谈flink实时流处理
背景:
数据量激增传统的时代,不同的业务场景都有大量的业务数据产生,对于这些不断产生的数据应该如何进行有效地处理,成为当下大多数公司所面临的问题。
但随着数据的不断增长,新技术的不断发展,人们逐渐意识到对实时数据处理的重要性,企业需要能够同时支持高吞吐、低延迟、高性能的流处理技术来处理日益增长的数据。
相对于传统的数据处理模式,流式数据处理则有着更高的处理效率和成本控制。Apache Flink就是近年来在开源社区发展不断发展的能够支持同时支持高吞吐、低延迟、高性能分布式处理框架。
flink:
Flink是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。可以部署在各种集群环境,对各种大小规模的数据进行快速计算。
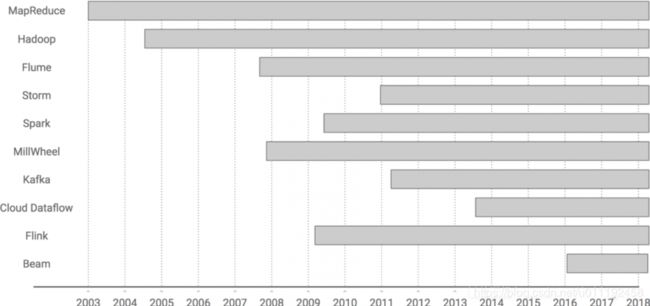
flink发展史
Flink 诞生于2009年,起初诞生于德国柏林大学,最开始设计是为了解决批处理问题的。于2014年孵化并捐给Apache,2016年开始在阿里大规模应用,从而驶入快车道。
这一切都源于 MillWheel: Fault-Tolerant Stream Processing at Internet Scale,Google发表的一篇论文,讲述了如何在大规模系统中实现高吞吐/低延迟/有状态实时流处理。而Flink也是受到该论文的影响,采用了 Dataflow/Beam 编程模型 。
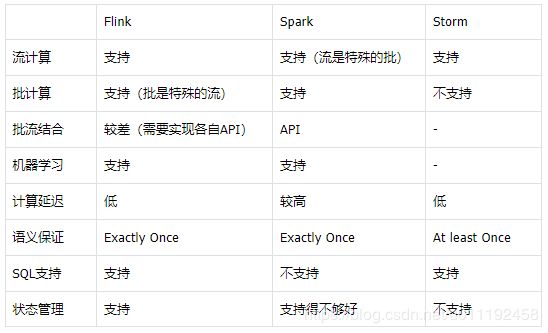
Flink VS Spark VS Storm
-
流计算方面
当前的 Flink 就是为了支持流计算而设计的。而 Spark 的流计算是特殊的批,是由连续的微批组成的流式计算。
-
批计算方面
Flink 的批处理是特殊的流,而 Spark 本身的计算模型就是批处理模型。Storm 则不支持批处理。
-
批流融合方面
Flink 的批处理API和流处理API是两套API,导致一个方法为了同时支持批处理和流处理需要实现两次,不过 Flink 的后续版本一直在促进批流融合。
Spark 批流结合则支持的很好,通过 DataFrame 实现的方法既可以支持批处理又可以支持流处理。
-
机器学习方面
Spark 和 Flink 都提供了丰富的机器学习相关方法库。Spark 最近几年的重心都放在了支持机器学习上,并且 Spark 对于 Python以及R都支持得很好,让一些非Java体系的数据开发人员也能很快入手Spark。
Flink 对 Python 的支持、优化也在进行中,并且有阿里主导的 Alink - 全球首个批流一体机器学习平台,也在国内外十分受欢迎。
-
计算延迟方面
因为 Spark 是微批处理,因此处理延迟较 Flink 和 Storm 比较较大。
-
一致性语义方面
Flink 和 Storm 都实现了 Exactly Once 语义,而 Storm 如果不借助外部数据库仅支持 At Least Once 语义。
-
状态管理方面
Spark 在有状态实时流处理方面支持地不够好,仅支持有限的方法,例如updateStateByKey 以及mapWithState。而 Flink 支持非常丰富的状态管理方法,这个我们后面也会说到。
Flink适应应用场景
我们会在什么时候使用 Flink 呢?或者说哪些场景使用 Flink 能更好地完成呢。
如果按照传统的方案会是什么架构呢?

首先业务已经由相关人员实时推送至Kafka中,我们会将数据通过ETL工具实时写入数据仓库中,通过数据仓库完成即席查询实时聚合。
这种方案可能因大量数据入库导致一部分数据延迟,那么我们还可以通过 Spark 进行数据的预聚合后写入数仓中,这样能减少写入以及查询的成本。
但是这个方案还存在延迟的问题:
1. 整个方案即使优化过还存在较大的延迟,数据写入/数据查询 ;
2. 整个方案有太多DB交互过程 ;
那么如果我们用 Flink 会怎么实现呢?
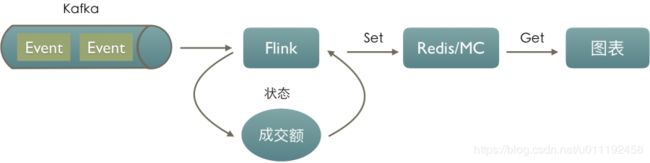
我们会将成交额当作“状态”维护在Flink中,定期更新Redis或者MC,这样我们的图表可以直接从Reids或者MC中直接读取成交额信息,这样可以减少很多DB交互过程,并且Redis或者MC的一次Set或者Get操作也是毫秒级别的。
Flink有哪些特有的功能呢
流计算系统中经常需要与外部系统进行交互,我们通常的做法如向数据库发送用户a的查询请求,然后等待结果返回,在结果返回之前,我们的程序无法继续发送用户b的查询请求。这是一种同步访问方式,如下图所示。
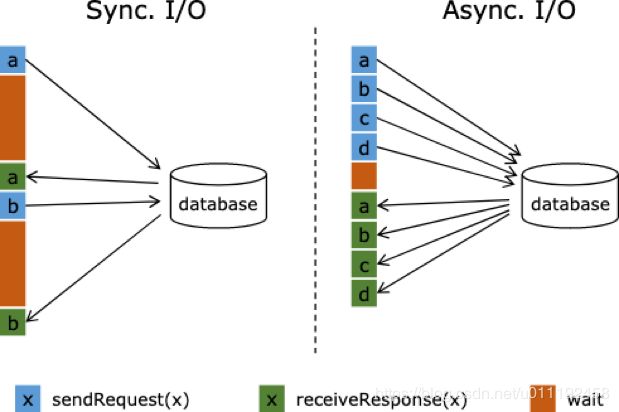
图中棕色的长条表示等待时间,可以发现网络交互等待时间极大地阻碍了吞吐和延迟。为了解决同步访问的问题,异步模式可以并发地处理多个请求和回复。
也就是说,你可以连续地向数据库发送用户a、b、c等的请求,与此同时,哪个请求的回复先返回了就处理哪个回复,从而连续的请求之间不需要阻塞等待,如上图右边所示,这样能节省很多网络交互等待时间。
CEP处理
CEP全称为(Complex Event Processing),Flink CEP库允许你在流上定义一系列的模式(pattern),最终使得你可以方便的抽取自己需要的重要的事件出来。
CEP常用于异常检测/行为分析以及实时风控,以下是一个应用简单的模式匹配实现的用户异常登陆检测的例子。
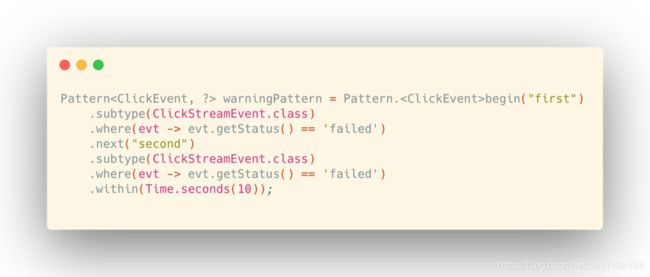
匹配10秒内连续两次登陆失败的行为 。
多样的窗口
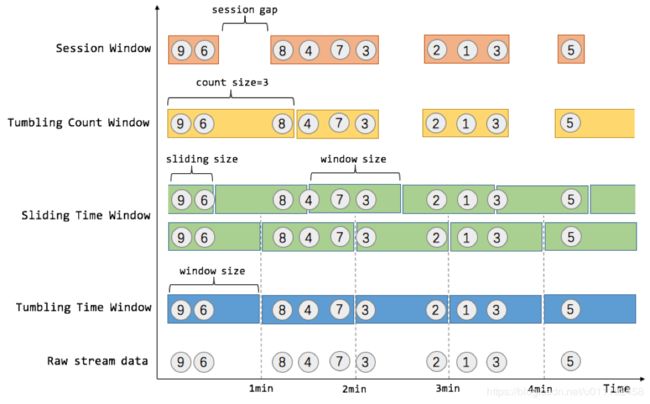
Flink支持多种多样的窗口来实现各种复杂的统计和计算。常用有以下几种:
1、Tumbling Windows(滚动窗口)
各窗口间不重合,常用于实时定时统计,例如服务每秒访问量 。
2、Sliding Windows(滑动窗口)
各窗口间可以重合,常用于判断事件是否连续,例如每1分钟统计最近5分钟服务访问波动。
状态管理
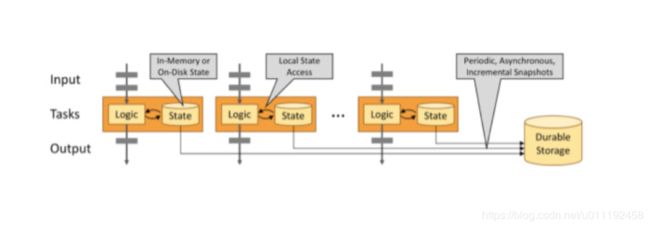
状态(state)是 Flink 程序某个时刻某个 task/operator 的状态,state数据是程序运行中某一时刻数据结果,这个state数据会保存在taskmanager的内存中,Flink 提供了丰富的状态访问和容错机制支持 Flink 完成有状态的实时流处理。
1、多种数据类型
Value,List,Map,Reducing...
2、多种划分方式
Keyed State,Operator State
3、多种存储方式
MemoryStateBackend,FsStateBackend,RocksDBStateBackend
4、高效备份和恢复
提供Exactly Once保证
为什么Flink收到青睐
了解了 Fink 以及 Flink 相关特性,总结一下为什么 Flink 为什么收到大众的亲睐,被誉为 Spark 的替代品。
同时支持批处理和实时流程序处理
支持Java和Scala API
支持高吞吐/低延迟实时处理数据
支持在不同的时间下支持灵活的窗口
自动反压机制
Exactly Once语义保证
丰富的状态管理
图计算/机器学习/复杂时间处理
当今大数据引擎该有的样子
1、强大的处理性能
性能为王,如果数据处理性能上不去,一切都是白搭。
2、批流一体化
即支持批处理又支持流处理,并且批处理和流处理的API能够很好的兼容。
3、强大的状态管理
提供丰富的状态管理方法,支持实现有状态的实时流处理,保证数据处理Exactly Once语义。
4、丰富的功能
提供丰富的接口API,能满足日常工作中各种各样的需求,包括但不限于机器学习、CEP、图计算等。
综上,对于强大的处理性能、流批一体,状态管理,丰富的API这些特性,Flink都是具备的。之所以说Flink与Spark是当今最流行的大数据计算引擎,是因为阿里巴巴、百度、腾讯、字节跳动、滴滴、美团等,几乎所有的互联网一二线大厂都在用Flink,Spark。
内容取之于AI商学院技术分享。