JavaSE基础总结(笔试面试题)
目录
JavaSE基础
1.对象实例化
2.类的重载:
3.不定长参数,本质是一个数组形式,int...a
4.方法中使用全局变量 this
5.形参列表中的变量是局部变量
6.构造方法的作用:
7.父类和子类中,静态代码块、代码块、构造方法、普通方法执行顺序
8.修饰符修饰范围
9.子类只能继承父类非private的方法
10.instanceof
11.抽象方法不可以被private修饰
12.抽象类和接口的比较
13.匿名内部类常用于实现接口或抽象类
14.基本类型的包装类
15.Integer.parseInt()和 Integer.valueOf()
16.Object类中的方法:
17.String,StringBuffer,StringBulider的区别
18.BigDemail用于精确计算
19.集合只能存放抽象数据类型
20.两个对象相等,hashCode一定相同,但hashCode相同不一定是同一个对象
21.equals 方法被覆盖之后,hashCode也一定会被覆盖
22.ArrayList,Vector 使用数组实现,LinkedList使用的是双向链表
23.ArrayList常用方法:
24.解决ArrayList 线程不安全问题
25.解决HashMap线程不安全问题
26.堆和栈
25.集合源码分析
26.ArrayList和LinkedList区别
27.Deque 中的LinkedList 和 ArrayDeque的区别
29.final 、finally 、finalize
30.IO体系中存在的设计模式:
31.IO
32.windows 系统中使用"\"表示的路径分隔符,但是 java 中"\"转义字符 ,所以"\\" 表示路径分割,或者"/"表示路径的分割建议使用这种形式
33.集合和数据间的相互转化
34.序列化和反序列化(对象流 ObjectInputStream和ObjectOutputStream)
35.什么时候需要实现序列化,如何实现?
36.深克隆和浅克隆
37.标志性接口:
38.进程和线程的区别
39.多线程作用:
40.多线程的实现方式
42.多线程中不要调用run()方法,不然多线程会失效
43.多线程的生命周期
44.sleep(),wait()方法的区别
45.线程控制:加塞join()(插队)
46.线程安全
47.synchronized 锁对象的时候,可以使用任意的对象
48.volatile关键字
49.synchronized关键字
50.并发和并行
51.原子性问题解决方案
52.Lock锁
53.Lock锁和synchronized的区别
54.条件锁 Condition 需要结合Lock锁
54.线程池中的线程是由线程创建的,程序员只需要创建线程池就可以
55.线程池创建的四种方式
56.线程池的任务:Callable或者Runnable任务
57.四种线程池的底层:ThreaPoolExecutor
58.同步容器:synchronize修饰,产生性能影响
59.并发容器:jdk1.5提出,改善同步容器性能,专门为并发环境设计
60.HashMap、HashTable、ConcurrentHashMap的区别
61.Java中的Callable和Runnable有什么区别
62.Volatile
63.如何在两个线程间共享数据?
64.为什么wait, notify 和 notifyAll这些方法不在thread类里面
65.什么是FutureTask
66.为什么要使用线程池
67.死锁现象
68.死锁解决办法
69.检测一个线程是否有锁
70. 有三个线程T1,T2,T3,怎么确保它们按顺序执行
71.泛型的作用
72.如不指定泛型:集合中存放的数据默认为Obiect类型的
补充
1.构造方法不能被重写,但可以重载,声明为 final 的方法不能被重写,声明为 static 的方法不能被重写,但是能够被再次声明。
2.抽象的(abstract)方法是否可同时是静态的(static), 是否可同时是本地方法(native),是否可同时被 synchronized
3.静态变量、实例变量
4. == 和 equale()区别
5.switch 后类型
6.数组中没有length方法,但是有length属性,字符串有length方法,javaScript中字符串长度使用length属性
7.数据类型转换
8.流的分类
9.volatile 和 synchronized 的区别
10.叙述对于线程池的理解
11.对Java反射的理解
12.谈谈JVM的内存结构和内存分配
13.Java中的引用类型
14.栈和堆的区别
15.类的初始化
16.垃圾回收算法
17.垃圾收集算法
18.JDBC连接数据库的步骤
补充
1.什么时候使用二叉树
2.先序遍历规则
4.三次握手和四次挥手 http://blog.51cto.com/jinlong/2065461
5.HTTP请求/响应步骤
6.折半查找:最多次数 log(2n)+1
JavaSE基础
1.对象实例化
(1)Class.forName(“类的全名称”);
(2)Person person = new Person();
2.类的重载:
类名相同,形参列表不同(类型,顺载序,个数),system.out.println();也是方法重
3.不定长参数,本质是一个数组形式,int...a
- 定义方法时不确定有几个入参时使用
- 一个方法中只能有一个,位于形参末尾
4.方法中使用全局变量 this
- 全局变量(成员变量/成员属性):编写在类中
- 局部变量:声明在方法或者代码块中
5.形参列表中的变量是局部变量
6.构造方法的作用:
使用构造方法创建对象并且可以为类中的属性赋值(实例化对象)
- 构造方法在创建的时候就给对象初始化; 一个对象建立构造方法只能运行一次;
- 一般方法是对象调用才执行,给对象添加对象具备的功能; 一般方法可以被对象多次调用;
注意:多态分类
运行时多态(重写时多态)
父类引用接收子类的对象
编译时多态
方法重载方法名相同形参列表不同
7.父类和子类中,静态代码块、代码块、构造方法、普通方法执行顺序
父类中的静态变量和静态代码块
子类中的静态变量和静态代码块
父类中的普通变量和代码块->构造方法
子类中的普通变量和代码块->构造方法
变量和代码块的执行与声明顺序有关,变量一般声明在代码块前
8.修饰符修饰范围
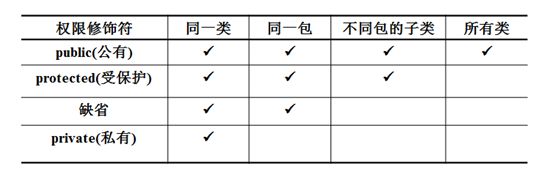
9.子类只能继承父类非private的方法
10.instanceof
instanceof是一个二元操作符,用法是:boolean result = a instanceof ClassA,即判断对象a是否是类Class A的实例,如果是的话,则返回true,否则返回false。向下转型,需要先向上转型,而且只能转化为本类对象

11.抽象方法不可以被private修饰
12.抽象类和接口的比较
|
|
抽象类 |
接口 |
| 构造方法 |
可以有 |
不可以有 |
| 方法 |
可以有抽象方法和普通方法 |
只能有抽象方法,但1.8版本之后可以有默认方法 |
| 实现 |
子类用extend来实现 |
用implments实现 |
| 修饰符 |
public、default、protected |
默认public |
| 变量 |
可以有常量也可以有变量 |
只能是静态常量默认有public static final修饰 |
| main方法 |
可以有 |
不可以有 |
| 多继承 |
单继承 |
实现多个接口 |
| 静态方法 |
可以有 |
不可以 |
| 速度 |
比较快 |
比较慢 |
13.匿名内部类常用于实现接口或抽象类
14.基本类型的包装类
int - Interger char - character
在-128~127之间的Integer值,用的是原生数据类型int,会在内存里供重用,也就是说这之间的Integer值进行==比较时只是进行int原生数 据类型的数值比较,而超出-128~127的范围,进行==比较时是进行地址及数值比较。
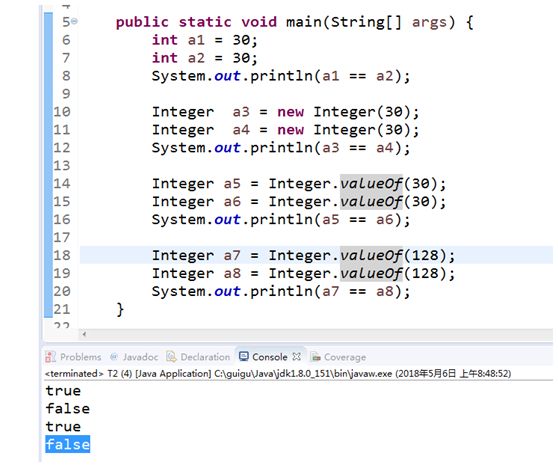
15.Integer.parseInt()和 Integer.valueOf()
Integer.parseInt()返回值为基本数据类型
Integer.valueOf()返回值为包装类型
16.Object类中的方法:
equals(),finalize(),clone(),getClass()(返回运行时的类,有且仅有一份,可用 对象.getClass() 或者 forName.getClass(),)wait(),notify(),notifyAll(),hashCode(),toString().
17.String,StringBuffer,StringBulider的区别
String只读字符串,意味着其引用的字符串内容不能发生改变
StringBuffer/StringBuilder 表示的字符串对象可以直接进行修改。
StringBuilder 是 Jdk1.5 中引入的,它和 StringBuffer 的方法完全相同,区别在于它是在单线程环境下使用的,
因为它的所有方法都没有被 synchronized 修饰,因此它的效率理论上也比StringBuffer 要高。
18.BigDemail用于精确计算

19.集合只能存放抽象数据类型
20.两个对象相等,hashCode一定相同,但hashCode相同不一定是同一个对象
21.equals 方法被覆盖之后,hashCode也一定会被覆盖
22.ArrayList,Vector 使用数组实现,LinkedList使用的是双向链表
23.ArrayList常用方法:
set(),get(),size(); HashMap常用方法:put():添加对象:get():获得对象的值;
size():查看集合中的数据有多少个
迭代方式
- for循环
- foreach
- 迭代器(collection接口下的集合都可使用)

4.jdk1.8中出现了stream流
![]()
Map迭代 (1)将Map转化为Set集合,使用keySet
Set
(2)1.8新特性
map.forEach((k,v)->{
system.out.println(k+"="+v);
});
24.解决ArrayList 线程不安全问题
(1)转化为线程安全的类
ArrayList = Collection.synchronizedList(arrayList);
(2)并发环境下可以使用CopyOnWriterList
25.解决HashMap线程不安全问题
(1)转化为线程安全类
map = Collection.synchronizedMap(map);
(2)并发环境下可以使用CurrentHashMap
26.堆和栈
堆是在程序运行时,而不是在程序编译时,申请某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。
{堆是指程序运行是申请的动态内存,而栈只是指一种使用堆的方法(即先进后出)。}栈是先进后出的,但是于堆而言却没有这个特性,两者都是存放临时数据的地方。
队列:先进先出,栈:先进后出
25.集合源码分析
(1)ArrayList
List接口可变数组非同步实现,每次扩容扩为原来的1.5倍,线程不安全
(2)Vector
API与ArrayList相同,基于数组实现,可扩容,有synchronize修饰,线程安全
(3)LinkedList
底层是双向链表,非同步,同时实现List和Deque,可以当队列使用,线程不安全
(4)ArrayDeque
使用数组实现的双端队列
(5)HashSet
底层使用哈希表实现(数组+链表),实际是由一个HashMap的实例支持的,允许使用NULL值
使用该方法时,需要重写equals和hashCode方法。
(6)LinkedHashSet
哈希表+双向链表实现
(7)HashMap
底层使用哈希表(散列链表/数组+链表)实现,数组中每一项是个单向链表,即数组和链表的结合体,可以存储NUll值,1.8之后采用
散列列表+红黑树的方式,线程不安全
(8)HashTable
底层使用数组实现,数组中每一项是个单链表,即数组和链表的结合体,key和value不能为NUll
26.ArrayList和LinkedList区别
ArrayList底层是用数组实现的顺序表,是随机存取类型,可自动扩增,并且在初始化时,数组的长度是0,只有在增加元素时,长度才会增加,默认是10,不能无限扩增,有上限,在查询操作的时候性能更好
LinkedList底层是用链表来实现的,是一个双向链表,注意这里不是双向循环链表,顺序存取类型。在源码中,似乎没有元素个数的限制。应该能无限增加下去,直到内存满了在进行删除,增加操作时性能更好。
27.Deque 中的LinkedList 和 ArrayDeque的区别
LinkedListDeque使用的是链表实现的双端队列
ArrayDeque 使用的是数组实现双端队列
28.catch 可以出现多次,首先捕获小异常,然后捕获大异常
29.final 、finally 、finalize
final 用于声明变量,方法,类,表示变量不可改变(引用不能改变,只可以改变),方法不能重写,类不可以被继承
finally 用于异常处理中,表示,必须要执行的代码块,除非java虚拟机停止工作,否则一定会执行
finalize() 是Object类中的一个方法,用于java虚拟机的垃圾回收
30.IO体系中存在的设计模式:
装饰模式 - 用于动态的给对象添加一些功能,类似于继承,但是比继承更加灵活
31.IO
BIO 传统IO,阻塞并同步 NIO,同步非阻塞 AIO 非同步非阻塞
32.windows 系统中使用"\"表示的路径分隔符,但是 java 中"\"转义字符 ,所以"\\" 表示路径分割,或者"/"表示路径的分割建议使用这种形式
33.集合和数据间的相互转化
(1)集合转数组
List list = new ArrayList();
String [] arr = list.toArray(new arr[list.size()]);
(2)数组转集合
String [] arr;
List list = Array.asLast(arr);
34.序列化和反序列化(对象流 ObjectInputStream和ObjectOutputStream)
对象序列化:将对象以二进制的形式保存到硬盘上
对象反序列化:将硬盘上的二进制文件转化为对象输出
35.什么时候需要实现序列化,如何实现?
把一个对象写入数据源或者将对象从数据源读出来,序列化对象要实现serializable接口(标志性接口,方法为空)
36.深克隆和浅克隆
浅克隆:对象需要Cloneable 并重写 clone() 方法
深克隆:对象要实现Cloneable,Serialzable接口,引用要实现Serialzable接口,先将对象以流的方式写入,然后读出,完成深克隆
37.标志性接口:
接口中的内容为空,如Cloneable和Serialzable
38.进程和线程的区别
进程指得是操作系统对于某一事件的程序实例
线程是微观的进程,进程有一个或者以上的线程组成
39.多线程作用:
降低开发和维护开销,并提高复杂应用的性能,提高资源利用率和吞吐量
40.多线程的实现方式
(1)继承Thread类并重写run()方法;
(2)实现Runnable接口并重写run方法;
(3)实现Callable接口由FeatureTask创建
(4)通过线程池创建 如ExecutorService
42.多线程中不要调用run()方法,不然多线程会失效
43.多线程的生命周期
新建:当通过new操作符创建一个线程时,处于新建状态
就绪:使用start()方法之后处于就绪状态
运行:真正执行run()方法
阻塞:执行了sleep()、wait() 方法后
死亡:当线程执行完或者因为异常退出run()方法后
44.sleep(),wait()方法的区别
sleep() 属于Thread类,wait() 属于Object类
sleep()执行后不会释放对象锁,wait()会释放对象锁,重新进入就绪状态需要notify()或者notifyAll方法
45.线程控制:加塞join()(插队)
睡眠sleep()没有放弃CPU的执行权
让步yield()放弃CPU的执行权
46.线程安全
指的是多线程访问同一个方法、对象或代码时不会产生不确定的结果
引起线程安全的原因:存在多条线程共同操作的共享数据
47.synchronized 锁对象的时候,可以使用任意的对象
48.volatile关键字
使用该关键字修饰变量 表示变量是多线程可见的。每一个线程在运行的时候自己的线程内存,线程内存中存放的是主内存的数据的拷贝。如果使用volatile关键字修饰变量,线程在使用变量的时候不是从线程内存中获取,而是从主内存中获得数据。
49.synchronized关键字
当synchronized修饰静态方法时,修饰的是当前类的class对象锁
当synchronized修饰实例方法时,修饰的时对象中的实例方法
50.并发和并行
并发:一个处理器同时处理多个任务
并行:多个处理器处理不同的任务
51.原子性问题解决方案
(1)使用同步代码块或同步方法
(2)使用原子性操作的类 java.util.concurrent.atomic 底层使用CAS实现 (CompareAndSwap)
52.Lock锁
实现类为ReentrantLock Lock lock = new ReentrantLock();
lock.lock();
53.Lock锁和synchronized的区别
Lock产生异常时不会自动释放锁 所以要在finally中释放锁(lock.unlock();)
synchronized修饰的锁产生异常时会自动释放
54.条件锁 Condition 需要结合Lock锁
54.线程池中的线程是由线程创建的,程序员只需要创建线程池就可以
55.线程池创建的四种方式
ExecutorService executor1 = executors.newSingleThreadExecutor();//创建只有一个线程的线程池
ExecutorService executor2 = executors.newFixedThreadPool(10);//创建一个固定数量线程的线程池
ExecutorService executor3 = executors.newCachedThreadPool();//创建一个可拓展的线程池,没有上限
ExecutorService executor4 = executors.newScheduledThreadPool();//创建一个可以轮序执行的56.线程池的任务:Callable或者Runnable任务
57.四种线程池的底层:ThreaPoolExecutor
58.同步容器:synchronize修饰,产生性能影响
59.并发容器:jdk1.5提出,改善同步容器性能,专门为并发环境设计
(1)HashMap(线程不安全)、HashTable(线程安全) 可以用 ConcurrentHashMap代替
(2)ArrayList、vector 可以使用 CopyOnWriteArrayList
(3)set 可以使用CopyOnWriteArraySet
(4)Queue 可以使用 ConcurrentLinkedQueue(高性能队列) 或linedBlokingQueue(阻塞队列)
https://www.jianshu.com/p/ff872995db56
60.HashMap、HashTable、ConcurrentHashMap的区别
1.HashMap线程不安全,HashTable和ConcurrentHashMap线程安全,所以HashMap运行效率高
2.HashMap的Key和Value可以是null值,HashTable和ConcurrentHashMap不行
3.HashTable和ConcurrentHashMap之间的主要差别在于性能方法。ConcurrentHashMap采用"分段锁",性能比HashTable要好
61.Java中的Callable和Runnable有什么区别
两者都用来代表线程中的任务,Runnable从1.0版本就有,Callable出现在1.5版本当中,主要区别是,Callable的call()方法可以有返回值和异常,Runnable的run()方法不行,Callable可以返回带有计算结果的Future对象
62.Volatile
volatile是一个特殊修饰符,可以保证下一个读取操作是在上一个写操作之后。
63.如何在两个线程间共享数据?
1.如果每个线程执行的代码相同,可以使用同一个Runnable对象,这个Runnable对象中有那个共享数据,例如,卖票系统就可以这么做。
2.如果每个线程执行的代码不同,这时候需要用不同的Runnable对象,
例如,设计4个线程。其中两个线程每次对j增加1,另外两个线程对j每次减1,银行存取款
64.为什么wait, notify 和 notifyAll这些方法不在thread类里面
因为Java中的锁是对象级别的,wait,notify,notifyAll等操作都是锁级别的操作
65.什么是FutureTask
在Java并发程序中FutureTask表示一个可以取消的异步运算。只有当运算完成的时候结果才能取回,如果运算尚未完成get方法将会阻塞。
66.为什么要使用线程池
因为线程的创建需要花费昂贵的资源和时间,线程池可以在程序开始运行时就创建若干线程来响应处理。
67.死锁现象
指的是两个或两个以上的线程执行过程中,为争夺资源出现相互等待的现象
68.死锁解决办法
最简单的办法是阻止循环等待条件,规定线程争夺资源是以一定的顺序进行的。
69.检测一个线程是否有锁
java.lang.Thread中的一个方法holdsLock(),返回true
70. 有三个线程T1,T2,T3,怎么确保它们按顺序执行
使用join()方法
71.泛型的作用
约束集合中数据的类型,所谓的泛型就是允许在定义类、接口、方法时使用类型形参。
72.如不指定泛型:集合中存放的数据默认为Obiect类型的
补充
1.构造方法不能被重写,但可以重载,声明为 final 的方法不能被重写,声明为 static 的方法不能被重写,但是能够被再次声明。
2.抽象的(abstract)方法是否可同时是静态的(static), 是否可同时是本地方法(native),是否可同时被 synchronized
都不能。抽象方法需要子类重写,而静态的方法是无法被重写的,因此二者是矛盾的。本地方法是由本地代码(如 C 代码)实现的方法,而抽象方法是没有实现的,也是矛盾的。 synchronized 和方法的实现细节有关,抽象方法不涉及实现细节,因此也是相互矛盾的。
3.静态变量、实例变量
静态变量属于类,实例变量依存于某一实例
4. == 和 equale()区别
一个是修饰符,一个是方法,
==:如果比较的对象是基本数据类型,则比较的是数值是否相等;如果比较的是引用数据类型,则比较的是对象的地址值是否相等,
equals():用来比较方法两个对象的内容是否相等,equals方法不能比较基本数据类型。
5.switch 后类型
byte、short、int、char、字符串、枚举
6.数组中没有length方法,但是有length属性,字符串有length方法,javaScript中字符串长度使用length属性
7.数据类型转换
(1)字符串如何转化为基本数据类型?
调用基本数据类型对应的ParseXXX(String)方法或Valueof(String)。
(2)基本数据类型转化为字符串
用“”与基本数据类型+,或是调用toString()方法。
8.流的分类
1.流的方向:输入输出流
2.实现功能:节点流和处理流
3.处理数据的单位:字节流和字符流
9.volatile 和 synchronized 的区别
(1)volatile 表示变量的值在工作内存中是不确定的,需要在主内存中去获取,synchronized 则是锁定当前变量,只有当前线程可以访问 该变量,其他线程只能被阻塞。
(2)volatile只可以使用在变量级别,synchronized可以使用在变量、方法、类级别。
(3)volatile只可以实现变量修改的可能性,不能保证原子性,而synchronized则可以保证变量修改的可见性和原子性。
(4)volatile不会造成线程阻塞,synchronizedhui造成线程的阻塞。
(5)volatile标记的变量不会被编译器优化,synchronized标记的变量可以被编译器优化
10.叙述对于线程池的理解
线程池是指事先将线程对象放到一个容器当中,这样,可以减少new线程的时间,提高代码执行的效率,通常,使用java.util.concurrent.Executor来创建线程池,可以创建四类线池,通过newSingleTHreadExecutor可以创建有一个线程的线程池,通过newFixedThreadPool创建一个指定数量的线程池,通过newCachedThreadPool可以创建一个可拓展的线程池,通过newScheduleThreadPool可以创建一个周期性执行的线程池,通过使用线程池,可以降低能源消耗,提高响应速度,调高线程的可管理性。
11.对Java反射的理解
反射就是把java类中的各种成分映射成一个个的Java对象
Java中的反射首先要能获取到Java重要反射的类的字节码,通过,Class.forName(类的全名称),类名.class和ths.getClass(),然后把字节码中的方法,变量,构造函数等映射成相应的类,然后就可以调用丰富的方法。
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制
12.谈谈JVM的内存结构和内存分配
JVM内存结构:分为四个部分:1.方法区 2.Java栈 3.Java堆 4.程序计数器)
方法区:静态分配,源代码中的命名常量,类信息、String常量和static变量都保存在方法区
栈:栈空间有可能是连续的,也有可能是不连续的,最典型的应用是方法调用(分为虚拟机栈和本地方法栈)
堆:堆内存是随意分配的
程序计数器(线程执行字节码行号)
13.Java中的引用类型
(1)强引用:垃圾回收机制不会回收
(2)软引用:内存够用不会回收,内存不够,一定回收
(3)弱引用:只要发现就会被回收
(4)虚引用:一定回收,要结合引用队列使用
14.栈和堆的区别
1.申请方式
栈:由系统自动分配
堆:程序员自己分配,并指明大小,
2.申请效率
栈:系统自动分配,速度快
堆:由new分配的内存,速度比较慢
15.类的初始化
(1)创建类的实例,new一个关键字
(2)访问某个类或接口的静态变量,或者对该静态变量赋值
(3)调用类的静态方法
(4)反射(Class.forName(“类的全名称”))
(5)初始化一个子类
16.垃圾回收算法
- 应用计数算法
- 根搜索算法
17.垃圾收集算法
- 标记-清除算法
- 复制算法
- 标记-整理算法
18.JDBC连接数据库的步骤
(1)加载jdbc驱动程序
(2)提供jdbc连接的URL地址
(3)创建数据连接
(4)创建一个Statement对象
(5)执行sql语句
(6)处理结果
(7)关闭jdbc对象
补充
1.什么时候使用二叉树
在处理大批量的动态的数据是比较有用。
2.先序遍历规则
(1)访问根节点
(2)先序遍历左子树
(3)先序遍历右子树
中序遍历规则
(1)中序遍历左子树
(2)访问根节点
(3)中序遍历右子树
后序遍历规则
(1)后序遍历左子树
(2)后序遍历右子树
(3)访问根节点
4.三次握手和四次挥手 http://blog.51cto.com/jinlong/2065461
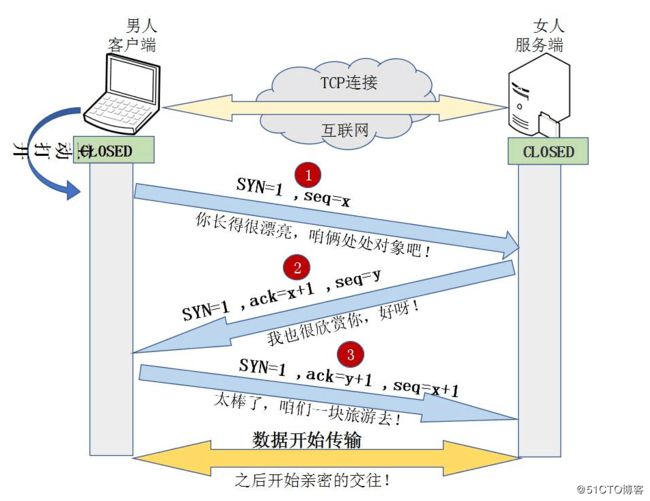
(1)三次握手(TCP连接的建立):为了建立可靠通信信道
a.由客户端建立TCP连接的请求报文,其中报文中含有seq序列号,是由发送端
随机生成的,并且将报文中的SYN字段设置问1,表示需要建立TCP连接。
( SYN=1,seq=x,x为随机生成数值)
b.由服务器回复客户端发送的TCP连接请求报文,其中seq是序列号,是由服务器随机生成,并将SYN设置为1,而且会产生ACK字段,ACK的数值是客户端发送过来的序列号seq的基础上+1,进行回复,以便客户端收到信息时,知晓自己的TCP建立请求已得到验证(SYN=1,ACK=x+1,seq=y,y为随机生成数值)这里的ack加1可以理解为是确认和谁建立连接。
c.客户端收到服务端发送的TCP连接建立验证请求后,会使自己的序列号加1表示,并且在此回复ACK验证请求。(SYN=1,ACK=y+1,seq=x+1)
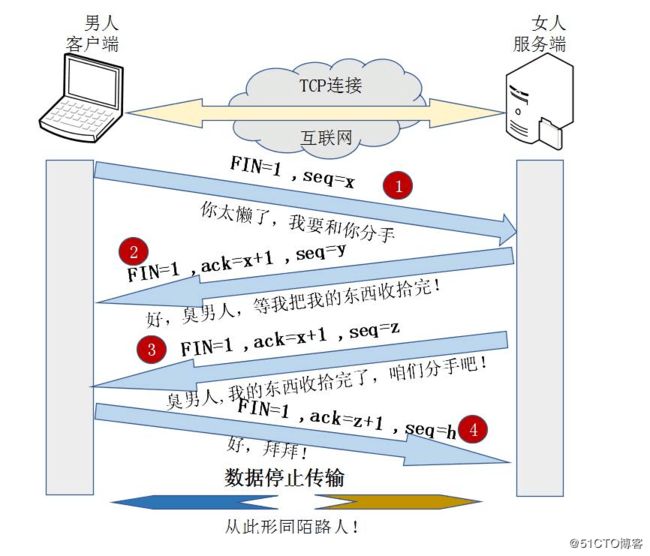
(2)四次挥手(TCP连接的断开):
a.客户端发送断开的TCP请求报文,其中报文中包含seq序列号,是由发送端随机生成,并且将报文中的FiN字段设置为1,表示需要断开TCP连接,(FIN=1,seq=x,x由客户端随机生成)
b.服务端会回复客户端发送的TCP断开请求报文,其包含seq序列号,是由回复端随机生成的而且会产生ZCK字段,ACK字段实在客户端发送过来的seq序列号基础上+1进行回复的,以便客户端收到收到信息时,知晓自己的TCP断开请求已经得到了验证。
c.服务端在回复完客户端的TCP断开请求后,不会马上进行TCP的连接断开,服务端会确保断开前,所有的输送数据传输完毕,一旦确认传输数据完毕,将会将回复报文的FIN字段设置为1,并且产生seq序列号。(FIN=1,ACK=x+1,seq=z,z由服务端随机生成)
d.客户端收到服务端的TCP断开请求后,会回复服务端的断开请求,包含随机生成的seq字段和ACK字段,ACK会在服务器的TCP断开请求的seq基础上+1.从而完成服务端请求的验证回复。(FIN=1,ACK=z+1,seq=h,h为客户端随机生成)。
5.HTTP请求/响应步骤
(1)客户端连接到Web服务器
(2)发送http请求
(3)服务器接受请求并返回Http响应
(4)释放连接
(5)客户端浏览器解析HTML内容