全文检索
全文检索
全文检索的概念
索引文件是全文检索系统的主要构成部分(全文检索技术就是围绕着索引文件展开)。索引文件中的数据是有结构的,可以对文本数据做词,字,句,段的解析.索引文件是海量数据.
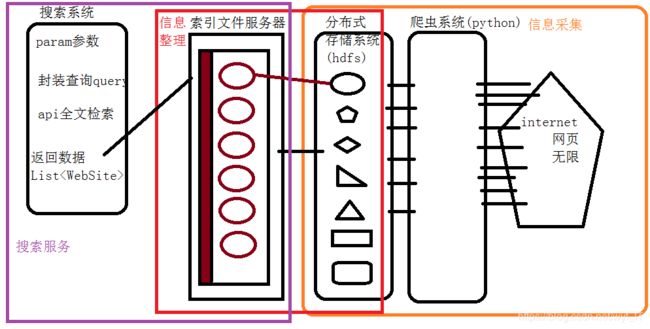
搜索引擎的结构(搜索系统)
- 信息采集:收集数据源的所有源数据进行大数据的存储工作
- 信息整理:源数据海量非结构化(网页),要经过整理的过程输出封装成(索引文件)
- 搜索服务:应用系统,提供客户使用,调用索引文件的数据返回查询的结果
Lucene
- lucene是一个开源的全文检索引擎工具包.早期全文检索所有的具体逻辑原理是通用,但是代码,工具需要自定义开发.Doug Cutting(hadoop)创世.极大提升了全文检索技术开发效率
- 特点
①:稳定,创建索引性能高(150GB/小时)
②:lucene基于java的技术,栈内存要求小1MB
③:增量索引和批量索引速度一样快
④:索引文件索引数据结构20%
⑤:支持多种主流搜索功能:短语,词项,多域,布尔,模糊,通配查询
3. 倒排索引
document(文档):是索引中一个数据整体的最小单位,可以表示封装源数据的一个整体(一个网页,一个数据库行数据)
field(域属性):在一个document对象中,根据不同的数据来源封装多种不同的数据类型的属性(doc1网页对象,)
词项/分词计算(term/analyzer):数据中(document)存储基本都是文本数据,对于文本数据处理,可以进行分词计算,就是将一份字符串按照要求(字,词,句,段)切分成独立的个体(每个个体成为词项);例如:"中华人民共和国",进行分词计算结果:"中华","中华人","华人","人民","人民共和","人民共和国","共和国","中华人民共和国"
4. lucene的代码实现
①:Lucene分词器
分词计算时,底层处理的计算逻辑对二进制(编解码字符集管理的二进制),不同语言不同环境,不同情况计算的分词逻辑不一样(中文,英文,俄文,法文),lucene面向接口,提供了一个Analyzer的分词计算器接口类,所有要计算分词的实现类必须实现这个接口的定义方法,不同国家,不同团队就可以根据这个接口定义,实现自定义的分词逻辑,出现了非常多的实现类具体代码
例如:
StandardAnalyzer:标准分词器(字/英文词)
SimpleAnalyzer:根据标点符号分词(句)
SmartChineseAnalyzer:智能中文分词器(词)
WhitespaceAnalyzer:根据空格分词(词/句)
IKAnalyzer:IK中文分词器(支持扩展)
②:lucene分词器依赖
org.apache.lucene
lucene-queryparser
6.0.0
org.apache.lucene
lucene-analyzers-smartcn
6.0.0
org.apache.lucene
lucene-analyzers-common
6.0.0
org.apache.lucene
lucene-core
6.0.0
举一个例子
package cn.tedu.analyzer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.analysis.core.SimpleAnalyzer;
import org.apache.lucene.analysis.core.WhitespaceAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.junit.Test;
import java.io.IOException;
import java.io.StringReader;
public class AnalyzerTest {
/*
* 对不同的分词器,实现对同一个文本字符串
* 做分词器计算,观察计算结果
* @author admin
*/
//编写一个方法,传递分词器,和msg字符串进行词项的打印
public void printTerm(Analyzer analyzer, String msg) throws IOException {
//获取数据流
StringReader stringReader = new StringReader(msg);
//获取分词器的tokenStream(包含的就是分词计算结果的二进制)
TokenStream tokenStream = analyzer.tokenStream("test", stringReader);
//将计算结果的指针挪到头部
tokenStream.reset();
//获取每个词项的字符串打印出来的char属性
CharTermAttribute attribute = tokenStream.getAttribute(CharTermAttribute.class);
while (tokenStream.incrementToken()){
System.out.println(attribute.toString());
}
}
/*
给printTerm传递不同的分词器查看结果
*/
@Test
public void run() throws IOException {
//准备不同分词器的实现类
String msg = "香港警方:将军澳持刀伤人案嫌犯被捕,是香港居民";
StandardAnalyzer standardAnalyzer = new StandardAnalyzer();
SimpleAnalyzer simpleAnalyzer = new SimpleAnalyzer();
WhitespaceAnalyzer whitespaceAnalyzer = new WhitespaceAnalyzer();
SmartChineseAnalyzer smartChineseAnalyzer = new SmartChineseAnalyzer();
System.out.println("****标准分词器******");
printTerm(standardAnalyzer, msg);
System.out.println("****简单分词器******");
printTerm(simpleAnalyzer, msg);
System.out.println("****空格分词器******");
printTerm(whitespaceAnalyzer, msg);
System.out.println("****中文分词器******");
printTerm(smartChineseAnalyzer, msg);
}
}
上述代码运行结果
****标准分词器******
香
港
警
方
将
军
澳
持
刀
伤
人
案
嫌
犯
被
捕
是
香
港
居
民
****简单分词器******
香港警方
将军澳持刀伤人案嫌犯被捕
是香港居民
****空格分词器******
香港警方:将军澳持刀伤人案嫌犯被捕,是香港居民
****中文分词器******
香港
警方
将军
澳
持
刀
伤
人
案
嫌犯
被捕
是
香港
居民
③:IK分词器
lucene或者全文检索中常用的中文分词器一种,可以实现简单的中文词语的分词计算,也可以根据需求扩展词语(扩展,停用)
cn.tedu
IKAnalyzer2012_u6
jar
system
E:/IKAnalyzer2012_u6.jar
测试封装实现类
IKAnalyzer6x
package cn.tedu.config;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.Tokenizer;
public class IKAnalyzer6x extends Analyzer{
private boolean useSmart;
public boolean useSmart(){
return useSmart;
}
public void setUseSmart(boolean useSmart){
this.useSmart=useSmart;
}
public IKAnalyzer6x(){
this(false);//IK分词器lucene analyzer接口实现类,默认细粒度切分算法
}
//重写最新版本createComponents;重载analyzer接口,构造分词组件
@Override
protected TokenStreamComponents createComponents(String filedName) {
Tokenizer _IKTokenizer=new IKTokenizer6x(this.useSmart);
return new TokenStreamComponents(_IKTokenizer);
}
public IKAnalyzer6x(boolean useSmart){
super();
this.useSmart=useSmart;
}
}
IKTokenizer6xpackage cn.tedu.config;
import java.io.IOException;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
public class IKTokenizer6x extends Tokenizer{
//ik分词器实现
private IKSegmenter _IKImplement;
//词元文本属性
private final CharTermAttribute termAtt;
//词元位移属性
private final OffsetAttribute offsetAtt;
//词元分类属性
private final TypeAttribute typeAtt;
//记录最后一个词元的结束位置
private int endPosition;
//构造函数,实现最新的Tokenizer
public IKTokenizer6x(boolean useSmart){
super();
offsetAtt=addAttribute(OffsetAttribute.class);
termAtt=addAttribute(CharTermAttribute.class);
typeAtt=addAttribute(TypeAttribute.class);
_IKImplement=new IKSegmenter(input, useSmart);
}
@Override
public final boolean incrementToken() throws IOException {
//清除所有的词元属性
clearAttributes();
Lexeme nextLexeme=_IKImplement.next();
if(nextLexeme!=null){
//将lexeme转成attributes
termAtt.append(nextLexeme.getLexemeText());
termAtt.setLength(nextLexeme.getLength());
offsetAtt.setOffset(nextLexeme.getBeginPosition(),
nextLexeme.getEndPosition());
//记录分词的最后位置
endPosition=nextLexeme.getEndPosition();
typeAtt.setType(nextLexeme.getLexemeText());
return true;//告知还有下个词元
}
return false;//告知词元输出完毕
}
@Override
public void reset() throws IOException {
super.reset();
_IKImplement.reset(input);
}
@Override
public final void end(){
int finalOffset = correctOffset(this.endPosition);
offsetAtt.setOffset(finalOffset, finalOffset);
}
}
测试IK分词器
Lucene创建索引文件:
步骤:
①:指定一个文件夹,存储索引数据
②:生成一个输出对象,writer
指定分词器
指定索引的创建模式(创建,追加,追加_创建)
③:准备封装数据的对象document(手动封装)
数据来源--数据库
数据量----hdfs
④:writer将输出整合到索引文件
package cn.tedu.analyzer;
import cn.tedu.config.IKAnalyzer6x;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
public class IKAanyzer6x {
@Test
public void createIndex() throws IOException {
//文件夹指向,如果已经存在和不存在
Path path = Paths.get("d://index01");
FSDirectory dir = FSDirectory.open(path);
//写对象writer,需要对对象的写出逻辑做配置
IndexWriterConfig config = new IndexWriterConfig(new IKAnalyzer6x());
//配置对象指定创建模式
/*
CREATE:创建和覆盖
APPEND:追加
CREATE_OR_APPEND:有则追加,无则创建
*/
config.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
IndexWriter writer = new IndexWriter(dir, config);
//手动拼接document数据
Document doc1 = new Document();
Document doc2 = new Document();
//根据数据源封装数据内容
/*
store.yes/no的区别
yes表示在document数据收集之后,是否需要存储到索引文件
no表示document的当前域数据不存储在索引文件中
field域类型和使用
TextField和StringField区别:
TextField进行索引的分词计算
StringField不进行分词计算(整体存在,而且没有计算粉刺及,搜不到)
数字特性的field类型:
InitPoint
DoublePoint
LongPoint
FloatPoint
既不计算分词,也不存储数据,只保留当前域的数字特性,如果需要将数据查询,对应存储String、Text类型数据,域名和数字特性的保持一致就可以
*/
doc1.add(new TextField("title", "娱乐早知道", Field.Store.YES));
doc1.add(new TextField("publisher", "北京文娱", Field.Store.YES));
doc1.add(new TextField("content", "马伊琍和文章是否还有感情", Field.Store.YES));
doc1.add(new TextField("title", "娱乐早知道", Field.Store.YES));
doc2.add(new TextField("title", "娱乐拔呀拔", Field.Store.YES));
doc2.add(new TextField("publisher", "上海文娱", Field.Store.YES));
doc2.add(new TextField("content", "马伊琍和文章分别发博文官宣离婚", Field.Store.YES));
//writer输出到索引文件
//writer加上2个doc
writer.addDocument(doc1);
writer.addDocument(doc2);
writer.commit();
}
}
测试结果生成Index01索引文件,利用Luke测试

5. lucene的搜索功能
全文检索技术实现创建索引之后,需要在进行查询的使用,lucene提供丰富的查询功能,不同的查询效果需要封装不同的query对象.
①:搜索功能
词项查询:分词结果有的词项查询数据返回,没有的词项查不到数据,最基本的查询方式,其他的查询都是对词项的上层封装查询结果
多域查询:对关键字做解析,对应多个域做词项查询,找到一个存在的就返回.
布尔查询:对多个查询条件作为子条件封装,决定查询的多个条件对应的结果集的关系
范围查询:对数字特性的域做范围搜索,上限下限满足范围的返回doc数据
②:搜索代码的步骤
a:指定索引文件位置
b:生成reader对象,封装一个查询对象search
c:封装查询条件Query
d:遍历查询结果
词项搜索:
词项查询:分词结果有的词项查询数据返回,没有的词项查不到数据,最基本的查询方式,其他的查询都是对词项的上层封装查询结果,并且还会按照搜索结果的docID的大小显示
//词项搜索
@Test
public void termQuery() throws IOException {
//指定文件夹
Path path = Paths.get("d://index01");
FSDirectory dir = FSDirectory.open(path);
//获取reader
DirectoryReader reader = DirectoryReader.open(dir);
//封装搜索对象
IndexSearcher searcher = new IndexSearcher(reader);
//封装不同功能的查询条件
//准备一个词项,定义词项的域名称
Term term = new Term("content", "文章");
TermQuery query = new TermQuery(term);
//获取结果集遍历打印结果数据,获取top10前10条数据
TopDocs topDocs = searcher.search(query, 10);
System.out.println("总共搜索到"+topDocs.totalHits+"条");
//topDoc当中封装了带有评分的结果信息,带有docid的信息数据返回
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//score中除了保存了每个查询结果document的id还有评分
for (ScoreDoc score:scoreDocs) {
//将获取的数据打印
int docId = score.doc;
System.out.println("当前的docID为"+docId+score.score);
//通过id获取document数据
Document document = searcher.doc(docId);
System.out.println("title"+document.get("title"));
System.out.println("content"+document.get("content"));
System.out.println("publisher"+document.get("publisher"));
}
}多域查询
多域查询:对关键字做解析,对应多个域做词项查询,找到一个存在的就返回.
①:先对查询关键字做分词器解析:
②:"马伊琍爱文章吗"-->"马,伊,琍,爱,文章,吗"
③:分别和域做两两对象,求最终的并集
④:封装不同功能的查询条件query
⑤:分词器(创建索引使用分词器一致)
@Test
public void termQuery1() throws IOException, ParseException {
//指定文件夹
Path path = Paths.get("d://index01");
FSDirectory dir = FSDirectory.open(path);
//获取reader
DirectoryReader reader = DirectoryReader.open(dir);
//封装搜索对象
IndexSearcher searcher = new IndexSearcher(reader);
IKAnalyzer6x analyzer6x = new IKAnalyzer6x();
//准备多个域
String[] fields = {"title","content","publisher"};
//包装了分词器的条件字符串解析器parser
MultiFieldQueryParser multiFieldQueryParser = new MultiFieldQueryParser(fields, analyzer6x);
//生成查询条件
Query query = multiFieldQueryParser.parse("文章还爱马伊琍吗");
TopDocs topDocs = searcher.search(query, 10);
System.out.println("总共搜索到"+topDocs.totalHits+"条");
//topDoc当中封装了带有评分的结果信息,带有docid的信息数据返回
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//score中除了保存了每个查询结果document的id还有评分
for (ScoreDoc score:scoreDocs) {
//将获取的数据打印
int docId = score.doc;
System.out.println("当前的docID为"+docId+score.score);
//通过id获取document数据
Document document = searcher.doc(docId);
System.out.println("title"+document.get("title"));
System.out.println("content"+document.get("content"));
System.out.println("publisher"+document.get("publisher"));
}
}多域查询结果:
总共搜索到2条
当前的docID为00.5525621
title娱乐早知道
content马伊琍和文章是否还有感情
publisher北京文娱
当前的docID为10.4504415
title娱乐拔呀拔
content马伊琍和文章分别发博文官宣离婚
publisher上海文娱布尔查询:
/*
子条件发生逻辑:
Occur:MUST:布尔查询结果必须不包含当前条件结果
MUST_NOT:布尔查询结果必须不包含当前条件结果
SHOULD:SHOULD如何和MUST同时使用,不起作用
FILTER:效果和MUST一样,fiter条件查询结果不能参加评分的
*/
@Test
public void termQuery2() throws IOException, ParseException {
//指定文件夹
Path path = Paths.get("d://index01");
FSDirectory dir = FSDirectory.open(path);
//获取reader
DirectoryReader reader = DirectoryReader.open(dir);
//封装搜索对象
IndexSearcher searcher = new IndexSearcher(reader);
IKAnalyzer6x analyzer6x = new IKAnalyzer6x();
TermQuery query1 = new TermQuery(new Term("title","马"));
TermQuery query2 = new TermQuery(new Term("content","马"));
BooleanClause clause = new BooleanClause(query1, BooleanClause.Occur.MUST_NOT);
BooleanClause clause1 = new BooleanClause(query2, BooleanClause.Occur.FILTER);
BooleanQuery query = new BooleanQuery.Builder().add(clause).add(clause1).build();
TopDocs topDocs = searcher.search(query, 10);
System.out.println("总共搜索到"+topDocs.totalHits+"条");
//topDoc当中封装了带有评分的结果信息,带有docid的信息数据返回
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//score中除了保存了每个查询结果document的id还有评分
for (ScoreDoc score:scoreDocs) {
//将获取的数据打印
int docId = score.doc;
System.out.println("当前的docID为"+docId+score.score);
//通过id获取document数据
Document document = searcher.doc(docId);
System.out.println("title"+document.get("title"));
System.out.println("content"+document.get("content"));
System.out.println("publisher"+document.get("publisher"));
}
}
查询结果:
总共搜索到2条
当前的docID为00.0
title娱乐早知道
content马伊琍和文章是否还有感情
publisher北京文娱
当前的docID为10.0
title娱乐拔呀拔
content马伊琍和文章分别发博文官宣离婚
publisher上海文娱范围查询:
加入数据中有浏览次数,可以通过整数值定义这个次数,可以通过范围搜索,搜索一批文章,浏览次数300-6000之间
//封装一个查询views的数据IntPoint
Query query=IntPoint.newRangeQuery("views", 300000, 6000000);
模糊查询:
作用:用关键字查询数据,例如查询trump,tramp,进行模糊匹配.
FuzzyQuery query=new FuzzyQuery(new Term("name","tramp"))
通配符查询
可以使用?代替任意字符,实现词项查询
例如,词项中,"文章","文本"
WildcardQuery query=new WildcardQuery(new Term("name","文?"));