reactor和proactor模式 同步异步 阻塞 非阻塞
Reactor模式,或者叫反应器模式
高性能IO设计的Reactor和Proactor模式
首先就第一篇《Reactor模式,或者叫反应器模式》做一下笔记:
刚开店做生意,老板为了给顾客一个美好的印象,给顾客最好的服务,一对一:
随着经营的生意越来越好,顾客多了,不能服务员也多吧,那样得支出的成本也太大了,要是一下子来个1000个顾客,难道老板还得养活1000个服务员,没办法,得改变这种服务模式,但又不能让顾客感到这里的服务下降了,怎么办呢?

改革以后,有没有觉得和我们平时去大排档啊,街边小吃店的服务模式很相似是不是,
为什么不说和酒店服务很像,其实还真不像,一般XXX星级的饭店的服务,还真是上一种经营模式,为什么他们要这样呢,
因为,他们是高富帅啊,顾客消费也高,自然老板的收入也高,所以老板也乐子不疲啊。我们是屌丝,请客都只是去个大排档就好了。
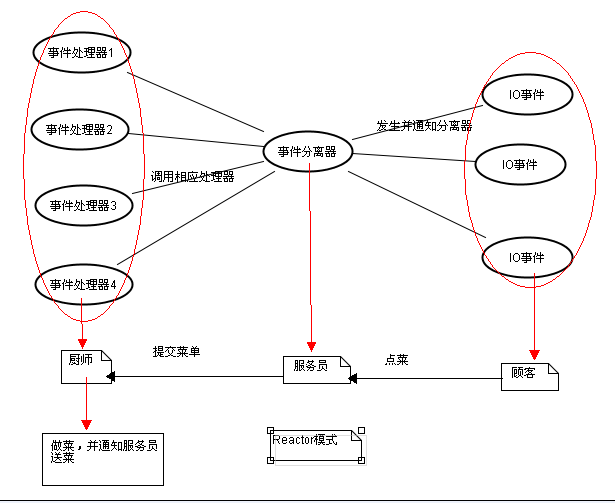
改革后的模式就是reactor模式,顾客通过呼叫服务员(event事件)通知服务员,菜单写好了,服务员就会把菜单交给厨师(事件处理器),厨师就会去做菜了。
现在知道reactor模式的由来了吧,知道一个事情的始末会让我们更好的理解它。
下面对第二篇《高性能IO设计的Reactor和Proactor模式》做一下笔记:
这里主要是讲reactor模式和proactor模式的区别:其实就是对数据处理方式变了导致监听事件方式也转变了。
当然,如果还是以第一篇那样以饭店的经营模式来讲解的话,proactor模式应该是这样的:
我们知道每一个饭店都有自己的招牌菜去吸引顾客。当然,其实这道菜你也会做,只是别人做的比你更好,更美味。有一天,一群高富帅来了这家大拍档:

老板就是老板,人面广啊,自家厨师不会做,可以让更专业的人去做,省时省事省心啊!
其实这里我们都能看出reactor模式和proactor模式的一点点区别了吧!只是还不了解具体的细节。
第二篇《性能IO设计的Reactor和Proactor模式》就是干这个事的,给我们介绍具体细节和区别,我也是读了好几遍,慢慢画个流程图才理解了啊。
其实说到底就是一句广告语:把事情交给更专业的人,你会更开心。
好吧,以下是copy过来,做了少少修改的:转换为自己的理解。
在高性能的I/O设计中,有两个比较著名的模式Reactor和Proactor模式,其中Reactor模式用于同步I/O,而Proactor运用于异步I/O操作。
在比较这两个模式之前,我们首先的搞明白几个概念,什么是阻塞和非阻塞,什么是同步和异步;
举例说明:
老张爱喝茶,废话不说,煮开水。
出场人物:老张,水壶两把(普通水壶,简称水壶;会响的水壶,简称响水壶)。
1 老张把水壶放到火上,立等水开。(同步阻塞)
老张觉得自己有点傻
2 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞)
老张还是觉得自己有点傻,于是变高端了,买了把会响笛的那种水壶。水开之后,能大声发出嘀~~~~的噪音。
3 老张把响水壶放到火上,立等水开。(异步阻塞)
老张觉得这样傻等意义不大
4 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)
老张觉得自己聪明了。
所谓同步异步,只是对于水壶而言。
普通水壶,同步;响水壶,异步。
虽然都能干活,但响水壶可以在自己完工之后,提示老张水开了。这是普通水壶所不能及的。
同步只能让调用者去轮询自己(情况2中),造成老张效率的低下。
所谓阻塞非阻塞,仅仅对于老张而言。
立等的老张,阻塞;看电视的老张,非阻塞。
情况1和情况3中老张就是阻塞的,媳妇喊他都不知道。虽然3中响水壶是异步的,可对于立等的老张没有太大的意义。所以一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
同步和异步是针对应用程序和内核的交互而言的;
同步指的是用户进程触发IO操作并等待或者轮询的去查看IO操作是否就绪,
异步是指用户进程触发I O操作以后便开始做自己的事情,而当IO操作已经完成的时候会得到IO完成的通知。
阻塞和非阻塞是针对于进程在访问数据的时候,根据IO操作的就绪状态来采取的不同方式,说白了是一种读取或者写入操作函数的实现方式;
阻塞方式下读取或者写入函数将一直等待,
非阻塞方式下,读取或者写入函数会立即返回一个状态值。
同步就是当一个进程发起一个函数(任务)调用的时候,一直等待直到函数(任务)完成,而进程继续处于激活状态。而异步情况下是当一个进程发起一个函数(任务)调用的时候,不会等函数返回,而是继续往下执行当,函数返回的时候通过状态、通知、事件等方式通知进程任务完成。
阻塞是当请求不能满足的时候就将进程挂起,而非阻塞则不会阻塞当前进程,即阻塞与非阻塞针对的是进程或线程而同步与异步所针对的是功能函数。
一般来说I/O模型可以分为:同步阻塞,同步非阻塞,异步阻塞,异步非阻塞IO
同步阻塞I/O:
最常用的一个模型是同步阻塞 I/O 模型。在这个模型中,用户空间的应用程序执行一个系统调用,这会导致应用程序阻塞。这意味着应用程序会一直阻塞,直到系统调用完成为止(数据传输完成或发生错误)。调用应用程序处于一种不再消费 CPU 而只是简单等待响应的状态,因此从处理的角度来看,这是非常有效的。在调用 read 系统调用时,应用程序会阻塞并对内核进行上下文切换。然后会触发读操作,当响应返回时(从我们正在从中读取的设备中返回),数据就被移动到用户空间的缓冲区中。然后应用程序就会解除阻塞(read 调用返回)。从应用程序的角度来说,read 调用会延续很长时间。实际上,在内核执行读操作和其他工作时,应用程序的确会被阻塞。
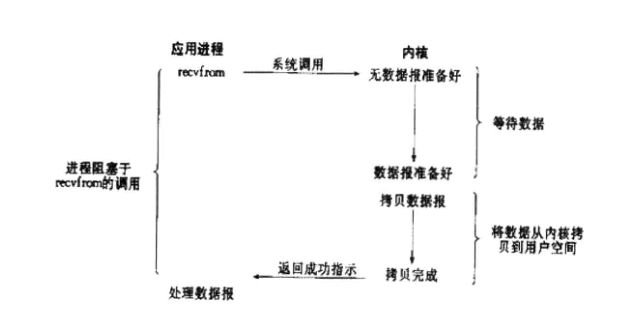
阻塞I/O模型
同步非阻塞I/O:
在这种模型中,设备是以非阻塞的形式打开的。这意味着 I/O 操作不会立即完成,read 操作可能会返回一个错误代码,说明read请求不能立即满足。需要应用程序调用许多次来等待操作完成。这可能效率不高,因为在很多情况下,当内核执行这个命令时,应用程序必须要进行忙碌等待,直到数据可用为止,或者试图执行其他工作。这个方法可以引入 I/O 操作的延时,因为数据在内核中变为可用到用户调用read 返回数据之间存在一定的间隔,这会导致整体数据吞吐量的降低。
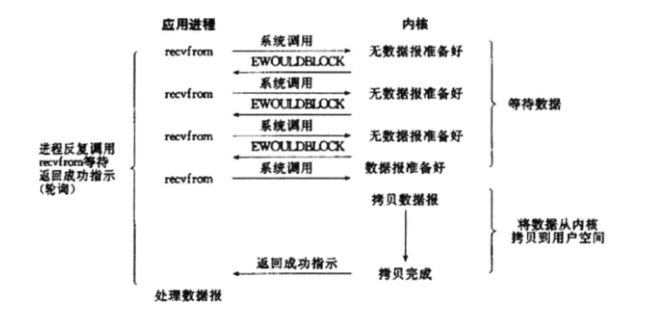
非阻塞I/O模型
异步阻塞I/O:
个人觉得谈这种模型的意义不大,以为请求线程已经阻塞,那么异步的作用就不大了。但还有一种理解就是这里的阻塞是通知的阻塞,而不是请求线程的阻塞,也就是一种带有阻塞通知的非阻塞 I/O。在这种模型中,配置的是非阻塞 I/O,然后使用阻塞select 系统调用来确定一个 I/O 描述符何时有操作。使 select 调用非常有趣的是它可以用来为多个描述符提供通知,而不仅仅为一个描述符提供通知。对于每个提示符来说,我们可以请求这个描述符可以写数据、有读数据可用以及是否发生错误的通知。
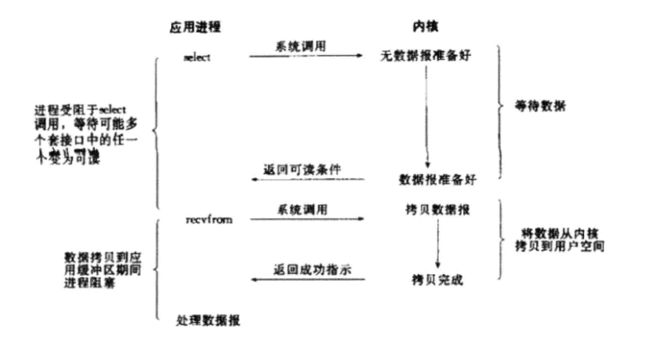
复用I/O模型
异步非阻塞I/O:
异步非阻塞 I/O 模型是一种处理与 I/O 重叠进行的模型。读请求会立即返回,说明 read 请求已经成功发起了。在后台完成读操作时,应用程序然后会执行其他处理操作。当 read 的响应到达时,就会产生一个信号或执行一个基于线程的回调函数来完成这次 I/O 处理过程。在一个进程中为了执行多个 I/O 请求而对计算操作和 I/O 处理进行重叠处理的能力利用了处理速度与 I/O 速度之间的差异。当一个或多个 I/O 请求挂起时,CPU 可以执行其他任务;或者更为常见的是,在发起其他 I/O 的同时对已经完成的 I/O 进行操作。
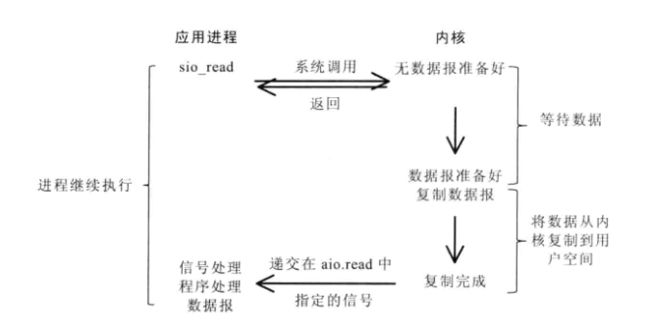
异步I/O模型
搞清楚了以上概念以后,我们再回过头来看看,Reactor模式和Proactor模式。
首先来看看Reactor模式,Reactor模式应用于同步I/O的场景。我们以读操作为例来看看Reactor中的具体步骤:
读取操作:
1. 应用程序注册读就需事件和相关联的事件处理器
2. 事件分离器等待事件的发生
3. 当发生读就需事件的时候,事件分离器调用第一步注册的事件处理器
4. 事件处理器首先执行实际的读取操作,然后根据读取到的内容进行进一步的处理
下面我们来看看Proactor模式中读取操作和写入操作的过程:
读取操作:
1. 应用程序初始化一个异步读取操作,然后注册相应的事件处理器,此时事件处理器不关注读取就绪事件,而是关注读取完成事件,这是区别于Reactor的关键。
2. 事件分离器等待读取操作完成事件
3. 在事件分离器等待读取操作完成的时候,操作系统调用内核线程完成读取操作,并将读取的内容放入用户传递过来的缓存区中。这也是区别于Reactor的一点,Proactor中,应用程序需要传递缓存区。
4. 事件分离器捕获到读取完成事件后,激活应用程序注册的事件处理器,事件处理器直接从缓存区读取数据,而不需要进行实际的读取操作。
Proactor中写入操作和读取操作,只不过感兴趣的事件是写入完成事件。
从上面可以看出,Reactor和Proactor模式的主要区别就是真正的读取和写入操作是有谁来完成的,Reactor中需要应用程序自己读取或者写入数据,而Proactor模式中,应用程序不需要进行实际的读写过程,它只需要从缓存区读取或者写入即可,操作系统会读取缓存区或者写入缓存区到真正的IO设备.
综上所述,同步和异步是相对于应用和内核的交互方式而言的,同步 需要主动去询问,而异步的时候内核在IO事件发生的时候通知应用程序,而阻塞和非阻塞仅仅是系统在调用系统调用的时候函数的实现方式而已。
最后来两张图做个总结: