来点前端爬虫!~
原文来自 : https://segmentfault.com/a/1190000014811373?utm_source=tag-newest
一个简单的百度新闻爬虫
确定爬取对象(网站/页面)
百度新闻 (
http://news.baidu.com/)
确定开发语言、框架、工具等
node.js (express) + WebStorm
Let’s start
初始化package.json
- 新建项目目录BaiduNewsSpider
- 在DOS命令行中进入项目根目录 baiduNews
- 执行npm init,初始化package.json文件
- 安装依赖
npm isntall express npm isntallsuperagent npm isntall cheerio
依赖说明
express使用express来搭建一个简单的Http服务器。当然,你也可以使用node中自带的http模块
superagentsuperagent是node里一个非常方便的、轻量的、渐进式的第三方客户端请求代理模块,用他来请求目标页面
cheeriocheerio相当于node版的jQuery,用过jQuery的同学会非常容易上手。它主要是用来获取抓取到的页面元素和其中的数据信息
开始coding
一、使用express启动一个简单的本地Http服务器
1、 在项目根目录下创建index.js文件(后面都会在这个index文件中进行coding)
2、 创建好index.js后,我们首先实例化一个express对象,用它来启动一个本地监听3000端口的Http服务。
const express = require('express'); //导入express模块
const app = express();
let server = app.listen(3000, function () {
let host = server.address().address;
console.log("host的结果为=", host);
let port = server.address().port;
console.log('Your App is running at http://%s:%s', host, port);
});
上述代码中
let host = server.address().address;会读取本机的ip地址,由于windows有个优先解析列表,当ipv6的优先级高于ipv4时, 会出现:
> baidunews@1.0.0 start G:\BaiduNewsSpider
> node index.js
host的结果为= ::
Your App is running at http://:::3000
解决方法有两种:
- 第一种修改注册表 : 详情请移步博客win10 localhost 解析为::1 的解决办法
- 第二种,直接使用字符串”localhost“:
const express = require('express');
const app = express();
let server = app.listen(3000, function () {
let port = server.address().port;
console.log('Your App is running at http://%s:%s', "localhost", port);
});
对,就是这么简单,不到10行代码,搭建启动一个简单的本地Http服务。
3、按照国际惯例,希望在访问本机地址http://localhost:3000的时候,这个服务能给我们返回一个Hello World!在index.js中加入如下代码:
app.get('/', function (req, res) {
res.send('Hello World!');
});
此时,在DOS中项目根目录baiduNews下执行node index.js,让项目跑起来。之后,打开浏览器,访问http://localhost:3000,你就会发现页面上显示’Hellow World!'字样。
这样,在后面我们获取到百度新闻首页的信息后,就可以在访问http://localhost:3000时看到这些信息。
二、抓取百度新闻首页的新闻信息
百度新闻首页大体上分为“热点新闻”、“本地新闻”、“国内新闻”、“国际新闻”…等。这次我们先来尝试抓取左侧“热点新闻”和下方的“本地新闻”两处的新闻数据。
审查页面元素,经过查看左侧“
热点新闻”信息所在DOM的结构,所有的“热点新闻”信息用jQuery的选择器表示为:#pane-news ul li a。
// 引入所需要的第三方包
const superagent= require('superagent');
let hotNews = []; // 热点新闻
let localNews = []; // 本地新闻
/**
* index.js
* [description] - 使用superagent.get()方法来访问百度新闻首页
*/
superagent.get('http://news.baidu.com/').end((err, res) => {
if (err) {
// 如果访问失败或者出错,会这行这里
console.log(`热点新闻抓取失败 - ${err}`)
} else {
// 访问成功,请求http://news.baidu.com/页面所返回的数据会包含在res
// 抓取热点新闻数据
hotNews = getHotNews(res)
}
});
3、获取页面信息后,我们来定义一个函数getHotNews()来抓取页面内的“热点新闻”数据。
/**
* index.js
* [description] - 抓取热点新闻页面
*/
// 引入所需要的第三方包
const cheerio = require('cheerio');
let getHotNews = (res) => {
let hotNews = [];
// 访问成功,请求http://news.baidu.com/页面所返回的数据会包含在res.text中。
/* 使用cheerio模块的cherrio.load()方法,将HTMLdocument作为参数传入函数
以后就可以使用类似jQuery的$(selectior)的方式来获取页面元素
*/
let $ = cheerio.load(res.text);
// 找到目标数据所在的页面元素,获取数据
$('div#pane-news ul li a').each((idx, ele) => {
// cherrio中$('selector').each()用来遍历所有匹配到的DOM元素
// 参数idx是当前遍历的元素的索引,ele就是当前便利的DOM元素
let news = {
title: $(ele).text(), // 获取新闻标题
href: $(ele).attr('href') // 获取新闻网页链接
};
hotNews.push(news) // 存入最终结果数组
});
return hotNews
};
这里要多说几点:
async/await据说是异步编程的终级解决方案,它可以让我们以同步的思维方式来进行异步编程。Promise解决了异步编程的“回调地狱”,async/await同时使异步流程控制变得友好而有清晰,有兴趣的同学可以去了解学习一下,真的很好用。superagent模块提供了很多比如get、post、delte等方法,可以很方便地进行Ajax请求操作。在请求结束后执行.end()回调函数。.end()接受一个函数作为参数,该函数又有两个参数error和res。请求失败,error会包含返回的错误信息,请求成功,error值为null,返回的数据会包含在res参数中。
cheerio模块的.load()方法,将HTML document作为参数传入函数,以后就可以使用类似jQuery的$(selectior)的方式来获取页面元素。同时可以使用类似于jQuery中的.each()来遍历元素。此外,还有很多方法,大家可以自行Google/Baidu。
4、将抓取的数据返回给前端浏览器
前面,const app = express(); 实例化了一个express对象app。
app.get(’’, async() => {})接受两个参数,第一个参数接受一个String类型的路由路径,表示Ajax的请求路径。第二个参数接受一个函数Function,当请求此路径时就会执行这个函数中的代码。
/**
* [description] - 根路由
*/
// 当一个get请求 http://localhost:3000时,就会后面的async函数
app.get('/', async (req, res, next) => {
res.send(hotNews);
});
在DOS中项目根目录baiduNews下执行node index.js,让项目跑起来。之后,打开浏览器,访问http://localhost:3000,你就会发现抓取到的数据返回到了前端页面。我运行代码后浏览器展示的返回信息如下:
图片涉政不能贴出来
OK!!这样,一个简单的百度“热点新闻”的爬虫就大功告成啦!!
简单总结一下,其实步骤很简单:
- express启动一个简单的Http服务
- 分析目标页面DOM结构,找到所要抓取的信息的相关DOM元素
- 使用superagent请求目标页面
- 使用cheerio获取页面元素,获取目标数据
- 返回数据到前端浏览器
现在,继续我们的目标,抓取“本地新闻”数据(编码过程中,我们会遇到一些有意思的问题)
有了前面的基础,我们自然而然的会想到利用和上面相同的方法“本地新闻”数据。
1、 分析页面中“本地新闻”部分的DOM结构,如下图:
F12打开控制台,审查“本地新闻”DOM元素,我们发现,“本地新闻”分为两个主要部分,“左侧新闻”和右侧的“新闻资讯”。这所有目标数据都在id为#local_news的div中。
“左侧新闻”数据又在id为#localnews-focus的ul标签下的li标签下的a标签中,包括新闻标题和页面链接。
“本地资讯”数据又在id为#localnews-zixun的div下的ul标签下的li标签下的a标签中,包括新闻标题和页面链接。
2、OK!分析了DOM结构,确定了数据的位置,接下来和爬取“热点新闻”一样,按部就班,定义一个getLocalNews()函数,爬取这些数据。
/**
* [description] - 抓取本地新闻页面
*/
let getLocalNews = (res) => {
let localNews = [];
let $ = cheerio.load(res);
// 本地新闻
$('ul#localnews-focus li a').each((idx, ele) => {
let news = {
title: $(ele).text(),
href: $(ele).attr('href'),
};
localNews.push(news)
});
// 本地资讯
$('div#localnews-zixun ul li a').each((index, item) => {
let news = {
title: $(item).text(),
href: $(item).attr('href')
};
localNews.push(news);
});
return localNews
};
对应的,在superagent.get()中请求页面后,我们需要调用getLocalNews()函数,来爬去本地新闻数据。
superagent.get()函数修改为:
superagent.get('http://news.baidu.com/').end((err, res) => {
if (err) {
// 如果访问失败或者出错,会这行这里
console.log(`热点新闻抓取失败 - ${err}`)
} else {
// 访问成功,请求http://news.baidu.com/页面所返回的数据会包含在res
// 抓取热点新闻数据
hotNews = getHotNews(res)
localNews = getLocalNews(res)
}
});
同时,我们要在app.get()路由中也要将数据返回给前端浏览器。app.get()路由代码修改为:
/**
* [description] - 跟路由
*/
// 当一个get请求 http://localhost:3000时,就会后面的async函数
app.get('/', async (req, res, next) => {
res.send({
hotNews: hotNews,
localNews: localNews
});
});
编码完成,激动不已!!DOS中让项目跑起来,用浏览器访问http://localhost:3000
一个有意思的问题
为了找到原因,首先,我们看看用superagent.get(‘http://news.baidu.com/’).end((err, res) => {})请求百度新闻首页在回调函数.end()中的第二个参数res中到底拿到了什么内容?
// 新定义一个全局变量 pageRes
let pageRes = {}; // supergaent页面返回值
// superagent.get()中将res存入pageRes
superagent.get('http://news.baidu.com/').end((err, res) => {
if (err) {
// 如果访问失败或者出错,会这行这里
console.log('热点新闻抓取失败 - ${err}')
} else {
// 访问成功,请求http://news.baidu.com/页面所返回的数据会包含在res
// 抓取热点新闻数据
// hotNews = getHotNews(res)
// localNews = getLocalNews(res)
pageRes = res
}
});
// 将pageRes返回给前端浏览器,便于查看
app.get('/', async (req, res, next) => {
res.send({
// {}hotNews: hotNews,
// localNews: localNews,
pageRes: pageRes
});
});

可以看到,返回值中的text字段应该就是整个页面的HTML代码的字符串格式。为了方便观察,可以直接把这个text字段值返回给前端浏览器,这样我们就能够清晰地看到经过浏览器渲染后的页面。
修改给前端浏览器的返回值
app.get('/', async (req, res, next) => {
res.send(
pageRes.text // 注意此处返回的不是字典形式,删除{ }
)
}
访问浏览器http://localhost:3000,页面展示如下内容:
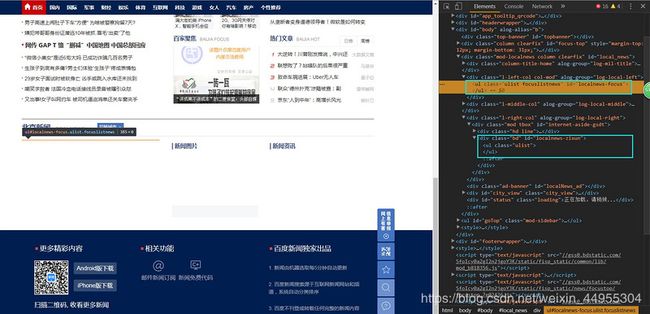
审查元素才发现,原来我们抓取的目标数据所在的DOM元素中是空的,里面没有数据!
到这里,一切水落石出!在我们使用superagent.get()访问百度新闻首页时,res中包含的获取的页面内容中,我们想要的“本地新闻”数据还没有生成,DOM节点元素是空的,所以出现前面的情况!抓取后返回的数据一直是空数组[ ]。

在控制台的Network中我们发现页面请求了一次这样的接口:
http://localhost:3000/widget?id=InternationalNews&t=1589378105207,接口状态 404。
这应该就是百度新闻获取“本地新闻”的接口,到这里一切都明白了!“本地新闻”是在页面加载后动态请求上面这个接口获取的,所以我们用superagent.get()请求的页面再去请求这个接口时,接口URL中hostname部分变成了本地IP地址,而本机上没有这个接口,所以404,请求不到数据。
找到原因,我们来想办法解决这个问题!!
- 直接使用superagent访问正确合法的百度“本地新闻”的接口,获取数据后返回给前端浏览器。
- 使用第三方npm包,模拟浏览器访问百度新闻首页,在这个模拟浏览器中当“本地新闻”加载成功后,抓取数据,返回给前端浏览器。
以上方法均可,我们来试试比较有意思的第二种方法。
使用Nightmare自动化测试工具
Electron可以让你使用纯JavaScript调用Chrome丰富的原生的接口来创造桌面应用。你可以把它看作一个专注于桌面应用的Node.js的变体,而不是Web服务器。其基于浏览器的应用方式可以极方便的做各种响应式的交互
Nightmare是一个基于Electron的框架,针对Web自动化测试和爬虫,因为其具有跟PlantomJS一样的自动化测试的功能可以在页面上模拟用户的行为触发一些异步数据加载,也可以跟Request库一样直接访问URL来抓取数据,并且可以设置页面的延迟时间,所以无论是手动触发脚本还是行为触发脚本都是轻而易举的。
安装依赖
// 安装nightmare
yarn add nightmare
为获取“本地新闻”,继续coding…
给index.js中新增如下代码:
const Nightmare = require('nightmare'); // 自动化测试包,处理动态页面
const nightmare = Nightmare({ show: true }); // show:true 显示内置模拟浏览器
/**
* [description] - 抓取本地新闻页面
* [nremark] - 百度本地新闻在访问页面后加载js定位IP位置后获取对应新闻,
* 所以抓取本地新闻需要使用 nightmare 一类的自动化测试工具,
* 模拟浏览器环境访问页面,使js运行,生成动态页面再抓取
*/
// 抓取本地新闻页面
nightmare
.goto('http://news.baidu.com/')
.wait("div#local_news")
.evaluate(() => document.querySelector("div#local_news").innerHTML)
.then(htmlStr => {
// 获取本地新闻数据
localNews = getLocalNews(htmlStr)
})
.catch(error => {
console.log(`本地新闻抓取失败 - ${error}`);
})
修改getLocalNews()函数为:
/**
* [description]- 获取本地新闻数据
*/
let getLocalNews = (htmlStr) => {
let localNews = [];
let $ = cheerio.load(htmlStr);
// 本地新闻
$('ul#localnews-focus li a').each((idx, ele) => {
let news = {
title: $(ele).text(),
href: $(ele).attr('href'),
};
localNews.push(news)
});
// 本地资讯
$('div#localnews-zixun ul li a').each((index, item) => {
let news = {
title: $(item).text(),
href: $(item).attr('href')
};
localNews.push(news);
});
return localNews
}
修改app.get('/')路由为:
/**
* [description] - 跟路由
*/
// 当一个get请求 http://localhost:3000时,就会后面的async函数
app.get('/', async (req, res, next) => {
res.send({
hotNews: hotNews,
localNews: localNews
})
});
此时,DOS命令行中重新让项目跑起来,浏览器访问https://localhost:3000,看看页面展示的信息,看是否抓取到了“本地新闻”数据!
至此,一个简单而又完整的抓取百度新闻页面“热点新闻”和“本地新闻”的爬虫就大功告成啦!!
最后总结一下,整体思路如下:
- express启动一个简单的Http服务
- 分析目标页面DOM结构,找到所要抓取的信息的相关DOM元素
- 使用superagent请求目标页面
- 动态页面(需要加载页面后运行JS或请求接口的页面)可以使用Nightmare模拟浏览器访问
- 使用cheerio获取页面元素,获取目标数据
完整代码如下:
const express = require('express');
const app = express();
let server = app.listen(3000, function () {
let port = server.address().port;
console.log('Your App is running at http://%s:%s', "localhost", port);
});
// 引入所需要的第三方包
const superagent = require('superagent');
let hotNews = []; // 热点新闻
let localNews = []; // 本地新闻
/**
* index.js
* [description] - 使用superagent.get()方法来访问百度新闻首页
*/
superagent.get('http://news.baidu.com/').end((err, res) => {
if (err) {
// 如果访问失败或者出错,会这行这里
console.log('热点新闻抓取失败 - ${err}')
} else {
// 访问成功,请求http://news.baidu.com/页面所返回的数据会包含在res
// 抓取热点新闻数据
hotNews = getHotNews(res);
}
});
const cheerio = require('cheerio');
let getHotNews = (res) => {
let hotNews = [];
// 访问成功,请求http://news.baidu.com/页面所返回的数据会包含在res.text中。
/* 使用cheerio模块的cherrio.load()方法,将HTMLdocument作为参数传入函数
以后就可以使用类似jQuery的$(selectior)的方式来获取页面元素
*/
let $ = cheerio.load(res.text);
// 找到目标数据所在的页面元素,获取数据
$('div#pane-news ul li a').each((idx, ele) => {
// cherrio中$('selector').each()用来遍历所有匹配到的DOM元素
// 参数idx是当前遍历的元素的索引,ele就是当前便利的DOM元素
let news = {
title: $(ele).text(), // 获取新闻标题
href: $(ele).attr('href') // 获取新闻网页链接
};
hotNews.push(news) // 存入最终结果数组
});
return hotNews
};
const Nightmare = require('nightmare'); // 自动化测试包,处理动态页面
const nightmare = Nightmare({show: false}); // show:true 显示内置模拟浏览器
/**
* [description] - 抓取本地新闻页面
* [nremark] - 百度本地新闻在访问页面后加载js定位IP位置后获取对应新闻,
* 所以抓取本地新闻需要使用 nightmare 一类的自动化测试工具,
* 模拟浏览器环境访问页面,使js运行,生成动态页面再抓取
*/
// 抓取本地新闻页面
nightmare
.goto('http://news.baidu.com/')
.wait("div#local_news")
.exists("div#local_news")
.evaluate(() => document.querySelector("div#local_news").innerHTML)
.then(htmlStr => {
// 获取本地新闻数据
localNews = getLocalNews(htmlStr);
console.log('本地新闻抓取成功');
})
.catch(error => {
console.log('本地新闻抓取失败 - ${error}');
});
/**
* [description]- 获取本地新闻数据
*/
let getLocalNews = (htmlStr) => {
let localNews = [];
let $ = cheerio.load(htmlStr);
// 本地新闻
$('ul#localnews-focus li a').each((idx, ele) => {
let news = {
title: $(ele).text(),
href: $(ele).attr('href'),
};
localNews.push(news)
});
// 本地资讯
$('div#localnews-zixun ul li a').each((index, item) => {
let news = {
title: $(item).text(),
href: $(item).attr('href')
};
localNews.push(news);
});
return localNews
};
app.get('/', async (req, res, next) => {
res.send({
hotNews: hotNews,
localNews: localNews
});
});