UNIX网络编程总结
作为一名现代开发人员,在日常的开发中不可避免的会接触到网络编程。网络编程已经成为现代开发人员不可或缺的基本素养,网络编程本身又绕不开socket与tcp。虽然各个语言都提供了丰富的网络库,开发人员直接使用socket api的机会很少,但是对于socket api的行为与tcp协议栈的交互过程也应该有所了解。这样对于日常的开发设计与故障诊断都有所帮助。
本文将以图示的方式讨论了socket函数的行为与tcp之间的交互。介绍了《UNIX网络编程卷1:套接字联网API》中的补充总结。
例子使用unpv13e/tcpcliserv。异常情况在Centos7.x86_64上进行测试。所码出的文字尽量做到严谨,但限于能力有限,如有错误,请指正,以防误导他人。
下文首先介绍socket api正常的使用情况与tcp之间的交互过程,再对各个异常情况分别描述。
正常情况
我们使用echo服务例子来介绍正常情况下,socket api行为与tcp协议之间交互过程。
由客户端发送数据,服务端回传结果。数据收发函数统一使用阻塞read/write,也可以使用recv/send,recvmsg/sendmsg等。此例很多处理不够严谨,不可作为生产代码流程使用。
先上图:
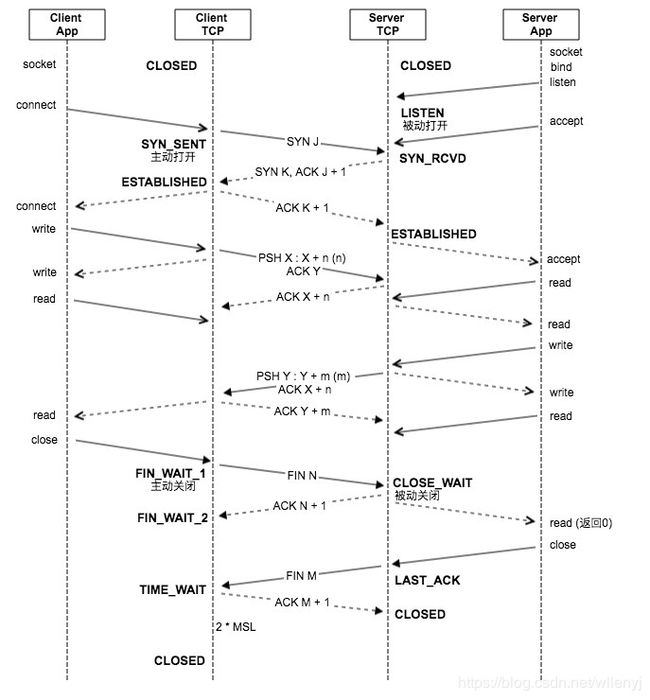
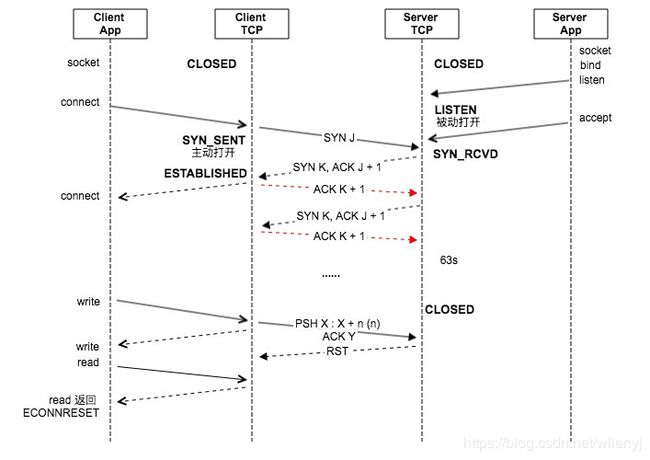
图中socket api使用默认阻塞模式。client app指客户端应用程序,即直接调用socket api的进程。client TCP指client端的tcp协议栈,即client端操作系统内核。server端相同。
连接的建立过程
- server app创建listening socket,对监听端口号进行bind(介绍bind的文章),然后调用listen监听,此时server TCP从初始状态 被动打开 ,进入LISTEN状态,等待外来的连接。listen函数会使内核协议栈创建半连接队列与全连接队列,其长度受backlog参数影响。
- server app调用accept阻塞,等待全连接队列有可用连接。
- client app创建socket,调用connect阻塞。client TCP从初始状态 主动打开 到SYN_SENT状态,此时,client tcp向server tcp发送SYN报文( 第一次握手 )。
- server TCP收到client tcp发来的SYN后,将纪录放入半连接队列,状态转换为SYN_RCVE,并回复SYN+ACK ( 第二次握手 )。连接队列满见下文。
- client TCP收到后SYN+ACK后,进入ESTABLISHED,向server TCP回复ACK ( 第三次握手 )。此时client app的connect函数返回。
- server TCP收到第三次握手的ACK后,将该纪录从半连接队列移到全连接队列,进入ESTABLISHED状态。此时,server app阻塞的accept将取出全连接队列头纪录,创建connected socket返回,供server app收发数据。全连接队列满的情况见下文。
至此连接建立完成,之后便可使用建立好的socket进行数据收发了。tcp数据传输是一个很大的主题,这里只关心与socket api交互过程。
数据收发
- client app端在connect返回后,就可以调用write写入数据了,client TCP发送PSH报文。
- 阻塞:write将阻塞到写入全部数据到 发送缓冲区 返回。如果被信号中断,返回值可能小于传入的长度参数(short write),造成写入部分数据。errno为EINTR。以下是man 7 signal的描述。
If a blocked call to one of the following interfaces is interrupted by a signal handler, then the call will be automatically restarted after the signal handler returns if the SA_RESTART flag was used; otherwise the call will fail with the error EINTR: * read(2), readv(2), write(2), writev(2), and ioctl(2) calls on "slow" devices. A "slow" device is one where the I/O call may block for an indefinite time, for example, a terminal, pipe, or socket. (A disk is not a slow device according to this definition.) If an I/O call on a slow device has already transferred some data by the time it is interrupted by a signal handler, then the call will return a success status (normally, the number of bytes transferred).- 非阻塞:write能写入尽量多数据到 发送缓冲区 后返回。
- server TCP收到PSH后将数据放入 接收缓冲 区中,回复ACK。server app端调用read读取接收缓冲中的数据。
- read函数同样有读出的数据小于期望读取的长度,也叫 短读。不论阻塞还是非阻塞。原因与write大致相同。
日常开发中所说的 沾包 与 分包 就是短读短写的直接产物。下面用一张图概括一下沾包分包的产生。
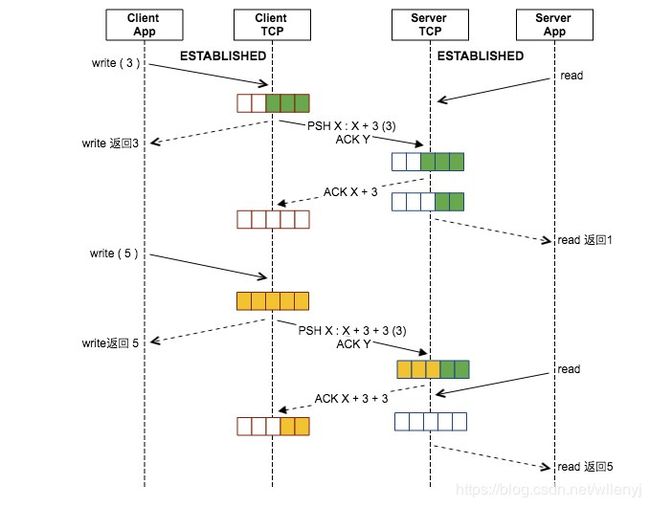
- client发送了3长度数据,到了server端接收缓冲中。由于server TCP回复了ACK,所以client TCP发送缓冲被清空。
- server app由于中断或其他原因,只读出了1长度数据,短读造成分包。
- 这时client app又写入了5长度数据到发送缓冲中,但是server TCP此时只能接收3长度,然后回复3长度的ACK。
- server app这时再读取会读出5长度的数据,造成沾包。
所以,在开发阶段与应用层协议设计时要考虑这些情况,比如要增加循环写入来避免短写,增加包体长度字段来处理短读问题。
关闭阶段
先调用close的一方,称为 主动关闭,另一方为 被动关闭:
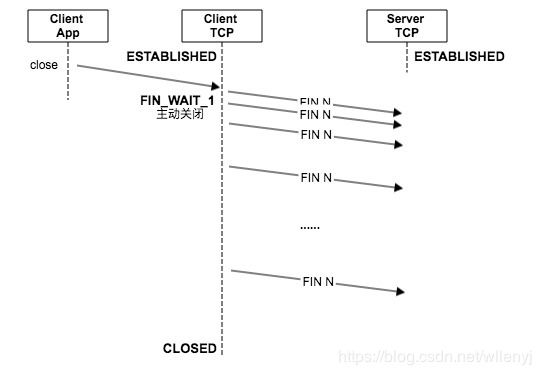
- client app调用close函数(不考虑SO_LINGER),将socket的引用计数减1立即返回。一般情况,socket没有引用,client TCP将尝试将发送缓冲区中的数据发送完成,然后执行终止序列发送FIN报文,执行主动关闭。此时状态进入FIN_WAIT_1。
- server TCP收到FIN后,执行被动关闭。状态变为CLOSE_WAIT。若此时有阻塞read,将返回0。server TCP返回ACK报文。此时server app仍然可使用该connected socket发送数据,但一般将调用close关闭该socket,server TCP也将发送FIN,并进入LAST_ACK。
- client TCP先收到ACK后,状态变为FIN_WAIT_2。而后收到对端发来的FIN报文,状态变为TIME_WAIT,并回复ACK。然后等待2倍MSL时间后,状态变为CLOSED,释放socket资源。
- server TCP收到最后的ACK后,状态变为CLOSED,释放socket资源。
异常情况
异常情况总结有以下几种:
- 对端app异常崩溃。
- 对端主机崩溃或不可达。
- 半连接队列满。
- 全连接队列满。
其中1/2可能发生在的任何环节,其中大部分都会触发超时重传机制。所以需要先介绍下tcp的重传。
我们知道tcp在发送一个包以后,都需要ACK确认。如果没有收到ACK就会发生重传。而重传又分为两种重传, 基于定时器重传 和 快速重传 。快速重传大部分是处理包乱序的情况。我们讨论的异常情况一般都是没有后续包的情况。基于定时器重传又叫超时重传,要基于一个超时时间,这个时间就叫做 RTO (Retransmission Timeout)。RTO的计算又要基于 RTT (round-trip-time)来评估初始值。在每次超时后,以指数增长RTO用于下次的超时时间。
- 内核在超时次数达到一定数量后,会调用tcp_write_err,设置待处理错误为ETIMEDOUT,关闭socket,唤醒阻塞在该socket的系统调用,或唤醒select。这里如果没有阻塞的读写操作也没用select等非阻塞的io复用的话,就得不到通知。所以建议日常开发尽量使用select等io复用,这样在发生错误情况时,select会被唤醒。
对端app异常崩溃
以server app崩溃为例:
如果client app在 server app在崩溃后调用connect,server TCP将回复RST报文,connect返回ECONNREFUSED错误。
server app建连后崩溃:
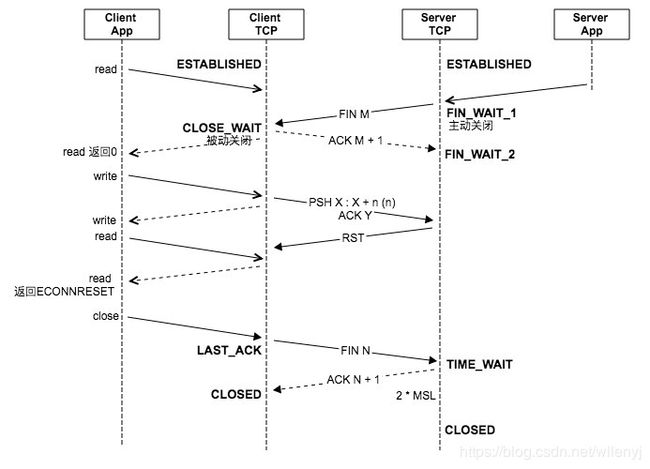
- server app崩溃,server端内核会发现,然后由server TCP向client发送FIN报文,就像tcp连接终止的前半部分。
- 但client app是无法知道对端是正常close,还是因为崩溃了。
- client TCP响应ACK,状态变为CLOSE_WAIT。若此时client app有阻塞read,会返回0表示EOF。此时属于半关闭,client app仍可向socket写入数据,client TCP发送PSH报文。
- 由于server app已经崩溃,server TCP收到PSH后,将回复RST。
- client TCP收到RST后,client app之后读操作都将返回ECONNRESET错误。如果是写操作将发生SIGPIPE信号,如果有处理该信号,写操作将返回EPIPE错误。
- client app调用close,关闭连接,执行最后挥手。
- 如果client在对端崩溃后,没有进行读写,那client app将永远不会知道对端已经崩溃了。
- 如果server app崩溃后又重启了,client app再进行写时,由于server TCP无法找到之前已经销毁的socket,所以同样会发送RST。
图中为了说明问题,实际中read返回EOF,就不应该再此调用read了。
对端主机崩溃
还以server主机崩溃为例。server主机崩溃意味着server TCP失去响应,client TCP发送的任何数据报都得不到ACK。这和对端网络不可达其实是相同的。都会引起client TCP的超时重传。崩溃发生在不同的阶段,判断重传失败的策略有些细微差别。
建连阶段
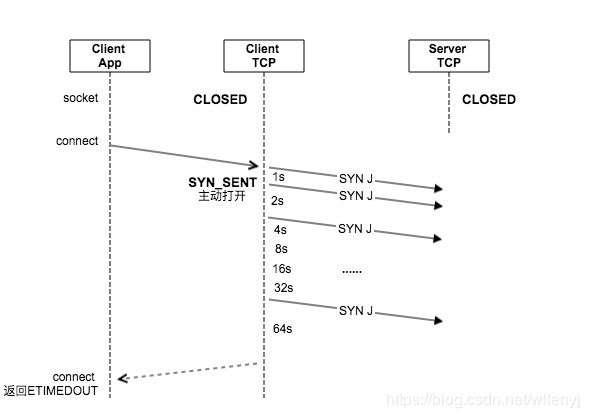
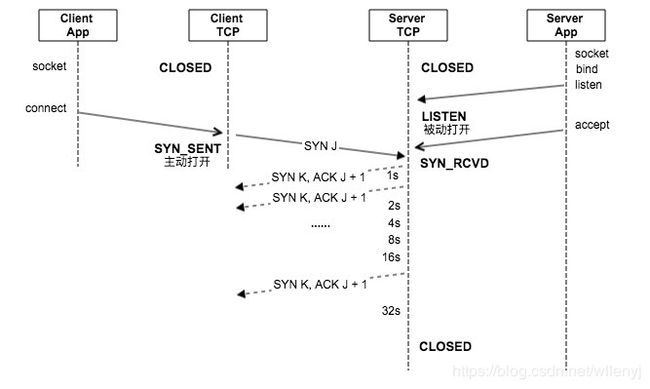
SYN无回复
当client app调用connect函数,发送SYN后,服务器主机崩溃,或者干脆网络不可达。
使用iptables drop 掉SYN包进行测试。
iptables -A INPUT -p tcp --dport 9877 --syn -j DROP

从tcpdump抓包看到,client发送SYN后,又连续发送了6个包,每个时间间隔为1, 2, 4, 8, 16, 32s,之后又等了64s,connect函数返回ETIMEDOUT。总共等了127s。
$ date; ./tcpcli01 127.0.0.1; date
Wed Jul 11 00:46:24 CST 2018
connect error: Connection timed out
Wed Jul 11 00:48:31 CST 2018
这个例子中有两个问题:
- 测试的抓包结果和其他文章中描述的(总共等待63s,没有最后的64s)不一样,是因为alios做过修改吗?有待验证。
- UNP中说,重传阶段如果某个中间路由器判定服务器主机不可达,从而响应一个"destination unreachable"(目的地不可达) ICMP消息,那么所返回的错误是EHOSTUNREACH或ENETUNREACH。我是没有遇到这中情况。
重传次数6,是net.ipv4.tcp_syn_retries = 6参数控制的。
首次超时时间1s,由于SYN发出后,ACK还没有收到所以无法计算RTO,所以使用了初始设置,具体实现。
#define TCP_TIMEOUT_INIT ((unsigned)(1*HZ)) /* RFC6298 2.1 initial RTO value */
随带介绍一下SYN + ACK后无回复的情况。
SYN + ACK无回复
当client app调用connect函数,client TCP发送SYN,server TCP回复了SYN + ACK,这时client主机崩溃。我们使用
iptables -A INPUT -p tcp --dport 9877 --tcp-flags ALL ACK -j DROP
屏蔽掉client TCP回复的ACK包,进行抓包:
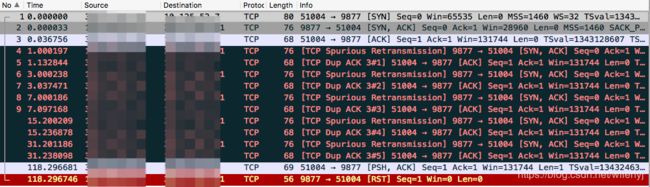
由于net.ipv4.tcp_synack_retries = 5,所以server TCP重传了5次。第6次超时后,tcp_write_err。
期间server端运行netstat,socket在SYN_RECV状态停留63s后消失。
netstat -npt | grep 9877
tcp 0 0 server-ip:9877 client-ip:51151 SYN_RECV -
示意图:
著名的SYN Flood攻击,便是此种情况。
数据收发阶段

在数据收发阶段的超时重传,超时时间使用到了RTO的计算,而重传次数受
net.ipv4.tcp_retries1 = 3
net.ipv4.tcp_retries2 = 15
这两个参数约束,具体计算方法就不赘述了。可以参考源码,或1 2。
由于此例使用MacOS测试,结果与linux有些出入,但原理相同。
- 重传了13次,总共32s,最后向对端发送RST(虽然没什么用)。
- 文章中中提到放弃重传的最大时间上限是924.6s(15min),也就是说app有可能在15min后才能感知到错误。
- 可以看到首次重传MacOS为120ms,linux为TCP_RTO_MIN(200ms)。
关闭阶段
关闭阶段对于app端的影响不是很大,但是对于高并发大请求量服务器却至关重要。
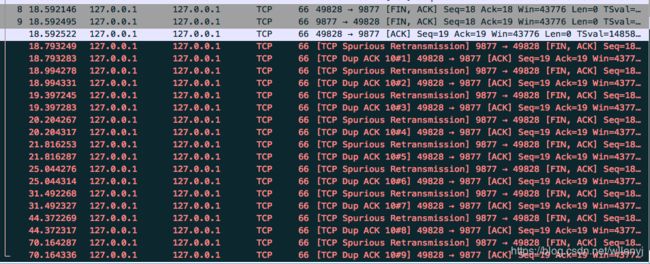
第一次挥手无回复
client调用close,client TCP进入FIN_WAIT_1后收不到ACK。tcp协议栈使用net.ipv4.tcp_orphan_retries = 0配置项来约束了FIN包的重传次数。源码,如果没有设置,将使用默认值8。
使用iptables进行测试:
iptables -A INPUT -p tcp --dport 9877 --tcp-flags ALL FIN,ACK -j DROP

17:09:40 tcp 0 1 127.0.0.1:51393 127.0.0.1:9877 FIN_WAIT1
......
17:11:22 tcp 0 1 127.0.0.1:51393 127.0.0.1:9877 FIN_WAIT1
- 这里抓包结果为比源码多一次,9次重传,总共大约102s。
第二次挥手后无回复

此情况不会造成重传,socket停留在FIN_WAIT_2的时间受net.ipv4.tcp_fin_timeout = 60控制。
可以使用脚本测试:
while sleep 1; do
netstat -ant | grep FIN_WAIT2 | while read content; do
echo -n $(date +"%T") ""
echo $content
done
done
观察结果可得到时间大约为1min。
第三次挥手后无回复
在发送完第三次挥手即FIN后,该端状态为LAST_ACK,之后对端崩溃或网络不可达造成接收不到最后的ACK。这时会触发重传FIN。达到重传上限后,tcp_write_err。
15:35:51 tcp 0 1 127.0.0.1:9877 127.0.0.1:49828 LAST_ACK
.....
15:37:33 tcp 0 1 127.0.0.1:9877 127.0.0.1:49828 LAST_ACK
- 重传9次,总共大约103s,首次重传200ms。与FIN_WAIT_1结果相同。看来他们的逻辑是相同的。
验证一下:
- 将net.ipv4.tcp_orphan_retries设置为4,sysctl -w net.ipv4.tcp_orphan_retries=4。
- 分别抓包查看FIN_WAIT_1和LAST_ACK的停留时间。
- FIN_WAIT_1

17:25:51 tcp 0 1 127.0.0.1:51659 127.0.0.1:9877 FIN_WAIT1
....
17:26:02 tcp 0 1 127.0.0.1:51659 127.0.0.1:9877 FIN_WAIT1
- LAST_ACK

17:29:48 tcp 0 1 127.0.0.1:9877 127.0.0.1:51708 LAST_ACK
....
17:30:00 tcp 0 1 127.0.0.1:9877 127.0.0.1:51708 LAST_ACK
看来这两个状态都受net.ipv4.tcp_orphan_retries配置影响,只不过不是次数的意思。
关闭阶段总结
- TIME_WAIT状态通常也需要大约1min的时间。
由此可以看到,这些状态停留时间还是很长的,我使用内网测试,RTO都相对很少,如果在公网时间会更长。
对于反向代理服务器,由于端口限制,在处理短连接请求时,如果过多的连接得不到释放,将大大降低服务器并发量,net.ipv4.ip_local_port_range如果安3w算的话,一个请求停留在TIME_WAIT为1min,那么QPS只能到500。
网上有大量的优化帖子讨论的系统参数配置,都是对于以上几种状态时间的优化。
连接队列满
client TCP发送SYN,server TCP接收到SYN后需要将该纪录添加到半连接队列,等待之后的ACK到达,如果这时连接队列满了,tcp协议栈会做什么处理呢?
tcp协议栈在处理连接队列满的情况时,只是简单丢弃。推荐阅读:
How TCP backlog works in Linux
linux里的backlog详解
半连接队列满
源码
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
{
// ......
/* Accept backlog is full. If we have already queued enough
* of warm entries in syn queue, drop request. It is better than
* clogging syn queue with openreqs with exponentially increasing
* timeout.
*/
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
// ......
drop:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS);
return 0;
}
linux源码中会有一个定时器定期清理超时的半连接请求。
当client的SYN到达server TCP时,如果server TCP全连接队列满了并且半连接队列>1,server TCP只是简单的丢弃该包,不做任何的后续处理,之后的情形如同”SYN无回复“,client收不到SYN + ACK,会定时重传SYN。在127s后,client的connect函数返回ETIMEDOUT错误。
全连接队列满
源码连接
/*
* The three way handshake has completed - we got a valid synack -
* now create the new socket.
*/
struct sock *tcp_v4_syn_recv_sock(struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct dst_entry *dst)
{
// ......
if (sk_acceptq_is_full(sk))
goto exit_overflow;
// ......
exit_overflow:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
exit_nonewsk:
dst_release(dst);
exit:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS);
return NULL;
// ....
}
同样简单丢弃,只是做了一些统计。之后就如同 ”SYN + ACK无回复“ 的情形一样了。
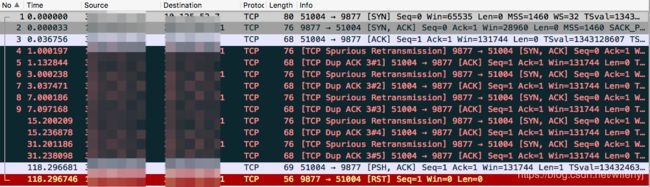
server TCP定时重传SYN + ACK包,63s后服务端关闭socket。但此时client已经认为连接成功,client TCP为ESTABLISHED,如果client app不做任何读写操作,将不会感知到对端连接关闭。当client app调用write,client TCP向对端发送PSH后,server TCP会回复RST。client app之后的调用将返回ECONNRESET。
图示:
总结
以上简单的介绍了一下socket api通常的使用过程,并与tcp协议之间的交互。帮助大家理解记忆,并熟悉异常情况的协议栈的行为,socket api的反应。
从文章可以看出虽然都说tcp是可靠传输,但是对于应用层来说,只有其在全部正常情况时,才能可靠。如果发送异常情况,其可靠性是不能得到保证的。
- 在异常情况发生时,应用程序可能在数分钟之后才能感知到,也有可能干脆无感知。想要快速反应,应用层的心跳是必要的。而tcp的keepalive存在很多不足,比如:
- 在发送数据时,keepalive的timer会被重置,这时如果网络不可达,就需要等到重传超时后返回。
- keepalive的时间间隔设置是全系统共用的。
- tcp层的keepalive无法发现应用程序负载过高或死锁等应用级错误。
- 只通过tcp,应用层是无法知道数据到底有没有被对方应用程序收到。在异常情况发生时,数据可能被丢弃。所以要保证消息送达,需要加应用级的ACK机制。