线段树
线段树
目录
零、前言
一、引例
1、区间最值
2、区间求和
二、线段树的基本概念
1、二叉搜索树
2、数据域
3、指针表示
4、数组表示
三、线段树的基本操作
1、构造
2、更新
3、询问
四、线段树的经典案例
1、区间最值
2、区间求和
3、区间染色
4、矩形面积并
5、区间K大数
五、线段树的常用技巧
1、离散化
2、lazy-tag
3、子树收缩
六、线段树的多维推广
1、二维线段树 - 矩形树
2、三维线段树 - 空间树
七、线段树相关题集整理
零、前言
最近工作比较忙,好久没更新了,只能在过年期间抽时间写上一篇,美其名曰贺岁版,很享受写文章的过程,不想就这么断了连载,但是接下来可能会更忙,虽然很想一直坚持下去,但是臣妾做不到啊……
一、引例
1、区间最值
【例题1】给定一个n(n <= 100000)个元素的数组A,有m(m <= 100000)个操作,共两种操作:
1、Q a b 询问:表示询问区间[a, b]的最大值;
2、C a c 更新:表示将第a个元素变成c;
静态的区间最值可以利用RMQ来解决,但是RMQ的ST算法是在元素值给定的情况下进行的预处理,然后在O(1)时间内进行询问,这里第二种操作需要实时修改某个元素的值,所以无法进行预处理。
2、区间求和
【例题2】给定一个n(n <= 100000)个元素的数组A,有m(m <= 100000)个操作,共两种操作:
1、Q a b 询问:表示询问区间[a, b]的元素和;
2、A a b c 更新:表示将区间[a, b]的每个元素加上一个值c;
先来看朴素算法,两个操作都用遍历来完成,单次时间复杂度在最坏情况下都是O(n)的,所以m次操作下来总的时间复杂度就是O(nm)了,复杂度太高。
再来看看树状数组,对于第一类操作,树状数组可以在log(n)的时间内出解;然而第二类操作,还是需要遍历每个元素执行add操作,复杂度为nlog(n),所以也不可行。这个问题同样也需要利用区间拆分的思想。
线段树就是利用了区间拆分的思想,完美解决了上述问题。
二、线段树的基本概念
1、二叉搜索树
线段树是一种二叉搜索树,即每个结点最多有两棵子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。线段树的每个结点存储了一个区间(线段),故而得名。

图二-1-1
如图二-1-1所示,表示的是一个[1, 6]的区间的线段树结构,每个结点存储一个区间(注意这里的存储区间并不是指存储这个区间里面所有的元素,而是只需要存储区间的左右端点即可),所有叶子结点表示的是单位区间(即左右端点相等的区间),所有非叶子结点(内部结点)都有左右两棵子树,对于所有非叶子结点,它表示的区间为[l, r],那么令mid为(l + r)/2的下整,则它的左儿子表示的区间为[l, mid],右儿子表示的区间为[mid+1, r]。基于这个特性,这种二叉树的内部结点,一定有两个儿子结点,不会存在有左儿子但是没有右儿子的情况。
基于这种结构,叶子结点保存一个对应原始数组下标的值,由于树是一个递归结构,两个子结点的区间并正好是父结点的区间,可以通过自底向上的计算在每个结点都计算出当前区间的最大值。
需要注意的是,基于线段树的二分性质,所以它是一棵平衡树,树的高度为log(n)。
2、数据域
了解线段树的基本结构以后,看看每个结点的数据域,即需要存储哪些信息。
首先,既然线段树的每个结点表示的是一个区间,那么必须知道这个结点管辖的是哪个区间,所以其中最重要的数据域就是区间左右端点[l, r]。然而有时候为了节省全局空间,往往不会将区间端点存储在结点中,而是通过递归的传参进行传递,实时获取。
再者,以区间最大值为例,每个结点除了需要知道所管辖的区间范围[l, r]以外,还需要存储一个当前区间内的最大值max。

图二-2-1
以数组A[1:6] = [1 7 2 5 6 3]为例,建立如图二-2-1的线段树,叶子结点的max域为数组对应下标的元素值,非叶子结点的max域则通过自底向上的计算由两个儿子结点的max域比较得出。这是一棵初始的线段树,接下来讨论下线段树的询问和更新操作。
在询问某个区间的最大值时,我们一定可以将这个区间拆分成log(n)个子区间,并且这些子区间一定都能在线段树的结点上找到(这一点下文会着重讲解),然后只要比较这些结点的max域,就能得出原区间的最大值了,因为子区间数量为log(n),所以时间复杂度是O( log(n) )。
更新数组某个元素的值时我们首先修改对应的叶子结点的max域,然后修改它的父结点的max域,以及祖先结点的max域,换言之,修改的只是线段树的叶子结点到根结点的某一条路径上的max域,又因为树高是log(n),所以这一步操作的时间复杂度也是log(n)的。
3、指针表示
接下来讨论一下结点的表示法,每个结点可以看成是一个结构体指针,由数据域和指针域组成,其中指针域有两个,分别为左儿子指针和右儿子指针,分别指向左右子树;数据域存储对应数据,根据情况而定(如果是求区间最值,就存最值max;求区间和就存和sum),这样就可以利用指针从根结点进行深度优先遍历了。
以下是简单的线段树结点的C++结构体:
struct treeNode {
Data data; // 数据域
treeNode *lson, *rson; // 指针域
}*root;
Data data; // 数据域
treeNode *lson, *rson; // 指针域
}*root;
4、数组表示
实际计算过程中,还有一种更加方便的表示方法,就是基于数组的静态表示法,需要一个全局的结构体数组,每个结点对应数组中的一个元素,利用下标索引。
例如,假设某个结点在数组中下标为p,那么它的左儿子结点的下标就是2*p,右儿子结点的下标就是2*p+1(类似于一般数据结构书上说的堆在数组中的编号方式),这样可以将所有的线段树结点存储在相对连续的空间内。之所以说是相对连续的空间,是因为有些下标可能永远用不到。
还是以长度为6的数组为例,如图二-4-1所示,红色数字表示结点对应的数组下标,由于树的结构和编号方式,导致数组的第10、11位置空缺。

图二-4-1
这种存储方式可以不用存子结点指针,取而代之的是当前结点的数组下标索引,以下是数组存储方式的线段树结点的C++结构体:
struct treeNode {
Data data; // 数据域
int pid; // 数组下标索引
int lson() { return pid << 1; }
int rson() { return pid<<1|1; } // 利用位运算加速获取子结点编号
}nodes[ MAXNODES ];
Data data; // 数据域
int pid; // 数组下标索引
int lson() { return pid << 1; }
int rson() { return pid<<1|1; } // 利用位运算加速获取子结点编号
}nodes[ MAXNODES ];
接下来我们关心的就是MAXNODES的取值了,由于线段树是一种二叉树,所以当区间长度为2的幂时,它正好是一棵满二叉树,数组存储的利用率达到最高(即100%),根据等比数列求和可以得出,满二叉树的结点个数为2*n-1,其中n为区间长度(由于C++中数组长度从0计数,编号从1开始,所以MAXNODES要取2*n)。那么是否对于所有的区间长度n都满足这个公式呢?答案是否定的,当区间长度为6时,最大的结点编号为13,而公式算出来的是12(2*6)。
那么 MAXNODES 取多少合适呢?
为了保险起见,我们可以先找到比n大的最小的二次幂,然后再套用等比数列求和公式,这样就万无一失了。举个例子,当区间长度为6时,MAXNODES = 2 * 8;当区间长度为1000,则MAXNODES = 2 * 1024;当区间长度为10000,MAXNODES = 2 * 16384。至于为什么可以这样,明眼人一看便知。
线段树的基本操作包括构造、更新、询问,都是深度优先搜索的过程。
1、构造
线段树的构造是一个二分递归的过程,封装好了之后代码非常简洁,总体思路就是从区间[1, n]开始拆分,拆分方式为二分的形式,将左半区间分配给左子树,右半区间分配给右子树,继续递归构造左右子树。
线段树的构造是一个二分递归的过程,封装好了之后代码非常简洁,总体思路就是从区间[1, n]开始拆分,拆分方式为二分的形式,将左半区间分配给左子树,右半区间分配给右子树,继续递归构造左右子树。
当区间拆分到单位区间时(即遍历到了线段树的叶子结点),则执行回溯。回溯时对于任何一个非叶子结点需要根据两棵子树的情况进行统计,计算当前结点的数据域,详见注释4。
void segtree_build(int p, int l, int r) {
nodes[p].reset(p, l, r); // 注释1
if (l < r) {
int mid = (l + r) >> 1;
segtree_build(p<<1, l, mid); // 注释2
segtree_build(p<<1|1, mid+1, r); // 注释3
nodes[p].updateFromSon(); // 注释4
}
}
nodes[p].reset(p, l, r); // 注释1
if (l < r) {
int mid = (l + r) >> 1;
segtree_build(p<<1, l, mid); // 注释2
segtree_build(p<<1|1, mid+1, r); // 注释3
nodes[p].updateFromSon(); // 注释4
}
}
注释1:初始化第p个结点的数据域,根据实际情况实现reset函数
注释2:递归构造左子树
注释3:递归构造右子树
注释4:回溯,利用左右子树的信息来更新当前结点,updateFromSon这个函数的实现需要根据实际情况进行求解,在第四节会详细讨论
构造线段树的调用如下:
segtree_build(1, 1, n);
2、更新
线段树的更新是指更新数组在[x, y]区间的值,具体更新这件事情是做了什么要根据具体情况而定,可以是将[x, y]区间的值都变成val(覆盖),也可以是将[x, y]区间的值都加上val(累加)。
更新过程采用二分,将[1, n]区间不断拆分成一个个子区间[l, r],当更新区间[x, y]完全覆盖被拆分的区间[l, r]时,则更新管辖[l, r]区间的结点的数据域,详见注释2和注释3。
void segtree_insert(int p, int l, int r, int x, int y, ValueType val) {
if( !is_intersect(l, r, x, y) ) { // 注释1
return ;
}
if( is_contain(l, r, x, y) ) { // 注释2
nodes[p].updateByValue(val); // 注释3
return ;
}
nodes[p].giveLazyToSon(); // 注释4
int mid = (l + r) >> 1;
segtree_insert(p<<1, l, mid, x, y, val); // 注释5
segtree_insert(p<<1|1, mid+1, r, x, y, val); // 注释6
nodes[p].updateFromSon(); // 注释7
}
if( !is_intersect(l, r, x, y) ) { // 注释1
return ;
}
if( is_contain(l, r, x, y) ) { // 注释2
nodes[p].updateByValue(val); // 注释3
return ;
}
nodes[p].giveLazyToSon(); // 注释4
int mid = (l + r) >> 1;
segtree_insert(p<<1, l, mid, x, y, val); // 注释5
segtree_insert(p<<1|1, mid+1, r, x, y, val); // 注释6
nodes[p].updateFromSon(); // 注释7
}
注释1:区间[l, r]和区间[x, y]无交集,直接返回
注释2:区间[x, y]完全覆盖[l, r]
注释3:更新第p个结点的数据域,updateByValue这个函数的实现需要根据具体情况而定,会在第四节进行详细讨论
注释4:这里先卖个关子,参见第五节的lazy-tag
注释5:递归更新左子树
注释6:递归更新右子树
注释7:回溯,利用左右子树的信息来更新当前结点
更新区间[x, y]的值为val的调用如下:
segtree_insert(1, 1, n, x, y, val);
3、询问
线段树的询问和更新类似,大部分代码都是一样的,只有红色部分是不同的,同样是将大区间[1, n]拆分成一个个小区间[l, r],这里需要存储一个询问得到的结果ans,当询问区间[x, y]完全覆盖被拆分的区间[l, r]时,则用管辖[l, r]区间的结点的数据域来更新ans,详见注释1的mergeQuery接口
。
void segtree_query (int p, int l, int r, int x, int y, treeNode& ans) {
if( !is_intersect(l, r, x, y) ) {
return ;
}
if( is_contain(l, r, x, y) ) {
ans.mergeQuery(p); // 注释1
return;
}
nodes[p].giveLazyToSon();
int mid = (l + r) >> 1;
segtree_query(p<<1, l, mid, x, y, ans);
segtree_query(p<<1|1, mid+1, r, x, y, ans);
nodes[p].updateFromSon(); // 注释2
}
if( !is_intersect(l, r, x, y) ) {
return ;
}
if( is_contain(l, r, x, y) ) {
ans.mergeQuery(p); // 注释1
return;
}
nodes[p].giveLazyToSon();
int mid = (l + r) >> 1;
segtree_query(p<<1, l, mid, x, y, ans);
segtree_query(p<<1|1, mid+1, r, x, y, ans);
nodes[p].updateFromSon(); // 注释2
}
注释1:更新当前解ans,会在第四节进行详细讨论
注释2:和更新一样的代码,不再累述
四、线段树的经典案例
线段树的用法千奇百怪,接下来介绍几个线段树的经典案例,加深对线段树的理解。
1、区间最值
区间最值是最常见的线段树问题,引例中已经提到。接下来从几个方面来讨论下区间最值是如何运作的。
数据域:
int pid; // 数组索引
int l, r; // 结点区间(一般不需要存储)
ValyeType max; // 区间最大值
初始化:
void treeNode::reset(int p, int l, int r) {
pid = p;
max = srcArray[l]; // 初始化只对叶子结点有效
}
单点更新:
void treeNode::updateByValue(ValyeType val) {
max = val;
}
合并结点:
void treeNode::mergeQuery(int p) {
max = getmax( max, nodes[p].max );
}
回溯统计:
void treeNode::updateFromSon() {
max = nodes[ lson() ].max;
mergeQuery( rson() );
}
结合上一节线段树的基本操作,在构造线段树的时候,对每个结点执行了一次初始化,初始化同时也是单点更新的过程,然后在回溯的时候统计,统计实质上是合并左右结点的过程,合并结点做的事情就是更新最大值;询问就是将给定区间拆成一个个能够在线段树结点上找到的区间,然后合并这些结点的过程,合并的结果ans一般通过引用进行传参,或者作为全局变量,不过尽量避免使用全局变量
。
2、区间求和
区间求和问题一般比区间最值稍稍复杂一点,因为涉及到区间更新和区间询问,如果更新和询问都只遍历到询问(更新)区间完全覆盖结点区间的话,会导致计算遗留,举个例子来说明。
用一个数据域sum来记录线段树结点区间上所有元素的和,初始化所有结点的sum值都为0,然后在区间[1, 4]上给每个元素加上4,如图四-2-1所示:

图四-2-1
图中[1, 4]区间完全覆盖[1, 3]和[4, 4]两个子区间,然后分别将值累加到对应结点的数据域sum上,再通过回溯统计sum和,最后得到[1, 6]区间的sum和为16,看上去貌似天衣无缝,但是实际上操作一多就能看出这样做是有缺陷的。例如当我们要询问[3, 4]区间的元素和时,在线段树结点上得到被完全覆盖的两个子区间[3, 3]和[4, 4],累加区间和为0 + 4 = 4,如图四-2-2所示。

图四-2-2
这是因为在进行区间更新的时候,由于[1, 4]区间完全覆盖[1, 3]区间,所以我们并没有继续往下遍历,而是直接在[1, 3]这个结点进行sum值的计算,计算完直接回溯。等到下一次访问[3, 3]的时候,它并不知道之前在3号位置上其实是有一个累加值4的,但是如果每次更新都更新到叶子结点,就会使得更新的复杂度变成O(n),违背了使用线段树的初衷,所以这里需要引入一个lazy-tag的概念。
所谓lazy-tag,就是在某个结点打上一个“懒惰标记”,每次更新的时候只要更新区间完全覆盖结点区间,就在这个结点打上一个lazy标记,这个标记的值就是更新的值,表示这个区间上每个元素都有一个待累加值lazy,然后计算这个结点的sum,回溯统计sum。
当下次访问到有lazy标记的结点时,如果还需要往下访问它的子结点,则将它的lazy标记传递给两个子结点,自己的lazy标记置空。
这就是为什么在之前在讲线段树的更新和询问的时候有一个函数叫giveLazyToSon了。接下来看看一些函数的实现。
数据域:
int pid; // 数组索引
int len; // 结点区间长度
ValyeType sum; // 区间元素和
ValyeType lazy; // lazy tag
初始化:
void treeNode::reset(int p, int l, int r) {
pid = p;
len = r - l + 1;
sum = lazy = 0;
}
单点更新:
void treeNode::updateByValue(ValyeType val) {
lazy += val
;
sum += val * len
;
}
lazy标记继承:
void treeNode::giveLazyToSon() {
if( lazy ) {
nodes[ lson() ].updateByValue(lazy);
nodes[ rson() ].updateByValue(lazy);
lazy = 0;
}
}
合并结点:
void treeNode::mergeQuery(int p) {
sum += nodes[p].sum;
}
回溯统计:
void treeNode::updateFromSon() {
sum = nodes[ lson() ].sum;
mergeQuery( rson() );
}
对比区间最值,区间求和的几个函数的实现主旨是一致的,因为引入了lazy-tag,所以需要多实现一个函数用于lazy标记的继承,在进行区间求和的时候还需要记录一个区间的长度len,用于更新的时候计算累加的sum值。
3、区间染色
【例题3】给定一个长度为n(n <= 100000)的木板,支持两种操作:
1、P a b c 将[a, b]区间段染色成c;
2、Q a b 询问[a, b]区间内有多少种颜色;
保证染色的颜色数少于30种。
对比区间求和,不同点在于区间求和的更新是对区间和进行累加;而这类染色问题则是对区间的值进行替换(或者叫覆盖),有一个比较特殊的条件是颜色数目小于30。
我们是不是要将30种颜色的有无与否都存在线段树的结点上呢?答案是肯定的,但是这样一来每个结点都要存储30个bool值,空间太浪费,而且在计算合并操作的时候有一步30个元素的遍历,大大降低效率。然而30个bool值正好可以压缩在一个int32中,利用二进制压缩可以用一个32位的整型完美的存储30种颜色的有无情况。
因为任何一个整数都可以分解成二进制整数,二进制整数的每一位要么是0,要么是1。二进制整数的第i位是1表示存在第i种颜色;反之不存在。
数据域需要存一个颜色种类的位或和colorBit,一个颜色的lazy标记表示这个结点被完全染成了lazy,基本操作的几个函数和区间求和非常像,这里就不出示代码了。
和区间求和不同的是回溯统计的时候,对于两个子结点的数据域不再是加和,而是位或和。
4、矩形面积并
【例题4】给定n(n <= 100000)个平行于XY轴的矩形,求它们的面积并。如图四-4-1所示。

图四-4-1
这类二维的问题同样也可以用线段树求解,核心思想是降维,将某一维套用线段树,另外一维则用来枚举。具体过程如下:
第一步:将所有矩形拆成两条垂直于x轴的线段,平行x轴的边可以舍去,如图四-4-2所示。

图四-4-2
第二步:定义矩形的两条垂直于x轴的边中x坐标较小的为入边,x坐标较大的为出边,入边权值为+1,出边权值为-1,并将所有的线段按照x坐标递增排序,第i条线段的x坐标记为X[i],如图四-4-3所示。

图四-4-3
第三步:将所有矩形端点的y坐标进行重映射(也可以叫离散化),原因是坐标有可能很大而且不一定是整数,将原坐标映射成小范围的整数可以作为数组下标,更方便计算,映射可以将所有y坐标进行排序去重,然后二分查找确定映射后的值,离散化的具体步骤下文会详细讲解。如图四-4-4所示,蓝色数字表示的是离散后的坐标,即1、2、3、4分别对应原先的5、10、23、25(需支持正查和反查)。假设离散后的y方向的坐标个数为m,则y方向被分割成m-1个独立单元,下文称这些独立单元为“单位线段”,分别记为<1-2>、<2-3>、<3-4>。

图四-4-4
第四步:以x坐标递增的方式枚举每条垂直线段,y方向用一个长度为m-1的数组来维护“单位线段”的权值,如图四-4-5所示,展示了每条线段按x递增方式插入之后每个“单位线段”的权值。
当枚举到第i条线段时,检查所有“单位线段”的权值,所有权值大于零的“单位线段”的实际长度之和(离散化前的长度)被称为“合法长度”,记为L,那么(X[i] - X[i-1]) * L,就是第i条线段和第i-1条线段之间的矩形面积和,计算完第i条垂直线段后将它插入,所谓"插入"就是利用该线段的权值更新该线段对应的“单位线段”的权值和(这里的更新就是累加)。
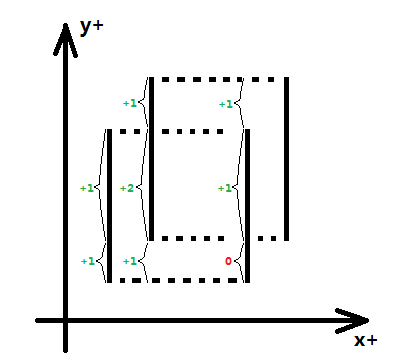
图四-4-5
如图四-4-6所示:红色、黄色、蓝色三个矩形分别是3对相邻线段间的矩形面积和,其中红色部分的y方向由<1-2>、<2-3>两个“单位线段”组成,黄色部分的y方向由<1-2>、<2-3>、<3-4>三个“单位线段”组成,蓝色部分的y方向由<2-3>、<3-4>两个“单位线段”组成。特殊的,在计算蓝色部分的时候,<1-2>部分的权值由于第3条线段的插入(第3条线段权值为-1)而变为零,所以不能计入“合法长度”。
以上所有相邻线段之间的面积和就是最后要求的矩形面积并。

图四-4-6
那么这里带来几个问题:
1、是否任意相邻两条垂直x轴的线段之间组成的封闭图形都是矩形呢?答案是否定的,如图四-4-7所示,其中绿色部分为四个矩形的面积并中的某块有效部分,它们同处于两条相邻线段之间,但是中间有空隙,所以它并不是一个完整的矩形。
2、每次枚举一条垂直线段的时候,需要检查所有“单位线段”的权值,如果用数组维护权值,那么这一步检查操作是O(m)的,所以总的时间复杂度为O(nm),其中n表示垂直线段的个数,复杂度太大需要优化。

图四-4-7
优化自然就是用线段树了,之前提到了降维的思想,x方向我们继续采用枚举,而y方向的“单位线段”则可以采用线段树来维护,和一般问题一样,首先讨论数据域。
数据域:
int pid; // 数组索引
int l, r; // 结点代表的“单位线段”区间[l, r] (注意,l和r均为离散后的下标)
int cover; // [l, r]区间被完全覆盖的次数
int len; // 该结点表示的区间内的合法长度
注意,这次的线段树和之前的线段树稍微有点区别,就是叶子结点的区间端点不再相等,而是相差1,即l+1 == r。因为一个点对于计算面积来说是没有意义的。
算法采用深度优先搜索的后序遍历,记插入线段为[a, b, v],其中[a, b]为线段的两个端点,是离散化后的坐标;v是+1或-1,代表是入边还是出边,每次插入操作二分枚举区间,当线段树的结点代表的区间被插入区间完全覆盖时,将权值v累加到结点的cover域上。由于是后续遍历,在子树全部遍历完毕后需要进行统计。插入过程修改cover,同时更新len。
回溯统计过程对cover域分情况讨论:
当cover > 0时,表示该结点代表的区间至少有一条入边没有被出边抵消,换言之,这块区间都应该在“合法长度”之内,则 len = Y[r] - Y[l](Y[i]代表离散前第i大的点的y坐标);更加通俗的理解是至少存在一个矩形的入边被扫描到了,而出边还未被扫描到,所以这块面积需要被计算进来。
当cover等于0时,如果该区间是一个单位区间(即上文所说的“单位线段”,l+1 == r,也是线段树的叶子结点),则 len = 0;否则,len需要由左子树和右子树的计算结果得出,又因为是后序遍历,所以左右子树的len都已经计算完毕,从而不需要再进行递归求解,直接将左右儿子的len加和就是答案,即len = lson.len + rson.len。
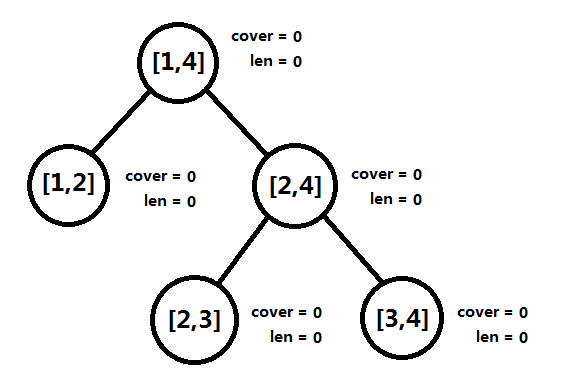
图四-4-8
图四-4-8所示为上述例子的初始线段树,其中根结点管辖的区间为[1, 4],代表"单位线段”的两个端点。对于线段树上任何一棵子树而言,根结点管辖区间为[l, r],并且mid = (l + r) / 2,那么如果它不是叶子结点,则它的左子树管辖的区间就是[l, mid],右子树管辖的区间就是[mid, r]。叶子结点管辖区间的左右端点之差为1(和之前的线段树的区间分配方式稍有不同)。
这样就可以利用二分,在O(n)的时间内递归构造初始的线段树。

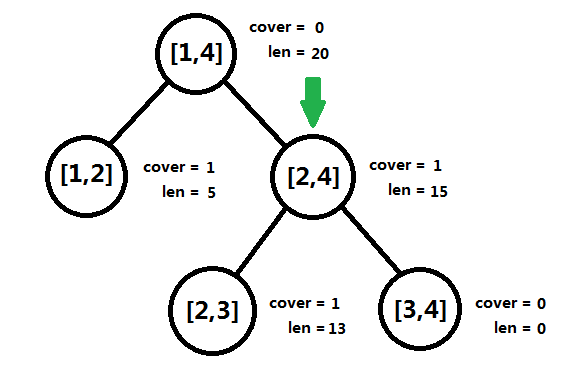
图四-4-9
图四-4-9所示为插入第一条垂直线段[1, 3, 1](插入区间[1, 3],权值为1)后的情况,插入过程类似建树过程,二分递归执行插入操作,当插入区间完全覆盖线段树结点区间时,将权值累加到对应结点(图中绿色箭头指向的结点)的cover域上;否则,继续递归左右子树。然后进行自底向上的统计,统计的是len的值。
[2, 4]这个结点的cover域为0,所以它的len等于两棵子树的len之和,[1, 4]亦然。
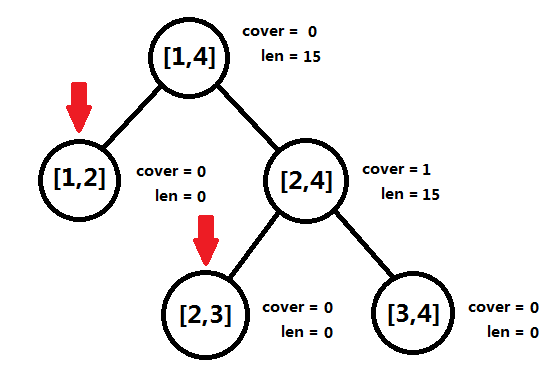
图四-4-10
图四-4-10所示为插入第二条垂直线段[2, 4, 1](插入区间[2, 4],权值为1)后的情况,只需要修改一个结点(图中绿色箭头指向的结点)的cover域,该结点的两棵子树不需要再进行递归计算,回溯的时候,计算根结点len值时,由于根结点的cover域为0,所以它的len等于左右子树的len之和。
图四-4-11
图四-4-11所示为插入第三条垂直线段[1, 3, -1](插入区间[1, 3],权值为-1)后的情况,直观的看,现在Y方向只有[2, 4]一条线段了,所以根结点的len就是Y[4] - Y[2] = 15。
讲完插入,就要谈谈询问。在每次插入之前,需要询问之前插入的线段中,在y方向的“合法长度”L,根据线段树结点的定义,y方向“合法长度”总和其实就是根结点的len,所以这一步询问操作其实是O(1)的,在插入过程中已经实时计算出来,再加上插入的O(log n)的时间复杂度,已经完美解决了上述复杂度太大的问题了。
5、区间K大数
【例题5】给定n(n <= 100000)个数的数组,然后m(m <= 100000)条询问,询问格式如下:
1、l r k 询问[l, r]的第K大的数的值

图四-5-1
从图中可以看出,线段树的任何一个结点存储了对应区间的数,并且进行有序排列,所以根结点存储的一定是一个长度为数组总长的有序数组,叶子结点存储的递增序列为原数组元素。
每次询问,我们将给定区间拆分成一个个线段树上的子区间,然后二分枚举答案T,再利用二分查找统计这些子区间中大于等于T的数的个数,从而确定T是否是第K大的。
对于区间K大数的问题,还有很多数据结构都能解决,这里仅作简单介绍。
五、线段树的常用技巧
1、离散化
在讲解矩形面积并的时候曾经提了一下离散化,现在再详细的说明一下,所谓离散化就是将无限的个体映射到有限的个体中,从而提高算法效率。
举个简单的例子,一个实数数组,我想很快的得到某个数在整个数组里是第几大的,并且询问数很多,不允许每次都遍历数组进行比较。
那么,最直观的想法就是对原数组先进行一个排序,询问的时候只需要通过二分查找就能在O( log(n) )的时间内得出这个数是第几大的了,离散化就是做了这一步映射。
对于一个数组[1.6, 7.8, 5.5, 11.1111, 99999, 5.5],离散化就是将原来的实数映射成整数(下标),如图五-1-1所示:
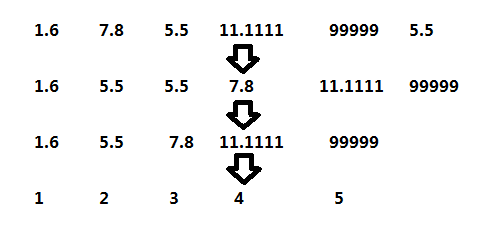
图五-1-1
这样就可以将原来的实数保存在一个有序数组中,询问第K大的是什么称为正查,可以利用下标索引在O(1)的时间内得到答案;询问某个数是第几大的称为反查,可以利用二分查找或者Hash得到答案,复杂度取决于具体算法,一般为O(log(n))。
2、lazy-tag
这个标记一般用于处理线段树的区间更新。
线段树在进行区间更新的时候,为了提高更新的效率,所以每次更新只更新到更新区间完全覆盖线段树结点区间为止,这样就会导致被更新结点的子孙结点的区间得不到需要更新的信息,所以在被更新结点上打上一个标记,称为lazy-tag,等到下次访问这个结点的子结点时再将这个标记传递给子结点,所以也可以叫延迟标记。
3、子树收缩
子树收缩是子树继承的逆过程,子树继承是为了两棵子树获得父结点的信息;而子树收缩则是在回溯的时候,如果两棵子树拥有相同数据的时候在将数据传递给父结点,子树的数据清空,这样下次在访问的时候就可以减少访问的结点数。
六、线段树的多维推广
1、二维线段树 - 矩形树
线段树是处理区间问题的,
二维线段树就是处理平面问题的了,曾经写过一篇二维线段树的文章,就不贴过来了,直接给出传送门:
二维线段树。
2、三维线段树 - 空间树
线段树-二叉树,二维线段树-四叉树,三维线段树自然就是八叉树了,分割的是空间,一般用于三维计算几何,当然也不一定用在实质的空间内的问题。
比如需要找出身高、体重、年龄在一定范围内并且颜值最高的女子,就可以用三维线段树(三维空间最值问题),嘿嘿嘿!!!
七、线段树相关题集整理
区间最值
I Hate It ★☆☆☆☆ 最值-单点更新,批量查询
Sticks Problem ★★☆☆☆ 最值-二分枚举 + 批量查询
Balanced Lineup ★★☆☆☆ 最值-批量查询
Frequent values ★★☆☆☆ 最值-批量查询
Billboard ★★☆☆☆ 最值-单点更新、批量查询
Huge Mission ★★☆☆☆ 最值-区间更新,单点询问
Gcd & Lcm game ★★★☆☆ 利用LCM和GCD的素拆表示
Another LIS ★★★★☆ 最值(线段树)+ 树状数组
WorstWeather Ever ★★★★☆ 很好的逻辑题,线段树维护最值
Special Subsequence ★★★★☆ 动态规划 + 区间最值
Minimizing maximizer ★★★★☆ 动态规划 + 区间最值
区间求和
A Simple Problem with Integers ★☆☆☆☆ 求和-区间更新,区间求和
Thermal Death of the Universe ★☆☆☆☆ 求和-区间更新,区间求和
Buy Tickets ★★☆☆☆ 求和-单点更新,区间求和
Turing Tree ★★★☆☆ 求和-离线区间求和
Help with Intervals ★★★☆☆ 求和-异或的应用
Sequence operation ★★★☆☆ 求和-异或的应用
Coder ★★★☆☆ 求和-线段树 + 树状数组
区间染色
Just a Hook ★☆☆☆☆ 染色-批量染色,单次统计
Mayor's posters ★☆☆☆☆ 染色-批量染色,单次统计(离散化)
Count Color ★★☆☆☆ 染色-批量染色,批量查询
A Corrupt Mayor's Performance Art ★★☆☆☆ 染色-批量染色,批量查询
Horizontally Visible Segments ★★★☆☆ 染色-批量染色,子树收缩
Can you answer these queries? ★★★☆☆ 染色-批量染色,子树收缩
Color the Ball ★★★☆☆ 染色-最长连续区间
LCIS ★★★☆☆ 染色-最长连续递增子序列
Memory Control ★★★★☆ 染色-内存分配
Man Down ★★★☆☆ 动态规划 + 区间染色
矩形问题
Atlantis ★☆☆☆☆ 离散化 + 矩形面积并
City Horizon ★☆☆☆☆ 矩形面积并
Paint the Wall ★☆☆☆☆ 矩形面积并
Posters ★★☆☆☆ 中空矩形面积并
Covered Area ★★☆☆☆ 矩形面积并
Picture ★★★☆☆ 矩形周长
Colourful Rectangle ★★★☆☆ 多色矩形面积并
End of Windless Days ★★★☆☆ 投影三角换算 + 矩形面积并
区间K大数
K-th Number ★★★☆☆ 区间K大数
Kth number ★★★☆☆ 区间K小数
Feed the dogs ★★★☆☆ 区间K大数
二维线段树
Luck and Love ★★☆☆☆ 二维最值
Mosaic ★★☆☆☆ 二维最值
Matrix Searching ★★☆☆☆ 二维最值
人一我百!人十我万!永不放弃~~~怀着自信的心,去追逐梦想。