create function my_lower as'ramos.hive_udf_test.LowerUDF' using jar 'hdfs:///user/hive/warehouse/hive-udf-test-0.0.1-SNAPSHOT.jar';
例2
hive>
>
> create function hive2kafka as'ramos.hive_udf_test.Hive2Kafka' using jar 'hdfs:///user/hive/warehouse/hive-udf-test-0.0.1.jar';
converting to local hdfs:///user/hive/warehouse/hive-udf-test-0.0.1.jar
Added /tmp/a0a81812-1c55-4ee5-921d-c118691ef134_resources/hive-udf-test-0.0.1.jar to class path
Added resource: /tmp/a0a81812-1c55-4ee5-921d-c118691ef134_resources/hive-udf-test-0.0.1.jar
OK
Time taken: 2.576 seconds
hive>
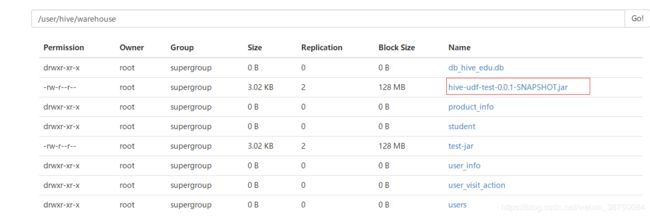
hive> dfs -put /usr/local/hive/hiveTestJar/hive-udf-test-0.0.1-SNAPSHOT.jar /user/hive/warehouse/test-jar/hive-udf-test-0.0.1-SNAPSHOT.jar;
put: Parent path is not a directory: /user/hive/warehouse/test-jar test-jar
Command failed with exit code = 1
Query returned non-zero code: 1, cause: null
hive> dfs -put /usr/local/hive/hiveTestJar/hive-udf-test-0.0.1-SNAPSHOT.jar /user/hive/warehouse/hive-udf-test-0.0.1-SNAPSHOT.jar;
hive> create function my_lower as'ramos.hive_udf_test.LowerUDF' using jar '/user/hive/warehouse/hive-udf-test-0.0.1-SNAPSHOT.jar';
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.FunctionTask. Hive warehouse is non-local, but /user/hive/warehouse/hive-udf-test-0.0.1-SNAPSHOT.jar specifies file on local filesystem. Resources on non-local warehouse should specify a non-local scheme/path
hive>
>
>
> create function my_lower as'ramos.hive_udf_test.LowerUDF' using jar 'hdfs:///user/hive/warehouse/hive-udf-test-0.0.1-SNAPSHOT.jar';
converting to local hdfs:///user/hive/warehouse/hive-udf-test-0.0.1-SNAPSHOT.jar
Added /tmp/1214f72c-84fd-42f0-a04f-14dae9ae003e_resources/hive-udf-test-0.0.1-SNAPSHOT.jar to class path
Added resource: /tmp/1214f72c-84fd-42f0-a04f-14dae9ae003e_resources/hive-udf-test-0.0.1-SNAPSHOT.jar
OK
Time taken: 0.456 seconds
hive>
查看是否有了自定义的函数:
show functions
使用自定义的函数:
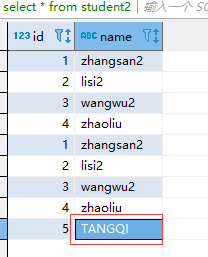
hive> select default.my_lower(name) lowername from student2;
FAILED: SemanticException [Error 10001]: Line 1:45 Table not found 'student2'
hive> select default.my_lower(name) lowername from db_hive_edu.student2;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
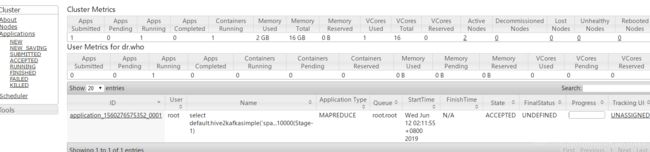
Starting Job = job_1559981808383_0012, Tracking URL = http://sparkproject1:8088/proxy/application_1559981808383_0012/
Kill Command = /usr/local/hadoop/bin/hadoop job -kill job_1559981808383_0012
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2019-06-09 05:44:34,951 Stage-1 map = 0%, reduce = 0%
2019-06-09 05:44:42,765 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.75 sec
MapReduce Total cumulative CPU time: 1 seconds 750 msec
Ended Job = job_1559981808383_0012
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.75 sec HDFS Read: 431 HDFS Write: 71 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 750 msec
OK
zhangsan2
lisi2
wangwu2
zhaoliu
zhangsan2
lisi2
wangwu2
zhaoliu
tangqi
Time taken: 19.323 seconds, Fetched: 9 row(s)
hive>
如图所示,已经将字段中的大写字母转换为小写。
实例2:创建udf,将hive数据推到kafka
1.创建为mavn项目
2.jdk用的1.8
3.代码:
java:
package com.huay;
import org.apache.hadoop.hive.ql.exec.UDF;
import java.util.HashSet;
import java.util.Set;
/**
* Created by tang on 2019/01/07
*/
public class Udf_doubleMinSalary extends UDF {
public String evaluate(String a) {
return a+"____udf";
}
public static void main(String[] args) {
//System.out.println(evaluate(6));
}
}
add jar /var/lib/hadoop-hdfs/spride_sqoop_beijing/udf_jar/udf_doubleMinSalary-0.0.1-SNAPSHOT.jar;
创建一个临时函数函数名为:doubleMinSalary
create temporary function doubleMinSalary as 'com.huay.Udf_doubleMinSalary';
udf 创建永久函数:
先把包传到hdfs:
hadoop fs -put /var/lib/hadoop-hdfs/spride_sqoop_beijing/udf_jar/udf_hive2kafka-0.0.1-SNAPSHOT.jar /user/hive/warehouse/ods.db/udf_jar/udf_hive2kafka-0.0.1-SNAPSHOT.jar
然后创建永久函数
CREATE FUNCTION udf_hive2kafka AS 'com.huay.Hive2KakfaUDF'
USING JAR 'hdfs:///user/hive/warehouse/ods.db/udf_jar/udf_hive2kafka-0.0.1-SNAPSHOT.jar';
show functions:
执行sql如;
SELECT g,default.udf_hive2kafka('lienidata001:9092','bobizlist_tzb',collect_list(map(
'bo_id',bo_id,
'full_name', full_name,
'simple_name',simple_name,
'source',source,
'company_id',company_id,
'contact',contact,
'position',position,
'mobile_phone',mobile_phone,
'phone',phone,
'email',email,
'contact_source',contact_source,
'request_host',request_host,
'request_url',request_url,
'insert_time',insert_time
))) AS result
FROM
(
SELECT r1,pmod(ABS(hash(r1)),100) AS g,bo_id,full_name,simple_name,source,company_id,contact,position,mobile_phone,phone,email,contact_source,request_host,request_url,insert_time
FROM dws_bo_final_spider_contact
LIMIT 10000
) tmp
GROUP BY g;
hive>
>
> CREATE FUNCTION hive2kafkaSimple AS 'ramos.hive_udf_test.HiveToKakfaSimple'
> USING JAR 'hdfs:///user/hive/warehouse/hive-udf-test-0.0.1.jar';
converting to local hdfs:///user/hive/warehouse/hive-udf-test-0.0.1.jar
Added /tmp/5ef75554-8a71-43f4-b8f4-e413df882e49_resources/hive-udf-test-0.0.1.jar to class path
Added resource: /tmp/5ef75554-8a71-43f4-b8f4-e413df882e49_resources/hive-udf-test-0.0.1.jar
java.lang.UnsupportedClassVersionError: ramos/hive_udf_test/HiveToKakfaSimple : Unsupported major.minor version 52.0
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:800)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
at java.net.URLClassLoader.access$100(URLClassLoader.java:71)
at java.net.URLClassLoader$1.run(URLClassLoader.java:361)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:270)
at org.apache.hadoop.hive.ql.exec.FunctionTask.getUdfClass(FunctionTask.java:313)
at org.apache.hadoop.hive.ql.exec.FunctionTask.createPermanentFunction(FunctionTask.java:138)
at org.apache.hadoop.hive.ql.exec.FunctionTask.execute(FunctionTask.java:84)
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:155)
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:85)
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:1554)
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1321)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1139)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:962)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:952)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:269)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:221)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:431)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:800)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:694)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:633)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
FAILED: Execution Error, return code -101 from org.apache.hadoop.hive.ql.exec.FunctionTask. ramos/hive_udf_test/HiveToKakfaSimple : Unsupported major.minor version 52.0
hive> You have new mail in /var/spool/mail/root
参考 :https://www.cnblogs.com/jpfss/p/9036645.html
Unsupported major.minor version 52.0: 看到Unsupported你是不是会想到jdk高版本能兼容低版本,但是低版本不能兼容高版本,不错,猜对了,其实就是这个意思。“本地jdk版本太低,不支持这个jdk1.8编译过的项目运行”。
解决方法 :使用对应的版本编译,如我这里需要用1.7,要用1.7打包。
下面是具体实例和使用 方法:
IDEA
java代码:
package ramos.hive_udf_test;
import com.alibaba.fastjson.JSONObject;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import kafka.serializer.StringEncoder;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* Created by tang on 2019/01/07
*/
public class HiveToKakfaSimple extends UDF {
public String evaluate(String zklis,String brokerlis,String topic,String id,String name) {
Producer producer = createProducer(zklis,brokerlis);
Map params = new HashMap();
params.put("id", id);
params.put("name", name);
Object o = JSONObject.toJSON(params);
producer.send(new KeyedMessage(topic,o.toString()));
return o.toString();
}
private static Producer createProducer(String zklis,String brokerlis) {
Properties properties = new Properties();
properties.put("zookeeper.connect", zklis);//声明zk 多个ip逗号分隔
properties.put("serializer.class", StringEncoder.class.getName());
properties.put("metadata.broker.list", brokerlis);// 声明kafka broker
return new Producer(new ProducerConfig(properties));
}
}
java.lang.NullPointerException: Attempt to invoke virtual method 'int android.view.View.getImportantForAccessibility()' on a null object reference
出现以上异常.然后就在baidu上
cmd命令打jar是如下实现:
在运行里输入cmd,利用cmd命令进入到本地的工作盘符。(如我的是D盘下的文件有此路径 D:\workspace\prpall\WEB-INF\classes)
现在是想把D:\workspace\prpall\WEB-INF\classes路径下所有的文件打包成prpall.jar。然后继续如下操作:
cd D: 回车
cd workspace/prpal
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml&q
Given a 2D binary matrix filled with 0's and 1's, find the largest rectangle containing all ones and return its area.
public class Solution {
public int maximalRectangle(char[][] matrix)
随着RESTful Web Service的流行,测试对外的Service是否满足期望也变的必要的。从Spring 3.2开始Spring了Spring Web测试框架,如果版本低于3.2,请使用spring-test-mvc项目(合并到spring3.2中了)。
Spring MVC测试框架提供了对服务器端和客户端(基于RestTemplate的客户端)提供了支持。
&nbs
[[UIApplication sharedApplication] setStatusBarStyle:UIStatusBarStyleLightContent];
/*you'll also need to set UIViewControllerBasedStatusBarAppearance to NO in the plist file if you use this method
英文资料:
Thread Dump and Concurrency Locks
Thread dumps are very useful for diagnosing synchronization related problems such as deadlocks on object monitors. Ctrl-\ on Solaris/Linux or Ctrl-B