pyhton多任务 ---线程
文章目录
- 一、什么是多任务?
- 二、并发和并行
- 三、什么是线程?
- 四、多线程
- 五、查看线程数量
- 六、证实多线程共享全局变量
- 七、多线程的传参
一、什么是多任务?
什么叫“多任务”呢?简单地说,就是操作系统可以同时运行多个任务。打个比方,你一边在用浏览器上网,一边在听MP3,一边在用Word赶作业,这就是多任务,至少同时有3个任务正在运行。还有很多任务悄悄地在后台同时运行着,只是桌面上没有显示而已。
现在,多核CPU已经非常普及了,但是,即使过去的单核CPU,也可以执行多任务。由于CPU执行代码都是顺序执行的,那么,单核CPU是怎么执行多任务的呢?
答案就是操作系统轮流让各个任务交替执行,比如说:任务1执行0.01秒,切换到任务2,任务2执行0.01秒,再切换到任务3,执行0.01秒……这样反复执行下去。表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们感觉就像所有任务都在同时执行一样。
真正的并行执行多任务只能在多核CPU上实现,但是,由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行。
多任务程序示例:
import time
import threading
# 多任务
def sing():
for i in range(3):
print("我在唱歌......")
time.sleep(2)
def dance():
for i in range(3):
print("我在跳舞......")
time.sleep(2)
def main(): # threading → 线程 看似多任务
t1 = threading.Thread(target=sing)
t2 = threading.Thread(target=dance)
t1.start() # 开始 创建出了一个线程>> 执行代码
t2.start()
# sing()
# dance()
# 运行代码的管理
if __name__ == "__main__": # 是否是在本环境在执行
main()
执行结果:

二、并发和并行
并发:指的是任务数多余cpu核数,通过操作系统的各种任务调度算法,实现用多个任务“一起”执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已)
并行:指的是任务数小于等于cpu核数,即任务真的是一起执行的
可以得出以下总结:
并发 → 假的多任务
并行 → 真的多任务
三、什么是线程?
线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程是一个进程,车间负责把资源整合到一起,是一个资源单位,而一个车间内至少有一个流水线。
·所以,进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。·
四、多线程
在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源。
使用threading模块里面的Thread类创建出实例对象, 然后通过start()方法真正的去产生一个新的线程。
解释器中来执行代码的叫做主线程。
通过start()方法创建出来的叫做子线程。
主线程会等待子线程全部结束之后才会结束。
当调用Thread的时候, 不会创建线程, 当调用Thread创建出来的实例对象的 start()方法的时候才会创建线程以及让这个线程开始运行。
五、查看线程数量
查看当前线程:
利用 threading 里面的 enumerate() 函数就能返回一个列表, 当前的线程作为单个元素存放在列表之中。
程序示例:
import threading
import time
def sing():
for i in range(1,4):
print("我在唱第%s首歌......" % i)
time.sleep(1.5)
def dance():
for i in range(1,4):
print("我在跳第%s支舞......" % i)
time.sleep(1.5)
def main():
t1 = threading.Thread(target=sing)
t2 = threading.Thread(target=dance)
t1.start()
t2.start()
while True:
length = len(threading.enumerate())
list1 = threading.enumerate()
print(list1)
time.sleep(1)
if length <= 1:
break
if __name__ == "__main__":
print("___开始____:%s" % time.ctime())
main()
time.sleep(1)
程序执行结果:
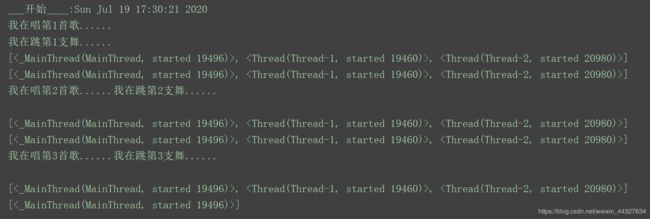
可以看出一共有三个线程:一个主线程(解释器中来执行代码的,每个程序必不可少),两个子线程( 通过两个start()方法创建出来的t1.start()和t2.start())。
六、证实多线程共享全局变量
在一个进程内的所有线程共享全局变量,很方便在多个线程间共享数据
程序示例:
import threading
import time
num1 = 0
def demo1():
global num1
num1 += 1
print("在demo1中,num1的值是:",num1)
def demo2():
print("在demo2中,num1的值是:",num1)
def main(): #主程序函数
t1 = threading.Thread(target=demo1)
t2 = threading.Thread(target=demo2)
t1.start()
time.sleep(1)
t2.start()
time.sleep(1)
print("在main中,num1的值是:",num1)
# 运行代码管理
if __name__ == "__main__":
main()
执行结果:
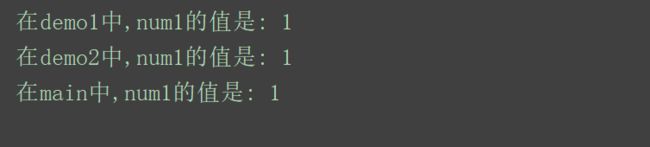
可以看到,全局变量num1初始等于0,在函数demo1中进行了加一操作即得到num1=1,而在函数demo2和main函数中调用num1打印出来的结果都是1,可见多线程是共享全局变量的。
这里也可以看出其缺点,线程对全局变量随意修改可能造成多线程之间对全局变量的混乱(即线程非安全)。
七、多线程的传参
多线程如何传参?我们进入threading模块内部,会看到:

其中有一个args = () ,我们推测可以以元组形式传参,下面举个栗子:比如说,我们想传一个列表
list1 = [1,2,3] 并在一个线程中对其进行操作并打印,在另一个线程中打印此列表。
程序示例:
import threading
import time
def demo1(a):
a.append(4) # list1 = [1,2,3] --》 list1 = [1,2,3,4]
print("在demo1中,list1是:",str(a))
def demo2(a):
print("在demo2中,list1是:",str(a))
def main(): #主程序函数
list1 = [1,2,3]
# 在target执行将来执行这个子线程创建之后去哪里执行代码
# args指定将来调用函数的时候, 将什么数据传递过去
t1 = threading.Thread(target=demo1,args=(list1,)) # 元组
t2 = threading.Thread(target=demo2,args=(list1,))
t1.start()
time.sleep(1)
t2.start()
time.sleep(1)
print("在main中,list1是:", list1)
# 运行代码管理
if __name__ == "__main__":
main()
执行结果:

初学者可能会有疑问,那么,多线程共享全局变量的意义何在?先举个小栗子应用场景,比如写一个爬虫需要爬取海量数据,可以简单地分成三个部分,一部分用来抓取数据,一部分用来负责清洗数据,另一部分负责保存数据,使用单任务只能全部抓取完数据后再进行清洗,清洗完数据后才能保存,而使用多线程的时候可以先把一部分抓取来的数据进行清洗,清洗过的一部分数据拿来先保存,这样就比单任务的提高了很多效率。