
高中同学群最近突然讨论起了NBA,作为姚明退役后就再也没看过球的伪球迷,感觉有点说不上话。
为了改善下赛季的群聊体验,决定研究下一直很感兴趣的比赛预测问题。
1. 简介
本文通过basketball reference提供的18-19赛季统计数据,构造包含球队Elo评分的样本,利用logistic回归模型进行建模,并验证准确性。最后,由于18-19赛季刚刚结束,19-20赛季日程尚未公布,利用18-19赛季的日程对赛果进行模拟预测,验证该方法的可用性。
2. 数据与方法来源
- 数据:NBA一直以完善的数据统计系统著称,本文使用的数据来源为https://www.basketball-reference.com/
- 方法:本文主要基于《利用Python预测NBA比赛结果》,对一些内容进行了勘误和优化。
3. 主要步骤
3.1 数据获取与整理:
数据获取的具体方法请见这里。
这里需要用到基于18-19赛季的4张表格:
-
Team Per Game Stats(简称T表):记录了场均技术统计数据
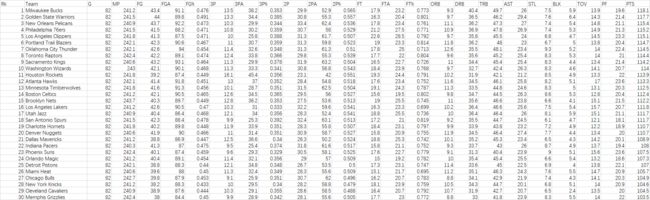 T表
T表 Opponent Per Game Stats(简称O表):记录了对手的场均技术统计数据,结构与T表相同
Miscellaneous Stats(简称M表):其他统计数据
| 数据项 | 数据含义 |
|---|---|
| Rk (Rank) | 联盟排名 |
| Age | 球员平均年龄 |
| W (Wins) | 胜场数 |
| L (Losses) | 败场数 |
| PW (Pythagorean wins) | 基于毕达哥拉斯理论计算的胜场数 |
| PL (Pythagorean losses) | 基于毕达哥拉斯理论计算的败场数 |
| MOV (Margin of Victory) | 场均分差 |
| SOS (Strength of Schedule) | 赛程难度(跟赛区有关,不同赛区间相遇场次不同) |
| SRS (Simple Rating System) | 综合考虑MOV和SOS后得出的评分,具体公式未知 |
| ORtg (Offensive Rating) | 每100回合的进攻得分 |
| DRtg (Defensive Rating) | 每100的回合中防守得分 |
| Pace (Pace Factor) | 场均回合数 |
| FTr (Free Throw Attempt Rate) | 罚球占投篮次数的比例 |
| 3PAr (3-Point Attempt Rate) | 三分球占投篮次数的比例 |
| TS% (True Shooting Percentage) | 二分球、三分球和罚球的总共命中率 |
| eFG% (Effective Field Goal Percentage) | 有效的投射百分比(考虑三分球权重) |
| TOV% (Turnover Percentage) | 失误率 |
| ORB% (Offensive Rebound Percentage) | 进攻篮板率 |
| FT/FGA | 每次进攻导致的罚球数 |
| eFG% (Opponent Effective Field Goal Percentage) | 对手命中率 |
| TOV% (Opponent Turnover Percentage) | 对手失误率 |
| DRB% (Defensive Rebound Percentage) | 对手防守篮板率 |
| FT/FGA (Opponent Free Throws Per Field Goal Attempt) | 对手的罚球次数占投射次数的比例 |
其中比较有趣的是毕达哥拉斯胜场数,一个在体育菠菜中的重要参考指标:
美國棒球統計專家比爾˙詹姆斯在80年代初整理美國職業網球聯盟球隊的過去成績時,發現可以用一支球隊的總得分和總失分算出勝率。然後用直角三角型斜線長的平方,等於其他兩邊乘和的“畢達哥拉斯定理”算出了一個公式。就是“勝率=總得分的平方÷(總得分的平方+總失分的平方)”,即“畢達哥拉斯乘率”。
来源:計算“畢達哥拉斯勝率”SK,最有成績的棒球
将T、M、O三表读入并去除部分列,拼接在一起:
def initialize_data(Mstat, Ostat, Tstat): # csv文件初始化
new_Mstat = Mstat.drop(['Rk', 'Arena'], axis=1)
new_Ostat = Ostat.drop(['Rk', 'G', 'MP'], axis=1)
new_Tstat = Tstat.drop(['Rk', 'G', 'MP'], axis=1)
team_stats1 = pd.merge(new_Mstat, new_Ostat, how='left', on='Team')
team_stats1 = pd.merge(team_stats1, new_Tstat, how='left', on='Team')
return team_stats1.set_index('Team', inplace=False, drop=True)
- 包含主客场信息的赛果表(wlloc.csv):
这张表需要从basketball reference获取相关数据后手工处理一下,将结构改成如下形式:
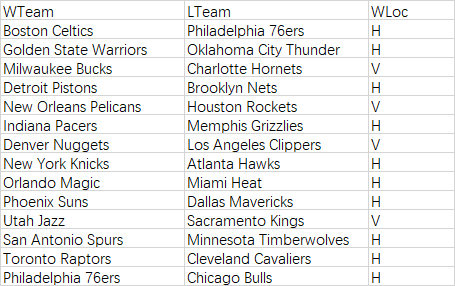 包含主客场信息的赛果表(wlloc.csv)
包含主客场信息的赛果表(wlloc.csv)
3.2 根据每场比赛的结果构建样本(包含Elo Score):
当最初没有elo时,给每个队伍最初赋base_elo:
def get_elo(team):
try:
return team_elos[team]
except:
# 当最初没有elo时,给每个队伍最初赋base_elo
team_elos[team] = base_elo
return team_elos[team]
通过wlloc.csv计算每个球队的elo值:
def calc_elo(win_team, lose_team):
winner_rank = get_elo(win_team)
loser_rank = get_elo(lose_team)
rank_diff = winner_rank - loser_rank
exp = (rank_diff*-1) / 400
odds = 1 / (1 + math.pow(10, exp))
# 根据rank级别修改K值
if winner_rank < 2100:
k = 32
elif 2100 <= winner_rank < 2400:
k = 24
else:
k = 16
new_winner_rank = round(winner_rank + (k * (1 - odds)))
new_rank_diff = new_winner_rank - winner_rank
new_loser_rank = loser_rank - new_rank_diff
return new_winner_rank, new_loser_rank
之后将Elo score和其他统计数据通过 build_dataSet()拼接在一起(详见文末),构成样本X,其具体结构为:
[Elo score(A), T(A), O(A), M(A), Elo score(B), T(B), O(B), M(B)],
用向量y记录胜负(0-1)。
下面是Elo rating system的简介:
ELO等级分制度(英语:Elo rating system)是指由匈牙利裔美国物理学家Arpad Elo创建的一个衡量各类对弈活动水平的评价方法,是当今对弈水平评估的公认的权威方法。被广泛用于国际象棋、围棋、足球、篮球等运动。网络游戏英雄联盟、魔兽世界、王者荣耀内的竞技对战系统也采用此分级制度。
假设棋手A和B的当前等级分分别为RA和RB,则按Logistic distribution A对B的胜率期望值当为:

假如棋手A在比赛中的真实得分 SA(胜=1分,和=0.5分,负=0分)和他的胜率期望值 EA不同,需要根据以下公式进行调整:
按照国际象棋的习惯,K的取值方法为:
- 评分<2100: K = 32;
- 2100 < 评分 < 2400: k = 24;
- 评分> 2400: K = 16.(大师级棋手)
3.3 通过logistic回归模型进行建模和预测:
用(X, y)训练模型,做十折交叉验证,并进行预测。
运行结果实例:

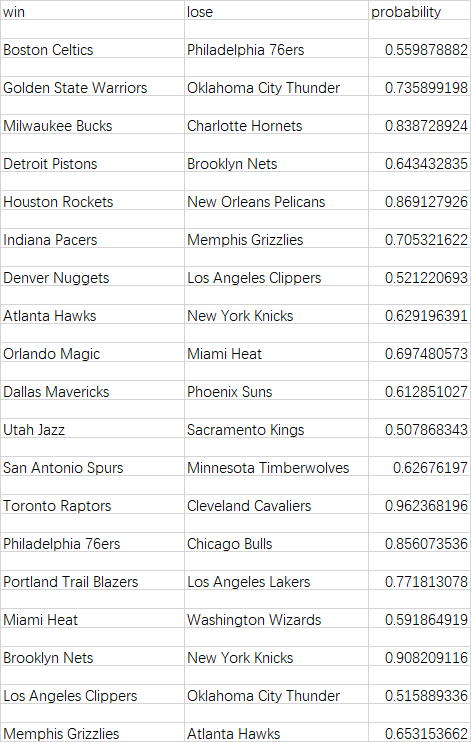
4. 结尾
关注NBA的同学可以看看,模拟预测结果是否符合18-19赛季各队的实力情况。
Elo score不是预测绝对胜负,而是相对胜率的一种评分方法,因此本方法也不是预测绝对胜负,只是基于实力预测胜率。虽然目前看预测准确率比较高(65%左右),但19年夏天各种转会地震层出不穷,相信对下赛季的预测准确性是个挑战,拭目以待中~
方法总体上不是很复杂,但也有很多小细节需要注意,具体请见全部代码中的注释吧~
全部代码如下:
import pandas as pd
import math
import csv
import random
import numpy as np
from sklearn import linear_model
from sklearn.model_selection import cross_val_score
# 初始化
base_elo = 1600
team_elos = {}
team_stats = {}
folder = 'H:\\quant\\NBA\\' # 存放数据的目录
def initialize_data(Mstat, Ostat, Tstat): # csv文件初始化
new_Mstat = Mstat.drop(['Rk', 'Arena'], axis=1)
new_Ostat = Ostat.drop(['Rk', 'G', 'MP'], axis=1)
new_Tstat = Tstat.drop(['Rk', 'G', 'MP'], axis=1)
team_stats1 = pd.merge(new_Mstat, new_Ostat, how='left', on='Team')
team_stats1 = pd.merge(team_stats1, new_Tstat, how='left', on='Team')
return team_stats1.set_index('Team', inplace=False, drop=True)
def get_elo(team):
try:
return team_elos[team]
except:
# 当最初没有elo时,给每个队伍最初赋base_elo
team_elos[team] = base_elo
return team_elos[team]
# 计算每个球队的elo值
def calc_elo(win_team, lose_team):
winner_rank = get_elo(win_team)
loser_rank = get_elo(lose_team)
rank_diff = winner_rank - loser_rank
exp = (rank_diff*-1) / 400
odds = 1 / (1 + math.pow(10, exp))
# 根据rank级别修改K值
if winner_rank < 2100:
k = 32
elif 2100 <= winner_rank < 2400:
k = 24
else:
k = 16
new_winner_rank = round(winner_rank + (k * (1 - odds)))
new_rank_diff = new_winner_rank - winner_rank
new_loser_rank = loser_rank - new_rank_diff
return new_winner_rank, new_loser_rank
def build_dataSet(all_data):
print("Building data set..")
X = []
y = []
for index, row in all_data.iterrows():
Wteam = row['WTeam']
Lteam = row['LTeam']
# 获取最初的elo或是每个队伍最初的elo值
team1_elo = get_elo(Wteam)
team2_elo = get_elo(Lteam)
# 体现主场优势:给主场比赛的队伍加上100的elo值
if row['WLoc'] == 'H':
team1_elo += 100
else:
team2_elo += 100
# 把elo作为评价每个队伍的第一个特征值
team1_features = [team1_elo]
team2_features = [team2_elo]
# 添加我们从basketball reference.com获得的每个队伍的统计信息
for key, value in team_stats.loc[Wteam].iteritems():
team1_features.append(value)
for key, value in team_stats.loc[Lteam].iteritems():
team2_features.append(value)
# 将两支队伍的特征值随机的分配在每场比赛数据的左右两侧
# 并将对应的0/1赋给y值
if random.random() > 0.5:
X.append(team1_features + team2_features)
y.append(0)
else:
X.append(team2_features + team1_features)
y.append(1)
# 根据这场比赛的数据更新队伍的elo值
new_winner_rank, new_loser_rank = calc_elo(Wteam, Lteam)
team_elos[Wteam] = new_winner_rank
team_elos[Lteam] = new_loser_rank
return np.nan_to_num(X), np.array(y)
def predict_winner(team_1, team_2, model):
features = []
# team 1,客场队伍
features.append(get_elo(team_1))
for key, value in team_stats.loc[team_1].iteritems():
features.append(value)
# team 2,主场队伍
features.append(get_elo(team_2) + 100)
for key, value in team_stats.loc[team_2].iteritems():
features.append(value)
features = np.nan_to_num(features)
return model.predict_proba([features])
if __name__ == '__main__':
Mstat = pd.read_csv(folder + '/M.csv')
Ostat = pd.read_csv(folder + '/O.csv')
Tstat = pd.read_csv(folder + '/T.csv')
team_stats = initialize_data(Mstat, Ostat, Tstat)
result_data = pd.read_csv(folder + '/wlloc.csv')
X, y = build_dataSet(result_data)
# 训练网络模型
print("Fitting on %d game samples.." % len(X))
model = linear_model.LogisticRegression()
model.fit(X, y)
# 利用10折交叉验证计算训练正确率
print("Doing cross-validation..")
print(cross_val_score(model, X, y, cv = 10, scoring='accuracy', n_jobs=-1).mean())
print('Predicting on new schedule..')
schedule1819 = pd.read_csv(folder + '18-19Schedule.csv')
result = []
for index, row in schedule1819.iterrows():
team1 = row['Vteam']
team2 = row['Hteam']
pred = predict_winner(team1, team2, model)
prob = pred[0][0]
if prob > 0.5:
winner = team1
loser = team2
result.append([winner, loser, prob])
else:
winner = team2
loser = team1
result.append([winner, loser, 1 - prob])
with open('18-19Result.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['win', 'lose', 'probability'])
writer.writerows(result)
print('Ω')