一次由于YoungGC引起的性能问题分析
问题现象
应用用druid连接池,设置慢SQL时间为500ms。
在线上应用报了一些但是不多的慢查询日志,并且这个慢查询日志居然是单条插入的语句。
后台数据库是MySQL,有查询统计日志监控,并没有发现很慢的插入语句。
觉得很奇怪,需要仔细定位下
问题定位
为了确认问题,搭建压测环境,并在应用和MySQL所在的机器上进行抓包分析。
压测开始后,又发现了很多是单条插入语句的慢查询日志,例如:
2018-01-17 09:45:03.633 ERROR [order,d6d34e1d0491230b,2b15c10fda53e695] [4556] [http-nio-8121-exec-735][?:]: slow sql 716 millis. insert into t_order_record (col1,col2,col3,col4, ...) values (?, ?, ?, ?, ...)["180117094502ord37425097","627807","fakeu004763",0...]根据其中的关键字180117094502ord37425097,在WireShark搜索抓包结果,filter填写:
tcp.payload contains "180117094502ord37425097"
查看下包内容确认的确是我们要找的
由于我的wireshark并没有解析出这是一个MySQL包,而是当成一个普通TCP,所以找这次请求的响应比较麻烦;不过,有一个比较笨的方法,就是找出这个包最近的下一个目标为这个包源端口的SQL执行结果响应包。
这次这个包序号是190362,源端口是55934,我们filter填写:
tcp.dstport == 55934
找到下一个包应该是190363,查看包内容:
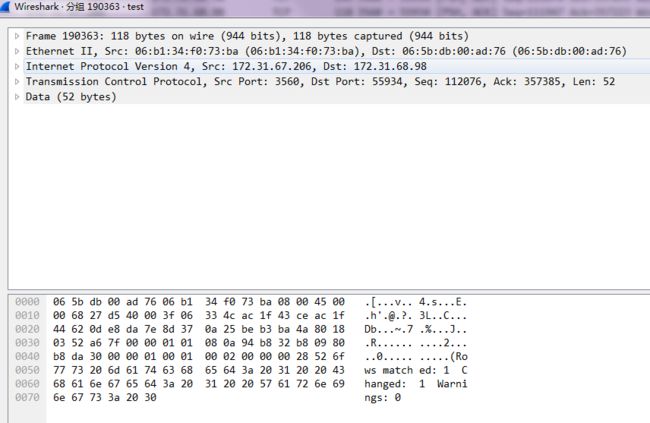
因为MySQL协议中客户端服务端通信,不会在收到本次响应之前发送下一个请求。所以这个就是对应我们要寻找的请求的响应包
看时间差,从请求发出到响应收到,间隔了53.893 - 53.889 = 0.004s,完全没有716ms。
我们看下那个时间点的GC日志:
2018-01-17T09:45:02.950+0000: 30.017: [GC (Allocation Failure) 2018-01-17T09:45:02.950+0000: 30.017: [ParNew: 2654203K->182255K(2831168K), 0.4347209 secs] 2654203K->182255K(4928320K), 0.4348647 secs] [Times: user=0.85 sys=0.03, real=0.43 secs] 发现这个时间点发生了YGC,对CPU占用比较高,而且,时间比较长,推测这个Allocation Failure很可能是由于接收SQL结果返回引起的。
之后检查基本每次慢SQL都对应一个时间较长的YGC,或者是TCP重传,例如这样的:
![]()
我们尝试调大了应用整体堆栈大小和EdenSize,发现YGC减少,慢SQL日志也减少了。
问题分析
查阅资料,参考:https://plumbr.eu/handbook/gc-tuning-in-practice
分配速率的变化,会增加或降低GC暂停的频率, 从而影响吞吐量。 但只有年轻代的 minor GC 受分配速率的影响, 老年代GC的频率和持续时间不受 分配速率(allocation rate)的直接影响, 而是受到 提升速率(promotion rate)的影响。
做个小实验,测出:
- Eden 空间为 100 MB 时, 分配速率低于 100 MB/秒。
- 将 Eden 区增大为 1 GB, 分配速率也随之增长,大约等于 200 MB/秒。
为什么会这样? —— 因为减少GC暂停,就等价于减少了任务线程的停顿,就可以做更多工作, 也就创建了更多对象, 所以对同一应用来说, 分配速率越高越好。
在得出 “Eden区越大越好” 这个结论前, 我们注意到, 分配速率可能会,也可能不会影响程序的实际吞吐量。 吞吐量和分配速率有一定关系, 因为分配速率会影响 minor GC 暂停, 但对于总体吞吐量的影响, 还要考虑 Major GC(大型GC)暂停, 而且吞吐量的单位不是 MB/秒, 而是系统所处理的业务量。
同时,还观察到,随着老年代的增长,每次YGC的时间变长:这是因为某些对象刚超过GCCycle limit进入老年代,这些对象还被新生代对象引用着或者被引用者,对年轻带YGC同时也会查询老年代和释放老年代
问题结论
可以考虑增加应用新生代大小,或者水平扩容应用,部署更多应用实例