有设置线程工厂,ManagedAsyncJobExecutor实现会退化为默认实现(AsyncJobExecutor)。
普通情况下
配置历史
配置缓存
鉴于流程定义信息不会改变,为了避免每次使用流程定义时都读取数据库,所有的流程定义都会(在解析后)被缓存。默认情况下,这个缓存没有限制。要限制流程定义缓存,加上如下的参数
将默认的hashmap缓存替换为LRU缓存,以进行限制
LRU是Least Recently Used 的缩写,翻译过来就是“最近最少使用”
更多的信息的话可以看这个:LRU的Java实现
日志配置
默认使用了SLF4J。
Flowable支持SLF4J的映射诊断上下文特性。下列基本信息会与需要日志记录的信息一起,传递给底层日志实现:
- processDefinition Id 作为 mdcProcessDefinitionID
- processInstance Id 作为 mdcProcessInstanceID
- execution Id 作为 mdcExecutionId
log4j.appender.consoleAppender.layout.ConversionPattern=ProcessDefinitionId=%X{mdcProcessDefinitionID}
executionId=%X{mdcExecutionId} mdcProcessInstanceID=%X{mdcProcessInstanceID} mdcBusinessKey=%X{mdcBusinessKey} %m%n