Hadoop核心组件的介绍(一)
Hadoop是什么
Hadoop是一种分析和处理海量数据的软件平台
Hadoop是一款开源软件,使用JAVA开发
Hadoop可以提供一个分布式基础架构
Hadoop特点
高可靠性 高扩展性 高效性 高容错性 低成本
Hadoop组件
核心组件
HDFS:Hadoop分布式文件系统
MapReduce:分布式计算框架
Yarn:集群资源管理系统
常用组件
Zookeeper:分布式协作服务
Hbase:分布式列存数据库
Hive:基于Hadoop的数据仓库
Sqoop:数据同步工具
Pig:基于Hadoop的数据流系统
Mahout:数据挖掘算法库
Flume:日志收集工具
HDFS
HDFS集群,主要负责海量数据的存储,主要有NameNode/DataNode和secondaryNameNode组成,其架构如下图所示
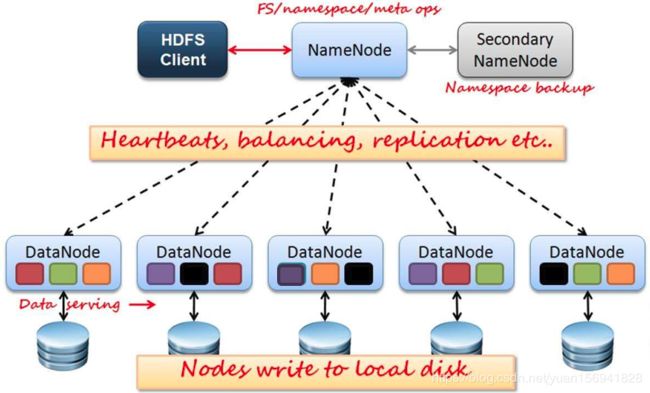
角色介绍
- NameNode:主要负责管理HDFS的名称空间和数据块映射信息,处理所有客户端请求,配置副本策略,周期性的接受DataNode的心跳检测和块的状态报告信息,若接收到心跳信息,则认为DN工作正常,如果10分钟接受不到DN的心跳信息,则会认为DN宕机,这时NN会准备把DN上的数据进行重新复制.块状态信息包含了一个DN上所有数据块的列表.
- SecondaryNameNode:定期合并fsimage和fsedits,推送给NameNode,紧急情况下可以辅助回复NameNode.但是它并不是NameNode的热备.
- DataNode:数据存储节点,存储实际的数据,汇报存储信息给NameNode.
- Client:切分文件访问HDFS;与NameNode交互,获取文件存储位置信息;与DataNode交互,读取和写入数据.
Block: 存储的数据库块,每块缺省128M大小,每块可以有多个副本
工作流程
- Client客户端接收数据,并将数据进行分块处理,每块128M大小;
- Client访问NameNode,获取数据存储节点位置信息和副本数量.即询问NameNode需要讲每块数据总共备几份,并且讲这些数据存储到哪几台DataNode主机节点
- client根据NameNode返回的信息寻找到对应的DataNode节点,并将数据进行存储
- 数据存储完毕,DataNode向NameNode汇报自己存储了哪些数据
- NameNode根据DataNode汇报的信息,建立数据和存储地址的映射信息表.后期客户端读取数据,NameNode会根据映射信息告诉客户端去哪些DataNode节点读取数据.
- 总结:DataNode负责处理文件系统客户端的读写请求.在NameNode的统一调度下进行数据块的创建,删除和复制.NameNode是所有HDFS元数据的仲裁者和管理这,并且用户数据永远不会流过NameNode.
MapReduce
MapReduce是对google三大论文的MapReduce的开源实现,实际上是一种编程模型,是一个分布式的计算框架,用于处理海量数据的运算。
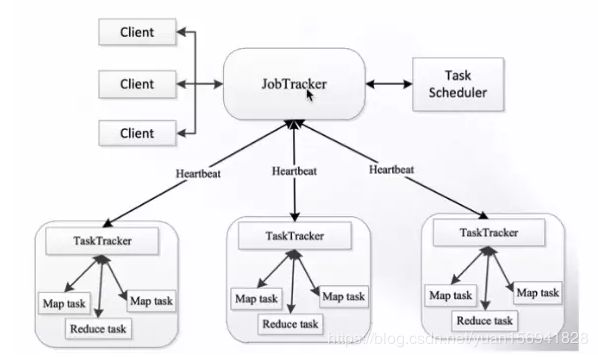
角色介绍
JobTracker:管理所有作业/任务的监控和错误处理;将任务分解成一些列任务,并分派给TaskTracker
TaskTracker:运行Map Task和Reduce Task;定期向JT汇报本节点的健康状况、资源使用情况、作业执行情况;接受来自JT的命令:启动任务/杀死任务.
Map Task:解析每条数据记录,传递给用户编写的map()并执行,将输出结果写入本地磁盘,如果为map-only作业,直接写入HDFS.
ReducerTask:从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的reduce函数执行.
Yarn
Yarn是Hadoop的一个通用资源管理系统.为上层应用提供统一的资源管理和调度,其架构如下所示:
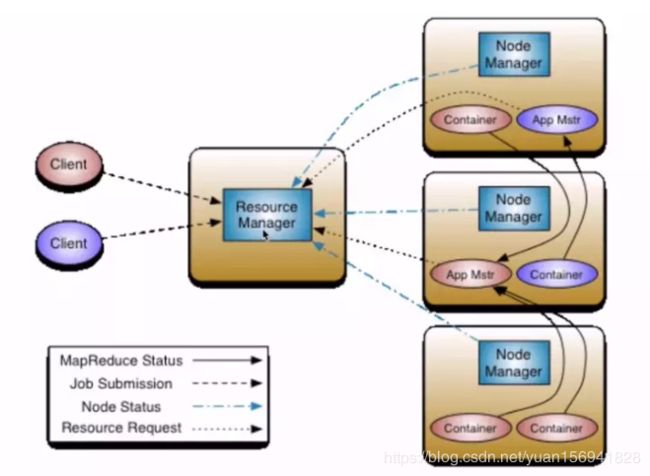
角色介绍
ResourceManager(RM):
-整个集群同一时间提供服务的RM只有一个,负责集群资源的统一管理和调度
-处理客户端的请求:提交一个作业,杀死一个作业
-监控NM,一旦某一个NM宕机,那么RM会告诉在该NM上运行的AM进行如何处理
NodeManager(NM):
-集群中有多个,负责本身节点资源管理和使用
-定时想RM汇报自身节点的资源使用情况
-接收并处理来自RM的各种命令
-处理来自AM的命令
ApplicationMaster(AM):
-每个应用程序对应一个:MR,Spark,负责应用程序的管理
-为应用层序向RM申请资源,分配给内部task
-与NM通信:启动/停止task,task试运行在container,AM也是运行在Container里
Container:
对任务运行环境的抽象,封装了cpu和内存等;多维资源以及环境变量,启动命令等任务运行相关的信息资源分配与调度,说白了就是一个资源容器
Client:
用户与Yarn交互的客户端程序,提交应用程序,监控应用程序状态,杀死应用程序等.
工作流程
1.客户端向Yarn提交应用程序,包含AM程序,启动AM命令,用户程序等
2.RM为该应用分配第一个Container,并与对应的NM通信要求在这个Container中启动应用程序的AM
3.AM首先向RM进行注册,这样客户端可以通过RM查看应用程序运行状态,然后AM为各个任务申请资源,并监控任务的运行状态,直到运行结束.
4.AM采用轮训的方式通过RPC协议向RM申请和领取资源
5.一旦AM申请到资源后,便与对应的NM通信,要求NM启动任务
6.NM为人物设置好运行环境,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务
7.各个任务通过某个RPC向AM汇报自己的状态和进度,便于AM掌握各个任务的运行状态,从而在任务失败时重新启动任务.在应用程序运行过程中,用户可随时通过RPC向AM查询应用程序的当前运行状态
8.应用程序运行完成后,AM向RM注销并关闭自己
参考文献
https://wenku.baidu.com/view/4fed9b230812a21614791711cc7931b765ce7bf6.html
https://blog.csdn.net/weixin_40535323/article/details/82025442
https://www.jianshu.com/p/0e07041a6556
hadoop三大核心组件
https://www.cnblogs.com/jiataoq/p/9700469.html