数据结构 —— 哈夫曼(huffman)树和哈夫曼编码及压缩
择取两篇博客
1 https://www.cnblogs.com/kubixuesheng/p/4397798.html
2 https://www.cnblogs.com/liguangsunls/p/7207265.html
哈夫曼树的构造(哈夫曼算法)
1.根据给定的n个权值{w1,w2,…,wn}构成二叉树集合F={T1,T2,…,Tn},其中每棵二叉树Ti中只有一个带权为wi的根结点,其左右子树为空.
2.在F中选取两棵根结点权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根结点的权值为左右子树根结点的权值之和.
3.在F中删除这两棵树,同时将新的二叉树加入F中.
4.重复2、3,直到F只含有一棵树为止.(得到哈夫曼树)
路径:若树中存在一个结点序列k1,k2,…,kj,使得ki是ki+1的双亲,则称该结点序列是从k1到kj的一条路径。
路径长度:等于路径上的结点数减1。
结点的权:在许多应用中,常常将树中的结点赋予一个有意义的数,称为该结点的权。
结点的带权路径长度:是指该结点到树根之间的路径长度与该结点上权的乘积。
树的带权路径长度:树中所有叶子结点的带权路径长度之和,通常记作:
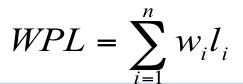
其中,n表示叶子结点的数目,wi和li分别表示叶子结点ki的权值和树根结点到叶子结点ki之间的路径长度。
赫夫曼树(哈夫曼树,huffman树)定义:
在权为w1,w2,…,wn的n个叶子结点的所有二叉树中,带权路径长度WPL最小的二叉树称为赫夫曼树或最优二叉树。
关于哈夫曼树的注意点:
1、满二叉树不一定是哈夫曼树
2、哈夫曼树中权越大的叶子离根越近 (很好理解,WPL最小的二叉树)
3、具有相同带权结点的哈夫曼树不惟一
4、哈夫曼树的结点的度数为 0 或 2, 没有度为 1 的结点。
5、包含 n 个叶子结点的哈夫曼树中共有 2n – 1 个结点。
6、包含 n 棵树的森林要经过 n–1 次合并才能形成哈夫曼树,共产生 n–1 个新结点
为什么能压缩
压缩的时候当我们遇到了文本中的1 、 2 、 3 、 4 几个字符的时候,我们不用原来的存储,而是转化为用它们的 01 串来存储不久是能减小了空间占用了吗。(什么 01 串不是比原来的字符还多了吗?怎么降低?)大家应该知道的。计算机中我们存储一个 int 型数据的时候一般式占用了 2^32-1 个 01 位,由于计算机中全部的数据都是最后转化为二进制位去存储的。所以。想想我们的编码不就是仅仅含有 0 和 1 嘛,因此我们就直接将编码依照计算机的存储规则用位的方法写入进去就能实现压缩了。
比方:
1这个数字。用整数写进计算机硬盘去存储,占用了 2^32-1 个二进制位
而假设用它的哈弗曼编码去存储,仅仅有110 三个二进制位。
效果显而易见。