蚂蚁金服推出分布式的图神经知识表示框架,性能和可扩展性俱佳


出品 | CSDN(ID:CSDNnews)
日前,今年的机器学习国际顶级会议ICML(International Conference on Machine Learning)公布论文接收情况。据统计,ICML 2020共提交4990篇论文,投稿数量再创新高,而最终接收论文1088篇,接收率21.8%。与往年相比,接收率逐年走低。
由蚂蚁集团算法工程师胡斌斌、高级算法专家张志强、资深算法专家周俊和北京邮电大学教授石川联合撰写的《KGNN:Distributed Framework for Graph Neural Knowledge Representation》顺利入选ICML2020 workshop(Bridge Between Perception and Reasoning: Graph Neural Networks & Beyond),该workshop由知名学者唐建、蚂蚁集团研究员宋乐、斯坦福大学终身教授Jure Leskovec联合举办,并邀请了人工智能奠基者之一的Yoshua Bengio进行了keynote报告,该workshop旨在将不同领域(如深度学习、逻辑/符号推理、统计关系学习和图算法等)的研究人员聚集起来讨论系统和系统智能之间的潜在接口和集成,探索理论基础、模型和算法方面的新进展,沉淀新基准数据集和有影响力的应用。以下为该论文的解读。

前言
知识表示学习主要用于将知识图(KG)融入各种在线服务中以提升各个应用的性能。现有的知识表示学习方法虽然在性能上有了很大的提高,但它们忽略了高阶结构和丰富的属性信息,导致在语义丰富的知识图谱上性能不佳。另外,这些方法不能进行归纳式的预测,也不能适用于大型工业图。
为了解决这些问题,我们开发了一个新的框架KGNN在分布式学习系统中来充分利用知识数据进行表示学习。KGNN配置了基于GNN的编码器和知识感知的解码器,目的是以细粒度的方式将高阶结构和属性信息结合在一起,并保留知识图谱中的关系模式。我们在三个数据集上进行了链接预测和三元组的分类实验,验证了该框架的有效性和可扩展性。

简介
知识图谱(KG)通常以三元组⟨头实体,关系,尾实体⟩的形式表示实体及其丰富的异构关系。例如在图1(a)中,三元组⟨Bob, work_in, Apple⟩表示关系work_in连接了两个实体: Bob和Apple。知识图谱因其丰富的结构化信息,在信息检索、知识问答和推荐系统等诸多研究领域引起了广泛关注。为了灵活地利用知识图谱,通过知识表示学习来进行图谱补全、对齐和推理已经成为一个新兴的方向。
知识表示学习旨在将实体和关系映射到一个低维空间,并同时保留原始网络的特定信息。这些方法可以大致分为平移距离式模型(如TransE、TransR等)和语义匹配式模型(如DistMult、ConvE等),分别利用基于距离和基于相似性的评分函数进行知识表示学习。
尽管这些方法在一定程度上提高了性能,但它们仍然存在一些局限性。首先,他们独立处理每个三元组,并且丰富的属性节点和边通常被忽视,导致在语意丰富的知识图谱上无法取到满意的性能。其次,他们是天生的直推式(Transductive)模型,即无法对没出现在训练集中的实体进行预测。最后,这些方法无法处理包含数以百万计的实体和关系的工业级的大规模知识图谱。
为了解决这些问题,本文旨在建立一个可扩展的分布式知识图表示框架,以灵活地提取丰富的知识,供下游应用使用。该框架需要满足以下三个关键特性:(1)语义丰富: 高阶结构和属性信息能够有效地保存原始图的属性。因此,我们的目标是把这些信息融入知识图表示,全面捕捉知识图谱中的丰富语义。(2)归纳式(Inductive):目前知识图谱通常是不完整的,在真实的应用中,新实体将每天出现。这要求我们对未出现在训练集中的实体进行动态预测。
(3)可扩展性:由于现实工业场景中的知识图谱是非常大规模的,需要在分布式学习系统上实现可扩展的知识图表示框架。为了综合上述主要思想,我们提出了基于图神经网络的编码器和知识感知解码器的分布式图神经知识表示框架KGNN。在图神经网络的帮助下,KGNN在归纳式的、端到端的框架中同时捕获属性信息和高阶结构。
显然,KGNN是一个灵活的框架,可以配备任意的GNN编码器,本文引入了一种基于注意力机制的GNN来定位细粒度语义中重要的相关关系或结构。为了对真实的知识图谱上进行有效的模型训练和推理,我们在分布式学习系统上实现了KGNN,并揭示了其实现细节。我们在三个真实数据集上进行了链接预测和三元组分类任务的实验,验证了所提出的KGNN框架的有效性和可扩展性。

图1 KGNN示意图

KGNN模型
如图1(b)所示,KGNN模型主要有两部分构成,基于GNN的编码器和知识感知的解码器。
基于GNN的编码器。我们采用图神经网络将结构知识和属性编码到实体表示中。具体来说,GNN通过聚合来自其邻居的信息,递归地更新节点的表示。随后,k次更新后的节点的最终表示会捕获k跳邻居内部的结构信息以及节点属性。形式化上来讲,我们可以通过聚合函数f(A)和更新函数f(U)来利用节点v的邻居集合Nv计算出节点v的第k + 1次表示:
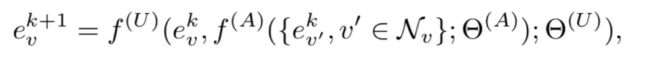
对于细粒度建模,我们引入了一个基于关注的GNN来衡量每个关系的各种潜在偏好。根据上述公式中实体表示的更新原则,我们首先将聚合函数f(A)表示为:
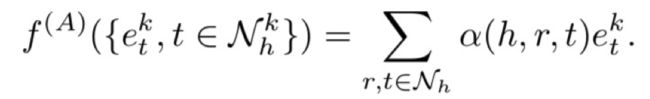
受跳跃知识(JumpingKnowledge)网络思想的启发,我们采用自适应深度函数灵活地多跳邻居,以更好地实现结构感知表示。这里应用LSTM实现f(U)进行表示更新。因此,我们可以得到实体h的k + 1表示为:

其中ehk表示节点h的聚合信息,通过f(A)计算而来。
知识感知的解码器。知识图谱中链路预测的关键是利用观测到的三元组来推断对称、反对称、合成等关系模式。为了自适应地保留知识图谱不同的关系模式,KGNN采用知识感知的评分函数作为解码器。以TransH为例, 我们将三元组⟨h, r, t⟩通过K跳更新后的评分函数表示为s(eKh, er,eKt),呃,投影。然后通过基于间隔的负采样目标函数端到端训练KGNN:
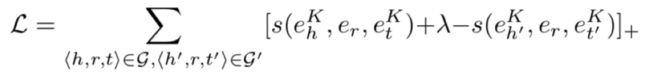

分布式实现
现在我们探索KGNN的分布式实现,它为大规模知识图表示提供了一个完整的解决方案。如图1(c)所示,分布式KGNN由三部分组成:
图的存储系统。在分布式架构下,将整个知识图以及相应的属性信息存储在节点上。在有效的数据压缩技术的帮助下,它能够服务于大型工业图。
采样器。主要包含了知识表示的负采样器和子图采样器。负采样器在一个有效三元组中随机替换头实体或尾实体,以生存相应的负三元组。然后,子图采样器将批量随机收集每个实体的k跳邻居集。值得注意的是,我们将子图提供给KGNN,而不是完整的图,这有助于减少时间和内存开销。
训练器。它由多个worker和参数服务器组成,由协调器控制。为了有效地更新参数,每个worker都从参数服务器提取参数,并在训练期间独立地更新它们。在一个特定的worker中,KGNN自然遵循这样的工作流程:(1)预处理子图并解析模型配置。(2)利用之前介绍的编码器和解码器,基于子图生成实体和关系的表示。(3)优化一个特定的损失来指导模型的学习。

实验
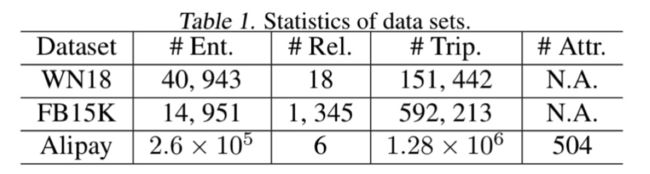
我们在WN18,FB15K和Alipay三个数据集上进行了实验,具体在链路预测和三元组分类两个任务上验证了有效性。实验数据集如下所示。
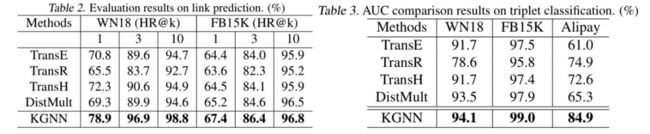
链路预测和三元组分类的结果如下所示:
另外,我们做了不同跳邻居对模型性能的影响,如下所示,实验结果验证了高阶信息的有效性,但过高的邻居信息会导致over-smooth的问题,导致性能有所下降。

最后我们做了KGNN的性能试验,如下所示。

如图所示,在WN18K和FB15K这两个数据集上。我们将worker数从2增加到16,可以明显地加速KGNN的训练。与此同时,随着worker数量的增加,预测性能几乎没有损失。

结语
在本文中, 我们介绍了分布式的知识图表示框架KGNN。它包含基于GNN的编码器和知识感知的解码器,可以同时利用图谱的高阶结构信息和属性信息,并能保存图谱中的关系模式。我们在分布式计算平台上实现了KGNN,并用大量的试验验证了它的有效性和可扩展性。在未来的工作中,我们将致力于解决图神经网络在利用高阶邻居时遇到的over-smooth问题,以及如何对动态知识图谱进行有效的表达。


更多精彩推荐
☞98年“后浪”科学家,首次挑战图片翻转不变性假设,一作拿下 CVPR 最佳论文提名
☞饿了么四年、阿里两年:研发路上的一些总结与思考
☞GPT-3 的到来,程序员会被 AI 取代吗?
☞残差网络的前世今生与原理 | 赠书
☞推特惊爆史诗级漏洞,App 恶意窃取用户隐私,云端安全路向何方?
☞干货 | 了解 Geth 客户端:快照加速机制
点分享点点赞点在看