利用python指定爬取LOL全皮肤
声明
本文用到了jsonpath解析如有不懂可以看一下这里
链接:https://blog.csdn.net/weixin_45859193/article/details/107081107
爬取全部LOL皮肤链接:https://blog.csdn.net/weixin_45859193/article/details/107301172
提示:(爬取LOL全皮肤有部分皮肤不能爬取,这篇文章也会把他讲完,希望有大佬能指导指导)
开始
在之前的博客爬取LOL皮肤过程中,我发现,我写的jsonpath是皮肤,但是皮肤的名字有些可能是炫彩皮肤然后链接和皮肤名字不相等导致皮肤爬取不成功,后来我找到了规律发现了…

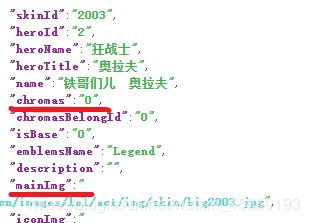
看完这张图片不难发现规律了,原来之前是因为有空格所以抓取不了的原因啊。
然后我开始写了代码,由于那时python基础没学扎实导致的代码是这样的…(不过挺佩服自己那时的想法的= = )
(这个代码仅供参考,是效率很低的代码,具体看下面的代码,不想看思路可以跳过)
import requests
import jsonpath
import os
from urllib.request import urlretrieve
data=input(("请输入下载皮肤名字:"))
#目标url
url='https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
#模拟浏览器
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
#解析数据
req=requests.get(url,headers=headers).json()
#获取id
id_1_key=jsonpath.jsonpath(req,'$..banAudio')
#定义一个空列表
items=[]
for id_1 in id_1_key:
#分割id,取出id
id_2=id_1.split('ban/')[1][0:-4]
#将分割出来的id放在一个列表里
items.append(id_2)
#访问的url
new_url='https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(id_2)
#解析数据
req=requests.get(new_url,headers=headers).json()
#找到数据的名字
hero=req["hero"]
datas=jsonpath.jsonpath(hero,'$..name')
#判断是否和打印数据名字相同
if data == datas[0]:
skins=req["skins"]
#获取数据
mainImgs=jsonpath.jsonpath(req,'$..mainImg')
names=jsonpath.jsonpath(skins,'$..name')
#这里是我在爬取的时候发现有些图片不能爬取,找到规律
chromas=jsonpath.jsonpath(skins,'$..chromas')
i=0
#判断字符有多少
num=len(names)
#把不要的数据转换为''等会好删除
for i in range(0,num):
if chromas[i]=='1':
names[i]=''
#删除空格
for i in names:
if i=='':
names.remove('')
#删除空格
for i in mainImgs:
if i=='':
mainImgs.remove('')
#创建一个文件夹
os.mkdir(names[0])
try:
for name,mainImgs in zip(names,mainImgs):
#保存数据
urlretrieve(mainImgs,names[0]+"/"+name+".jpg")
print(name+"100%")
except:
pass
#如果找到了就退出循环,这是if的break
break
#判断是不是名字打错了
if data !=datas[0]:
print('没有相关名称!')
不得不说,可以是可以不过效率是真的低,随后我进行了小小的改动
具体代码
import requests
import jsonpath
import os
from urllib.request import urlretrieve
n=input('请输入你想下载的皮肤名字:')
url='https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
req=requests.get(url,headers).json()
#获取id号
id_list=jsonpath.jsonpath(req,'$..heroId')
#获取名字
names=jsonpath.jsonpath(req,'$..name')
for id_,name in zip(id_list,names):
if n==name:
names[0]=n
n=id_
break
if(n!=id_):
print('不存在的皮肤名!')
else:
response='https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(n)
data=requests.get(response,headers).json()
name_2=jsonpath.jsonpath(data["skins"],'$..name')
link_1=jsonpath.jsonpath(data["skins"],'$..mainImg')
chromas=jsonpath.jsonpath(data["skins"],'$..chromas')
num=len(name_2)
for i in range(0,num):
if chromas[i]=='1':
name_2[i]=''
for name in name_2:
if name=='':
name_2.remove(name)
for i in link_1:
if i=='':
link_1.remove(i)
os.mkdir(names[0])
for name_1,link in zip(name_2,link_1):
try:
urlretrieve(link,names[0]+'/'+name_1+'.jpg')
print(name_1+'100%')
except:
pass
思路
这条代码的思路主要是看到了一开始的json有所有英雄的id和名字。具体请看之前的全部抓取LOL链接:https://blog.csdn.net/weixin_45859193/article/details/107301172
总结
python基础一定要学扎实啊!!!