Redis基本数据结构常用命令及数据持久化配置学习笔记
Redis的启动与客户端连接
# 启动redis
yitian@kafka:/usr/local/bin$ redis-server /etc/redis/redis.conf
# 客户端连接
yitian@kafka:/usr/local/bin$ redis-cli -p 6379
127.0.0.1:6379> ping
PONG
Redis的数据结构
- String
- list
- hash
- set
- sorted set
Redis字符串操作
127.0.0.1:6379> set name value # 向数据库中加入键值对
OK
127.0.0.1:6379> get name # 获取key为name的值
"value"
127.0.0.1:6379> getset name new_value # 获取key为name的值,并把值设置为new_value
"value"
127.0.0.1:6379> get name
"new_value"
127.0.0.1:6379> del name # 删除key为name的值
(integer) 1
127.0.0.1:6379> get name # 重新获取,发现返回nil
(nil)
127.0.0.1:6379> set number 1 # 添加一个值为数值的value
OK
127.0.0.1:6379> get number
"1"
127.0.0.1:6379> incr number # 自增key为number的值(+1)
(integer) 2
127.0.0.1:6379> incrby number 5 # 增加key为number的值(+value)
(integer) 7
127.0.0.1:6379> set name zhang
OK
127.0.0.1:6379> incr name # 如果key对应的value值为string,则incr命令报错
(error) ERR value is not an integer or out of range
127.0.0.1:6379> incrby name yitian
(error) ERR value is not an integer or out of range
127.0.0.1:6379> decr number # 与incr命令的作用相反
(integer) 6
127.0.0.1:6379> decrby number 3
(integer) 3
127.0.0.1:6379> get number
"3" Hash的操作
类似于java中的hashmap容器。
127.0.0.1:6379> keys * # 获取数据库中所有的key
1) "number"
2) "nubmer"
3) "name"
127.0.0.1:6379> flushall # 清空数据库
OK
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> hset myhash username jack # 一次向hash中添加一个数据
(integer) 1
127.0.0.1:6379> hset myhash age 18
(integer) 1
127.0.0.1:6379> hmset myhash2 username rose age 21 # 一次添加多个数据
OK
127.0.0.1:6379> hget myhash username # 一次获取一个数据
"jack"
127.0.0.1:6379> hmget myhash username age # 一次获取多个数据
1) "jack"
2) "18"
127.0.0.1:6379> hgetall myhash # 获取hash中的所有数据
1) "username"
2) "jack"
3) "age"
4) "18"
### 删除操作
127.0.0.1:6379> hgetall myhash2
1) "username"
2) "rose"
3) "age"
4) "21"
127.0.0.1:6379> hdel myhash2 username # 删除hash中一个key-value,删除成功返回1,删除失败返回0
(integer) 1
127.0.0.1:6379> hdel myhash2 username
(integer) 0
127.0.0.1:6379> hgetall myhash2
1) "age"
2) "21"
127.0.0.1:6379> del myhash2 # 删除整个hash数据结构
(integer) 1
127.0.0.1:6379> hgetall myhash2
(empty list or set)
### 数值递增操作
127.0.0.1:6379> hget myhash age
"18"
127.0.0.1:6379> hincrby myhash age 5
(integer) 23
### 判断key是否存在,返回1为存在,0为不存在
127.0.0.1:6379> hexists myhash username
(integer) 1
127.0.0.1:6379> hexists myhash password
(integer) 0
### 获取hahs中的key和values
127.0.0.1:6379> hlen myhash
(integer) 2
127.0.0.1:6379> hkeys myhash
1) "username"
2) "age"
127.0.0.1:6379> hvals myhash
1) "jack"
2) "23"
List集合操作
类似于双向循环链表结构
# 从左侧开始向list中添加数据
127.0.0.1:6379> lpush mylist a b c
(integer) 3
127.0.0.1:6379> lpush mylist 1 2 3
(integer) 6
# 从右侧开始向list中添加数据
127.0.0.1:6379> rpush mylist2 a b c
(integer) 3
127.0.0.1:6379> rpush mylist2 1 2 3
(integer) 6
# 查看list中的元素 lrange mylist start end,左边从0开始,右边从-1开始
127.0.0.1:6379> lrange mylist 0 5
1) "3"
2) "2"
3) "1"
4) "c"
5) "b"
6) "a"
127.0.0.1:6379> lrange mylist 0 -1
1) "3"
2) "2"
3) "1"
4) "c"
5) "b"
6) "a"
# 左侧弹出一个元素,list中即删除
127.0.0.1:6379> lpop mylist
"3"
127.0.0.1:6379> lrange mylist 0 -1
1) "2"
2) "1"
3) "c"
4) "b"
5) "a"
# 获取list的长度
127.0.0.1:6379> llen mylist
(integer) 5
127.0.0.1:6379> llen mylist3 # 获取一个不存在的list长度,返回为0
(integer) 0
# 将x插入到mylist头中,如果mylist不存在则不会插入
127.0.0.1:6379> lpushx mylist x
(integer) 6
127.0.0.1:6379> lrange mylist 0 -1
1) "x"
2) "2"
3) "1"
4) "c"
5) "b"
6) "a"
127.0.0.1:6379> lpushx mylist3 x # 将x插入到一个不存在的list中
(integer) 0
127.0.0.1:6379> lpush mylist3 1 2 3
(integer) 3
127.0.0.1:6379> lpush mylist3 1 2 3
(integer) 6
127.0.0.1:6379> lpush mylist3 1 2 3
(integer) 9
127.0.0.1:6379> lrange mylist3 0 -1
1) "3"
2) "2"
3) "1"
4) "3"
5) "2"
6) "1"
7) "3"
8) "2"
9) "1"
# 删除list中的元素,lrem list_name count value,
# 若count>0,则为从左侧开始遍历,删除list中值为value的count个元素;
# 若count<0,则为从右边开始,删除list中值为value的count的元素;
# 若count=0,则删除list中所有值为value的元素
127.0.0.1:6379> lrem mylist3 2 3
(integer) 2
127.0.0.1:6379> lrange mylist3 0 -1
1) "2"
2) "1"
3) "2"
4) "1"
5) "3"
6) "2"
7) "1"
127.0.0.1:6379> lrem mylist3 -2 1
(integer) 2
127.0.0.1:6379> lrange mylist3 0 -1
1) "2"
2) "1"
3) "2"
4) "3"
5) "2"
127.0.0.1:6379> lrem mylist3 0 2
(integer) 3
127.0.0.1:6379> lrange mylist3 0 -1
1) "1"
2) "3"
# 在指定下标位置上添加元素,下面为在下标为3的位置添加mmm
127.0.0.1:6379> lset mylist 3 mmm
OK
127.0.0.1:6379> lrange mylist 0 -1
1) "x"
2) "2"
3) "1"
4) "mmm"
5) "b"
6) "a"
127.0.0.1:6379> lpush mylist4 a b c
(integer) 3
127.0.0.1:6379> lpush mylist4 a b c
(integer) 6
127.0.0.1:6379> lrange mylist4 0 -1
1) "c"
2) "b"
3) "a"
4) "c"
5) "b"
6) "a"
# 在指定元素的前面一个或后面一个位置上添加一个元素
127.0.0.1:6379> linsert mylist4 before b 11
(integer) 7
127.0.0.1:6379> linsert mylist4 after b 22
(integer) 8
127.0.0.1:6379> lrange mylist4 0 -1
1) "c"
2) "11"
3) "b"
4) "22"
5) "a"
6) "c"
7) "b"
8) "a"
127.0.0.1:6379> lpush mylist5 1 2 3
(integer) 3
127.0.0.1:6379> lpush mylist6 a b c
(integer) 3
127.0.0.1:6379> lrange mylist5 0 -1
1) "3"
2) "2"
3) "1"
127.0.0.1:6379> lrange mylist6 0 -1
1) "c"
2) "b"
3) "a"
# rpoplpush list1 list2,将list1中的右边第一个元素pop,添加到list2中最左边的位置
127.0.0.1:6379> rpoplpush mylist5 mylist6
"1"
127.0.0.1:6379> lrange mylist5 0 -1
1) "3"
2) "2"
127.0.0.1:6379> lrange mylist6 0 -1
1) "1"
2) "c"
3) "b"
4) "a"Set数据结构的操作
# 添加和删除元素
127.0.0.1:6379> sadd myset a b c
(integer) 3
127.0.0.1:6379> sadd myset a
(integer) 0
127.0.0.1:6379> sadd myset 1 2 3
(integer) 3
127.0.0.1:6379> srem myset 1 2 # 从set中删除元素,如果删除set使用del set
(integer) 2
127.0.0.1:6379> smembers myset # 查看set中的所有元素
1) "a"
2) "c"
3) "b"
4) "3"
127.0.0.1:6379> sismember myset a # 判断元素是否在set中,是返回1,不是返回0
(integer) 1
127.0.0.1:6379> sismember myset 1
(integer) 0
127.0.0.1:6379> sadd myset1 a b c
(integer) 3
127.0.0.1:6379> sadd myset2 a c 1 2
(integer) 4
127.0.0.1:6379> sdiff myset1 myset2 # 求两个集合的差集,与set顺序有关
1) "b"
127.0.0.1:6379> sdiff myset2 myset1
1) "1"
2) "2"
127.0.0.1:6379> sinter myset1 myset2 # 求两个集合的交集
1) "c"
2) "a"
127.0.0.1:6379> sunion myset1 myset2 # 求两个集合的并集
1) "c"
2) "a"
3) "2"
4) "1"
5) "b"
127.0.0.1:6379> sdiffstore diffset myset1 myset2 # 求myset1和myset2集合的差集并存储到diffset集合中
(integer) 1
127.0.0.1:6379> smembers diffset
1) "b"
127.0.0.1:6379> sinterstore interset myset1 myset2 # 求myset1和myset2的交集并存储到interset集合中
(integer) 2
127.0.0.1:6379> smembers interset
1) "a"
2) "c"
127.0.0.1:6379> sunionstore unionset myset1 myset2 # 求myset1和myset2的并集并存储到unionset集合中
(integer) 5
127.0.0.1:6379> smembers unionset
1) "c"
2) "a"
3) "2"
4) "1"
5) "b"
127.0.0.1:6379> smembers myset
1) "a"
2) "c"
3) "b"
4) "3"
127.0.0.1:6379> scard myset # 获取集合元素的个数
(integer) 4
127.0.0.1:6379> srandmember myset # 随机返回set集合中的一个元素
"a"
127.0.0.1:6379> srandmember myset
"3"
127.0.0.1:6379> srandmember myset
"c"SortedSet数据结构
# 一次向sortedset中增加多个元素,同时每个元素有一个score用于排序
127.0.0.1:6379> zadd mysort 70 zhang 80 yi 90 tian
(integer) 3
127.0.0.1:6379> zadd mysort 100 zhang
(integer) 0
127.0.0.1:6379> zadd mysort 60 tom
(integer) 1
127.0.0.1:6379> zscore mysort zhang # 修改一个元素的score值
"100"
# 查看sortedset中的元素,同hash的操作
127.0.0.1:6379> zrange mysort 0 -1
1) "yi"
2) "tian"
3) "zhang"
127.0.0.1:6379> zrange mysort 0 -1 withscores # 查看元素,同时显示score的值
1) "yi"
2) "80"
3) "tian"
4) "90"
5) "zhang"
6) "100"
# sortedset的元素默认是按照score的升序排列,这里可以反转
127.0.0.1:6379> zrevrange mysort 0 -1 withscores
1) "zhang"
2) "100"
3) "tian"
4) "90"
5) "yi"
6) "80"
# 获取指定score范围的元素
127.0.0.1:6379> zrangebyscore mysort 0 100 withscores
1) "tom"
2) "60"
3) "yi"
4) "80"
5) "tian"
6) "90"
7) "zhang"
8) "100"
# 获取指定score范围中的前两个元素
127.0.0.1:6379> zrangebyscore mysort 0 100 withscores limit 0 2
1) "tom"
2) "60"
3) "yi"
4) "80"
# 获取指定score范围中的所有元素
127.0.0.1:6379> zrangebyscore mysort 0 100 withscores limit 0 -1
1) "tom"
2) "60"
3) "yi"
4) "80"
5) "tian"
6) "90"
7) "zhang"
8) "100"
127.0.0.1:6379> zrange mysort 0 -1 withscores
1) "tom"
2) "60"
3) "jack"
4) "65"
5) "rose"
6) "75"
7) "yi"
8) "80"
9) "tian"
10) "90"
# 删除sortedset的前两个元素
127.0.0.1:6379> ZREMRANGEBYRANK mysort 0 2
(integer) 3
127.0.0.1:6379> zrange mysort 0 -1 withscores
1) "yi"
2) "80"
3) "tian"
4) "90"
# 删除指定score范围中的元素
127.0.0.1:6379> zremrangebyscore mysort 90 100
(integer) 1
127.0.0.1:6379> zrange mysort 0 -1 withscores
1) "yi"
2) "80"
# 获取sortedset中元素的个数
127.0.0.1:6379> zcard mysort
(integer) 1
127.0.0.1:6379> zrange mysort 0 -1 withscores
1) "tom"
2) "60"
3) "zhang"
4) "60"
5) "tian"
6) "70"
7) "yi"
8) "80"
# 统计指定score范围中的元素个数
127.0.0.1:6379> zcount mysort 70 90
(integer) 2
# 增加指定元素的score值
127.0.0.1:6379> zincrby mysort 100 zhang
"160"
127.0.0.1:6379> zrange mysort 0 -1 withscores
1) "tom"
2) "60"
3) "tian"
4) "70"
5) "yi"
6) "80"
7) "zhang"
8) "160"Keys的通用操作
127.0.0.1:6379> keys * # 获取redis中所有的key
1) "mysort"
2) "interset"
3) "myhash"
4) "myset1"
5) "mylist"
6) "myset"
7) "diffset"
8) "mylist5"
9) "myset2"
10) "mylist3"
11) "mylist6"
12) "unionset"
13) "mylist2"
14) "mylist4"
127.0.0.1:6379> del interset # 删除指定的key
(integer) 1
127.0.0.1:6379> keys *
1) "mysort"
2) "myhash"
3) "myset1"
4) "mylist"
5) "myset"
6) "diffset"
7) "mylist5"
8) "myset2"
9) "mylist3"
10) "mylist6"
11) "unionset"
12) "mylist2"
13) "mylist4"
127.0.0.1:6379> exists mysort # 判断一个key是否存在
(integer) 1
127.0.0.1:6379> exists mysort
(integer) 1
127.0.0.1:6379> set company zhangyitian.inc
OK
127.0.0.1:6379> get company
"zhangyitian.inc"
127.0.0.1:6379> rename company mycompany # 对key重命名
OK
127.0.0.1:6379> get company
(nil)
127.0.0.1:6379> get mycompany
"zhangyitian.inc"
127.0.0.1:6379> expire mycompany 1000 # 设置一个key的超时时间
(integer) 1
127.0.0.1:6379> ttl mycompany
(integer) 993
127.0.0.1:6379> ttl mysort # 如果没有设置,则返回-1
(integer) -1
127.0.0.1:6379> type mycompany # 判断一个key的数据类型
string
127.0.0.1:6379> type mysort
zset
127.0.0.1:6379> type mylist
list
127.0.0.1:6379> type myhash
hash
127.0.0.1:6379> type myset
setRedis的多数据库操作
一个Redis实例可以包含多个db,使用客户端可以指定连接的哪个db中。一个redis实例默认提供16的db,且客户端默认连接到第0个db中。
# 切换到连接1号数据库
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> keys * # 查看1号数据库中的keys,为空
(empty list or set)
127.0.0.1:6379[1]> select 0 # 回到默认的0号数据库中,keys不为空
OK
127.0.0.1:6379> keys *
1) "mysort"
2) "myhash"
3) "myset1"
4) "mylist"
5) "myset"
6) "mycompany"
7) "diffset"
8) "mylist5"
9) "myset2"
10) "mylist3"
11) "mylist6"
12) "unionset"
13) "mylist2"
14) "mylist4"
127.0.0.1:6379> move mycompany 1 # 将指定的key-value移动到其他数据库中,并进行查看
(integer) 1
127.0.0.1:6379> keys *
1) "mysort"
2) "myhash"
3) "myset1"
4) "mylist"
5) "myset"
6) "diffset"
7) "mylist5"
8) "myset2"
9) "mylist3"
10) "mylist6"
11) "unionset"
12) "mylist2"
13) "mylist4"
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> keys *
1) "mycompany"
Redis的事务操作
- 基本命令 multi exec discard
- 事务的ASID 原子性
- 事务的命令都是串行化顺序执行
- 开启一个事务,multi之后的命令都认为是事务命令(存入到命令队列中,顺序exec),exec类似于提交,discard类似为回滚

Redis持久化操作
Redis的持久化就是,将内存中的数据持久化到磁盘中,以避免机器重启中内存中数据的丢失。Redis中的所有数据都存储在内存中(高效率的原因)。
两种持久化的方式
| RDB,在指定的时间间隔,将内存中的数据集快照按照一定的时间间隔写入磁盘一次。 | AOF,使用日志的方式,记录服务器的所有操作,在redis服务启动时,他会读取日志,会重新构建数据库,保证redis启动后,数据库的数据是完整的。 |
RDB方式
优势和缺点:
| redis只包含一个文件,对于文件备份而言是很友好的。 对于灾难恢复很友好 性能最大化,对于redis的服务进程而言,在开始持久化的时候,唯一需要做的就是使用一些进程完成持久化的操作,避免大量的IO操作 相较于AOF的方式,如果数据集很大,RDB的启动效率会更高 |
如果保证数据的高可用性,RDB不是一个好的选择,如果30s写一次,如果25s的时候服务器宕机了,那么这个时间的数据就丢失了 如果数据很大的时候,可能会导致服务器会延迟一段时间。 |
RDB的配置
Redis默认支持的就是RDB,因此通过查看配置文件,可以看到RDB模式已经开起了:
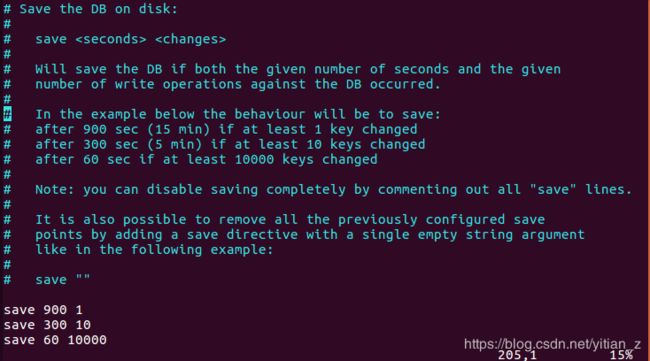
上面的设置表示:
- 每900s 至少有1个key变化,会持久化一次
- 每300s 至少有10个key变化,会持久化一次
- 每60s 至少有10000个key变化,会持久化一次
持久化文件保存的路径和文件名:
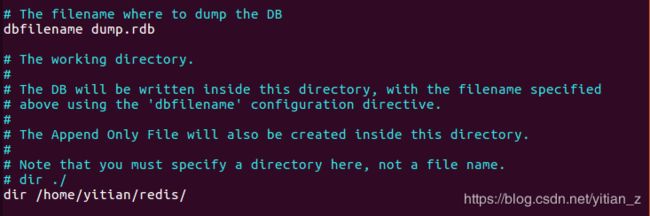
在指定的目录下可以看到相应的持久化文件:
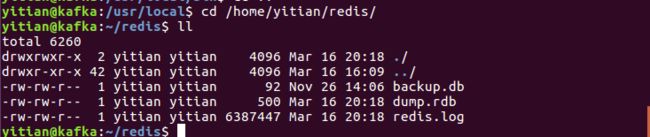
AOF方式
AOF的优势和缺点
| 更高的数据安全性(每秒同步,每修改同步(最安全),不同步) 对日志写入使用的append模式,即使宕机,也不会丢失数据。 如果日志过大,redis可以启动重写机制。 AOF保存了一个格式清晰的日志文件 |
对于相同数量数据集的数据,AOF文件较大 效率较RDB低 |
AOF的配置

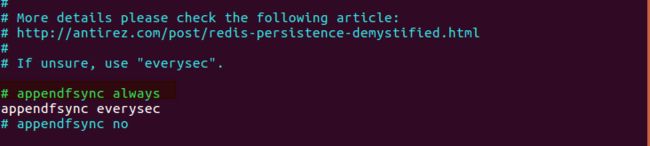
配置过程如下:
- 配置改为yes
- 配置改为appendfsyn always,安全等级最高
- 重启redis-server服务