shell编程--正则表达式(基础正则表达式grep、扩展正则表达式egrep)
文章目录
- 一、正则表达式概述
- 1.1 正则表达式定义
- 1.2 正则表达式用途
- 二、基础正则表达式
- 2.1 基础正则表达式和示例
- 2.1.1 查找特定字符
- 2.1.2 利用中括号“[]”来查找集合字符
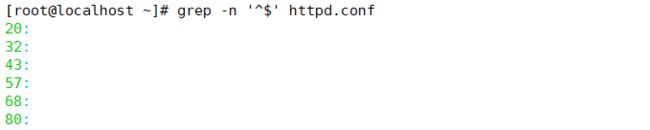
- 2.1.3 查找行首“^”与行尾字符“$”
- 2.1.4 查找任意一个字符“.”与重复字符“*”
- 2.1.5 查找连续字符范围“{}”
- 2.2 元字符总结
- 三、扩展正则表达式
- 3.1 扩展正则表达式常见元字符
- 3.2 扩展正则表达式和示例
- 3.2.1 验证元字符"+"
- 3.2.2 验证元字符"?"
- 3.2.3 验证元字符"|"
- 3.2.4 验证元字符"()"
- 3.2.5 验证元字符"()+"
一、正则表达式概述
1.1 正则表达式定义
正则表达式又称正规表达式、常规表达式。在代码中常简写为 regex、regexp 或 RE。正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,简单来说, 是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串。
正则表达式是由普通字符与元字符组成的文字模式。
- 普通字符包括大小写字母、数字、标点符号及一些其他符号
- 元字符则是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
1.2 正则表达式用途
正则表达式对于系统管理员来说是非常重要的,系统运行过程中会产生大量的信息,系统管理员可以通过正则表达式快速提取“有问题”的信息。如此一来,可以将运维工作变得更加简单、方便。
二、基础正则表达式
正则表达式的字符串表达方法根据不同的严谨程度与功能分为基本正则表达式与扩展正则表达式。基础正则表达式是常用正则表达式最基础的部分。在 Linux 系统中常见的文件处理工具中 grep 与 sed 支持基础正则表达式,而 egrep 与 awk 支持扩展正则表达式。
2.1 基础正则表达式和示例
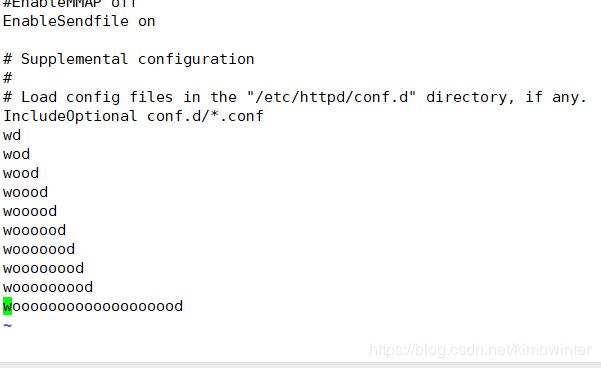
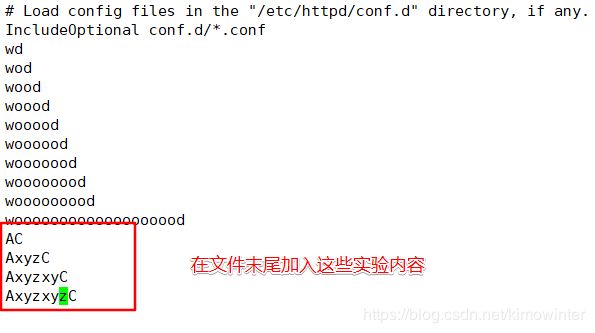
事先下载一个httpd服务,将httpd的配置文件/etc/httpd/conf/httpd.conf复制一份到家目录,以便实验用,并在配置文件的末尾写入部分实验用的内容,如图所示。
2.1.1 查找特定字符
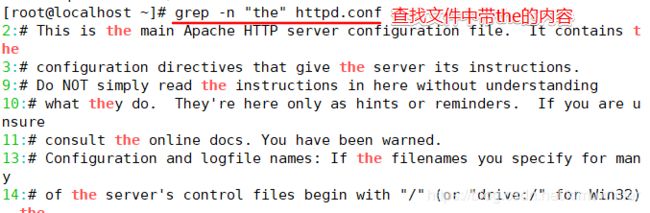
首先是用我们熟悉的"grep"命令其中“-n”表示显示行号、“-i”表示不区分大小写,符合标准的字符,字体颜色会转换成红色。
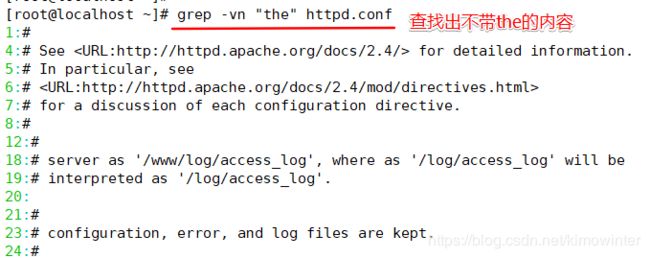
若反向选择,如查找不包含“the”字符的行,则需要通过 grep 命令的“-v”选项实现,并配合“-n”一起使用显示行号。
2.1.2 利用中括号“[]”来查找集合字符
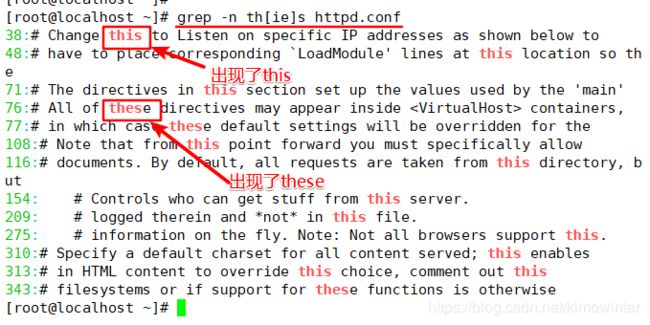
想要查找"this"、“these"这两个字符串时,可以发现这两个字符都包含"th"和"s”,执行以下命令可以同时查找这两个字符串。其中“[]”中无论有几个字符, 都仅代表一个字符,也就是说“[ie]”表示匹配“i”或者“e”。
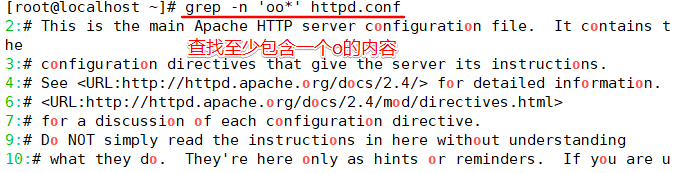
查找包含重复单个字符“oo”
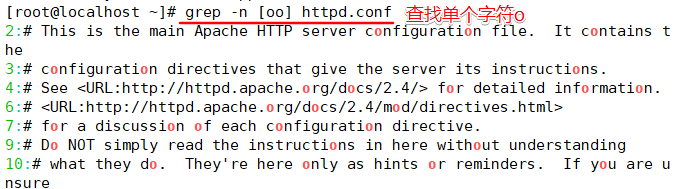
查找“oo”前面不是“w”的字符串,只需要通过集合字符的反向选择“[^]”来实现。
“^”符号在元字符集合“[]”符号内外的作用是不一样的,在“[]”符号内表示反向选择,在“[]” 符号外则代表定位行首。
[root@localhost ~]# grep -n '[^w]oo' httpd.conf

2.1.3 查找行首“^”与行尾字符“$”
若不希望“oo”前面存在小写字母,可以使用“grep -n‘[^a-z]oo’httpd.conf”命令实现,其中“a-z”表示小写字母,“A-Z”表示大写字母,"0-9"表示数字。
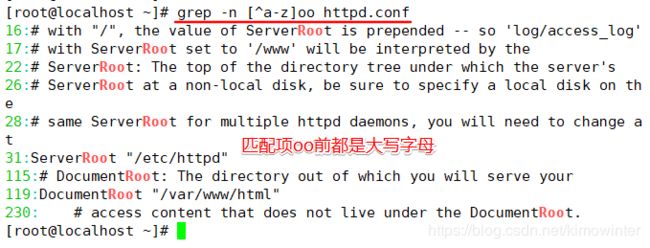
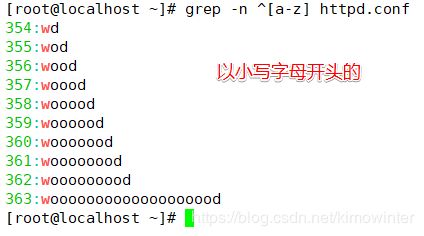
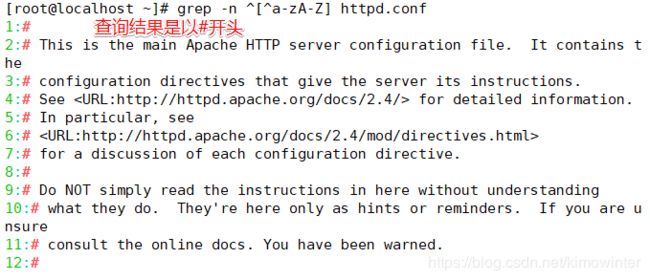
查询以小写字母开头的行可以通过“^[a-z]”规则来过滤,查询大写字母开头的行则使用
“^[A-Z]”规则,若查询不以字母开头的行则使用“^[^a-zA-Z]”规则。
查找以某一特定字符结尾的行则可以使用“$”定位符。
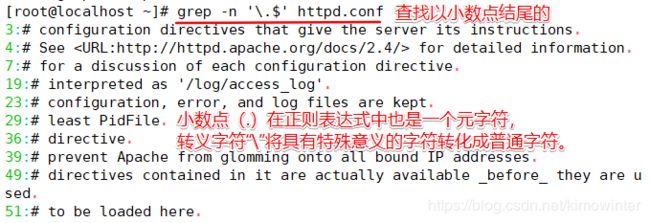
查询空白行
2.1.4 查找任意一个字符“.”与重复字符“*”
在正则表达式中小数点(.)也是一个元字符,代表任意一个字符
查找“w??d”的字符串

“”代表的是重复零个或多个前面的单字符,这里一定要记住0个也包含在里面。
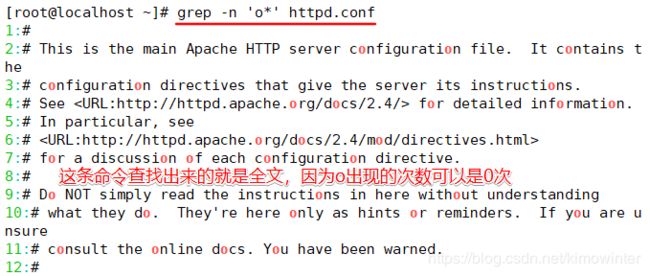
grep -n 'oo’ httpd.conf这条命令就是至少包含一个"o"。
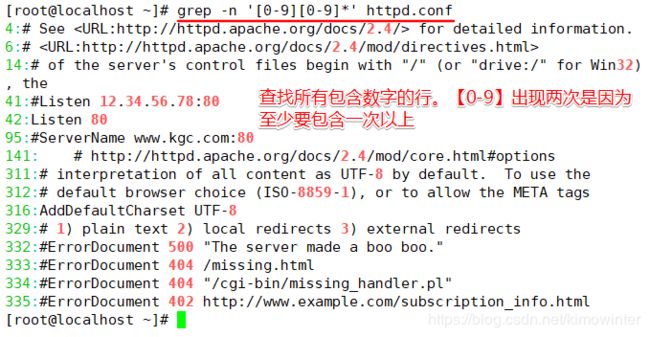
查找所有包含数字的内容
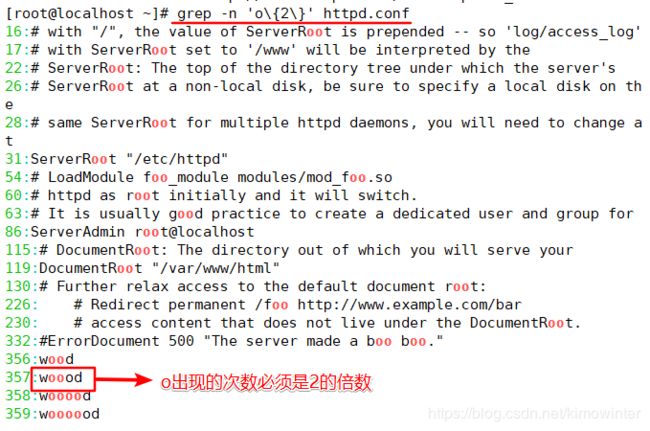
2.1.5 查找连续字符范围“{}”
基础正则表达式中的限定范围的字符“{}”,“{}”在 Shell 中具有特殊意义,所以在使用“{}”字符时,需要利用转义字符“\”,将“{}”字符转换成普通字符。

2.2 元字符总结
| 元字符 | 作用 |
|---|---|
| ^ | 匹配输入字符串的开始位置。除非在方括号表达式中使用,表示不包含该字符集合。要匹配“^” 字符本身,请使用“^” |
| $ | 匹配输入字符串的结尾位置。如果设置了RegExp 对象的 Multiline 属性,则“KaTeX parse error: Undefined control sequence: \n at position 6: ”也匹配‘\̲n̲’或‘\r’。要匹配“”字符本身,请使用“$” |
| . | 匹配除“\r\n”之外的任何单个字符 |
| \ | 反斜杠,又叫转义字符,去除其后紧跟的元字符或通配符的特殊意义 |
| * | 匹配前面的子表达式零次或多次。要匹配“*”字符,请使用“*” |
| [] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a” |
| [^] | 赋值字符集合。匹配未包含的一个任意字符。例如,“[^abc]”可以匹配“plain”中任何一个字母 |
| [n1-n2] | 字符范围。匹配指定范围内的任意一个字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意一个小写字母字符。注意:只有连字符(-)在字符组内部,并且出现在两个字符之间时,才能表示字符的范围;如果出现在字符组的开头,则只能表示连字符本身 |
| {n} | n 是一个非负整数,匹配确定的 n 次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的“oo” |
| {n,} | n 是一个非负整数,至少匹配 n 次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*” |
| {n,m} | m 和 n 均为非负整数,其中 n<=m,最少匹配 n 次且最多匹配m 次 |
三、扩展正则表达式
扩展正则表达式是为了简化整个指令,例如,使用基础正则表达式查询除文件中空白行与行首为“#”之外的行(通常用于查看生效的配置文件),执行“grep -v ‘^KaTeX parse error: Expected group after '^' at position 25: …onf | grep -v ‘^̲#’”即可实现。这里需要使用管… | ^#’ httpd.conf”,其中,单引号内的管道符号表示或者(or)。
使用扩展正则表达式,需要使用 egrep 或 awk 命令,egrep 命令是一个搜索文件获得模式,使用该命令可以搜索文件中的任意字符串和符号,也可以搜索一个或多个文件的字符串,一个提示符可以是单个字符、一个字符串、一个字或一个句子。
3.1 扩展正则表达式常见元字符
| 元字符 | 作用及示例 |
|---|---|
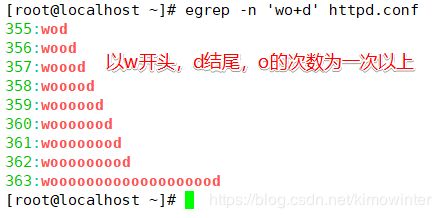
| + | 作用:重复一个或者一个以上的前一个字符;示例:执行“egrep -n ‘wo+d’ test.txt”命令,即可查询"wood" “woood” "woooooood"等字符串 |
| ? | 作用:零个或者一个的前一个字符;示例:执行“egrep -n ‘bes?t’ test.txt”命令,即可查询“bet”“best”这两个字符串 |
| I | 作用:使用或者(or)的方式找出多个字符;示例:执行“egrep -n 'of |
| () | 作用:查找“组”字符串;示例:“egrep -n ‘t(aIe)st’ test.txt”。“tast”与“test”因为这两个单词的“t”与“st”是重复的,所以将“a”与“e”列于“()”符号当中,并以“I”分隔,即可查询"tast"或者"test"字符串 |
| ()+ | 作用:辨别多个重复的组;示例:“egrep -n ‘A(xyz)+C’ test.txt”。该命令是查询开头的"A"结尾是"C",中间有一个以上的"xyz"字符串的意思 |
3.2 扩展正则表达式和示例
我们现在文件中再加入部分内容,方便验证扩展正则表达式。
3.2.1 验证元字符"+"
重复一个或者一个以上的前一个字符(o)
3.2.2 验证元字符"?"
零个或者一个的前一个字符(o),等同于"grep -n ‘wo{0,1}d’ httpd.conf "

3.2.3 验证元字符"|"
管道符号表示或者的意思
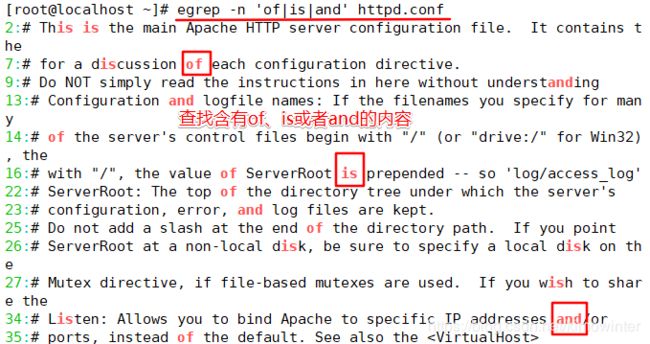
3.2.4 验证元字符"()"
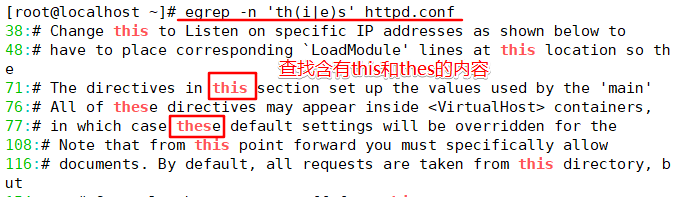
等价于命令"grep -n ‘th[ie]s’ httpd.conf"
3.2.5 验证元字符"()+"
