C# 浅显易懂搞明白,哈希一致性算法的原理与实现,
有图有真相
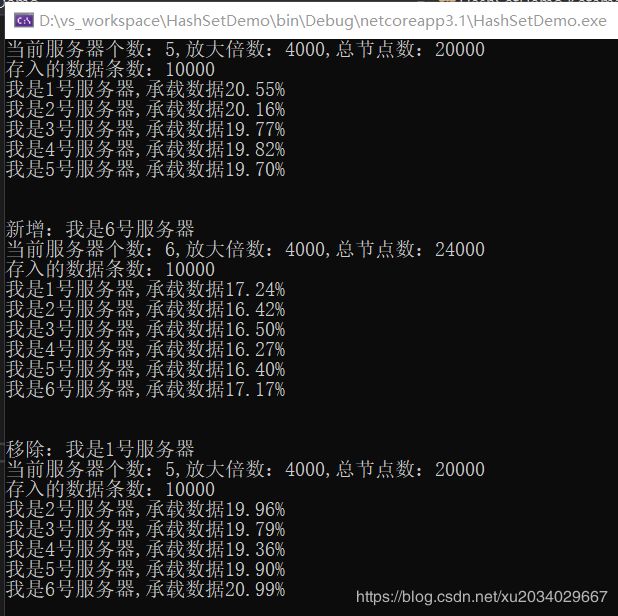
原理:根据特定的字符串比如5台服务器ip的数组,按照一定放大倍数比如4000倍,哈希映射出20000个哈希值,他们的关系存到ketamaNides数组中,每台服务器,对应相同等份的4000个哈希值,
现在有一批量字符串数据,比如10000条要存进来,如何决定它存到哪台服务器呢?
这个hash值和根据服务器ip映射出来的hash值,可以比较大小,
根据ketamaNodes找到距离最近的一个服务器ip映射出来的hash值,进而知道该服务器名称,
重点是根据hash定义,不管它是什么字符串,都可以映射成等长的hash值,
博主这种说法也许并不专业,但是绝对浅显易懂,帮助理解是没问题的!
using System;
using System.Collections.Generic;
using System.Linq;
using System.Security.Cryptography;
using System.Text;
namespace HashSetDemo
{
public class KetamaNodeLocator
{
private SortedList ketamaNodes = new SortedList();
private HashAlgorithm hashAlg;
private int numReps = 4000;
public List services;
//每台服务器负载,和具体数据没多大关系,
public int TestItem = 10000;
public KetamaNodeLocator(List nodes/*,int nodeCopies*/)
{
services = nodes;
ketamaNodes = new SortedList();
//numReps = nodeCopies;
//对所有节点,生成nCopies个虚拟结点
//方便理解,就认为有四个物理节点
foreach (string node in nodes)
{
//每四个虚拟结点为一组
//40组,160节点
for (int i = 0; i < numReps / 4; i++)
{
//getKeyForNode方法为这组虚拟结点得到惟一名称
//每一个物理节点,需要生成四十个虚拟节点
byte[] digest = HashAlgorithm.computeMd5(node + i);
/** Md5是一个16字节长度的数组,将16字节的数组每四个字节一组,分别对应一个虚拟结点,这就是为什么上面把虚拟结点四个划分一组的原因*/
//具体给每一个虚拟节点生成一个哈希值,
//四十个组,每组再循环四组
for (int h = 0; h < 4; h++)
{
long m = HashAlgorithm.hash(digest, h);
ketamaNodes[m] = node;
}
}
}
//关键关键的是,每个ketamaNodes存,hash值和每台物理机器ip
//只是为何不更简单点,直接A_1_1 A_1_2这样划分一百六十个虚拟节点呢
}
public string GetPrimary(string k)
{
byte[] digest = HashAlgorithm.computeMd5(k);
string rv = GetNodeForKey(HashAlgorithm.hash(digest, 0));
return rv;
}
public void AddServer(string nodename)
{
//循环muti次数,给一个名字,生成不同的hash值,即一个hash环
//同一个名字,产生不同的hash值散布关联
services.Add(nodename);
//每四个虚拟结点为一组
//40组,160节点
for (int i = 0; i < numReps / 4; i++)
{
//getKeyForNode方法为这组虚拟结点得到惟一名称
//每一个物理节点,需要生成四十个虚拟节点
byte[] digest = HashAlgorithm.computeMd5(nodename + i);
/** Md5是一个16字节长度的数组,将16字节的数组每四个字节一组,分别对应一个虚拟结点,这就是为什么上面把虚拟结点四个划分一组的原因*/
//具体给每一个虚拟节点生成一个哈希值,
//四十个组,每组再循环四组
for (int h = 0; h < 4; h++)
{
long m = HashAlgorithm.hash(digest, h);
ketamaNodes[m] = nodename;
}
}
Console.WriteLine("新增:" + nodename);
}
//删除某台服务器,删除对应所有的hash
public void RemoveServer(string nodename)
{
//每四个虚拟结点为一组
services.Remove(nodename);
//40组,160节点
for (int i = 0; i < numReps / 4; i++)
{
//getKeyForNode方法为这组虚拟结点得到惟一名称
//每一个物理节点,需要生成四十个虚拟节点
byte[] digest = HashAlgorithm.computeMd5(nodename + i);
/** Md5是一个16字节长度的数组,将16字节的数组每四个字节一组,分别对应一个虚拟结点,这就是为什么上面把虚拟结点四个划分一组的原因*/
//具体给每一个虚拟节点生成一个哈希值,
//四十个组,每组再循环四组
for (int h = 0; h < 4; h++)
{
long m = HashAlgorithm.hash(digest, h);
ketamaNodes.Remove(m);
}
}
Console.WriteLine("移除:"+nodename);
}
string GetNodeForKey(long hash)
{
string rv;
long key = hash;
//如果找到这个节点,直接取节点,返回
if (!ketamaNodes.ContainsKey(key))
{
var tailMap = from coll in ketamaNodes
where coll.Key > hash
select new { coll.Key };
if (tailMap == null || tailMap.Count() == 0)
key = ketamaNodes.FirstOrDefault().Key;
else
key = tailMap.FirstOrDefault().Key;
}
rv = ketamaNodes[key];
return rv;
}
//打印消息
public void Print()
{
Console.WriteLine($"当前服务器个数:{services.Count},放大倍数:{numReps},总节点数:{services.Count*numReps}");
//单独存放每台服务器中添加数据条数,
SortedList data= new SortedList();
//存多少条数据进入,根据hash算法,存到那台服务器,但是
//160放大倍数,形成将近一百六十个节点,会不会数据过大,全部落在外面呢?即
//有可能很多比最小值小,那么放在第一台数量将会很多,同理很多比最大值大,放在最后一台数量要多
for (int i = 0; i < TestItem; i++)
{
//!!!!!注意kelata里面的hash都是通过以下两步获取对应的hash,后面nTime默认给0即可
string vname=GetNodeForKey(HashAlgorithm.hash(HashAlgorithm.computeMd5($"我是要存的数据{i}"),0));
//通过kelataNodes集合,找到数据,该存入的服务器名称,
//一定能找到么?尽管这个值不一定等于已存在的某个key,不过仍然能找到大于这个hash的下一个key,所对应的服务器
//,1-3-5,7-9-11,如果是8大于它就是9放在第二台服务器
if (data.ContainsKey(vname))
{
data[vname] += 1;
}
else {
data[vname] = 1;
}
}
//
Console.WriteLine($"存入的数据条数:{TestItem}");
foreach (var item in data)
{
Console.WriteLine($"{item.Key},承载数据{((float)item.Value/(float)TestItem*100).ToString("0.00")}%");
}
}
}
public class HashAlgorithm
{
//这是一种hash算法
public static long hash(byte[] digest, int nTime)
{
long rv = ((long)(digest[3 + nTime * 4] & 0xFF) << 24)
| ((long)(digest[2 + nTime * 4] & 0xFF) << 16)
| ((long)(digest[1 + nTime * 4] & 0xFF) << 8)
| ((long)digest[0 + nTime * 4] & 0xFF);
return rv & 0xffffffffL; /* Truncate to 32-bits */
}
/**
* Get the md5 of the given key.
*/
public static byte[] computeMd5(string k)
{
MD5 md5 = new MD5CryptoServiceProvider();
byte[] keyBytes = md5.ComputeHash(Encoding.UTF8.GetBytes(k));
md5.Clear();
//md5.update(keyBytes);
//return md5.digest();
return keyBytes;
}
}
}
KetamaNodeLocator kn = new KetamaNodeLocator(new List() { "我是1号服务器", "我是2号服务器", "我是3号服务器", "我是4号服务器", "我是5号服务器"});
kn.Print();
Console.WriteLine("\r\n");
kn.AddServer("我是6号服务器");
kn.Print();
Console.WriteLine("\r\n");
kn.RemoveServer("我是1号服务器");
kn.Print();
Console.ReadLine();