1 Semantic Object Parsing with Graph LSTM
——NUS ECCV2016(Spotlight)
1.1 任务描述
semantic object parsing aims to segment an object within an image into multiple parts with more fine-grained semantics and provide full understanding of image contents.
1.2 模型框架

adaptive graph topology(每张图像都是不同的graph topology)
(semantically consistent) node: arbitrary-shaped superpixel
edge: spatial neighborhood relations 空间相邻就连一条边
LSTM starting node: the superpixel node that has the highest predicted confidence across all the foreground semantic labels based on the initial features is regarded as the starting node
Updating order: ranking all the nodes according to their initial confidences on foreground classes in a descending order

Graph construction
Superpixel map: image over-segmentation using SLIC 线性迭代聚类( k均值聚类方法) averagely 1,000
feature maps需要upsample到原始图像大小,和superpixel map对应起来。
node初始特征f_i:同一个superpixel中所有像素特征的平均值
Graph LSTM
initial confidence maps
The confidence of each superpixel for each label: averaging the confidences of its contained pixels, and the label with highest confidence could be assigned to the superpixel
Node updating sequence: Among all the foreground superpixels (i.e., assigned to any semantic part label), the node updating sequence can be determined by ranking all the superpixel nodes according to the confidences of their assigned labels
Confidence-Driven Search表现好的原因: The CDS scheme can provide a relatively more reliable updating sequence for better semantic reasoning, since the earlier nodes in the updated sequence presumably have stronger semantic evidence (e.g., belonging to any important semantic parts with higher confidence) and their visual features may be more reliable for message passing.
Training
1. train the convolutional layer with 1 × 1 filters to generate initial confidence maps that are used to produce the starting node and the update sequence for all nodes in Graph LSTM
2. the whole network is fine-tuned based on the pretrained model to produce final parsing results
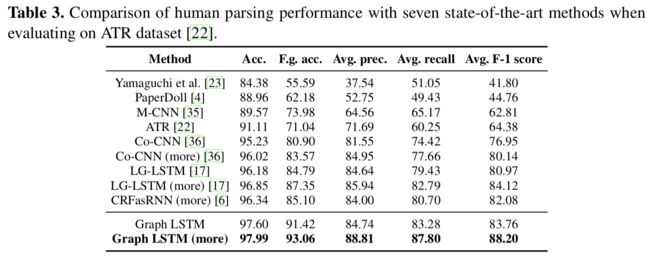
1.3 实验结果
PASCAL-Person-Part dataset: Head, Torso, Upper/Lower Arms and Upper/Lower Legs
Horse-Cow Parsing dataset: head, leg, tail and body
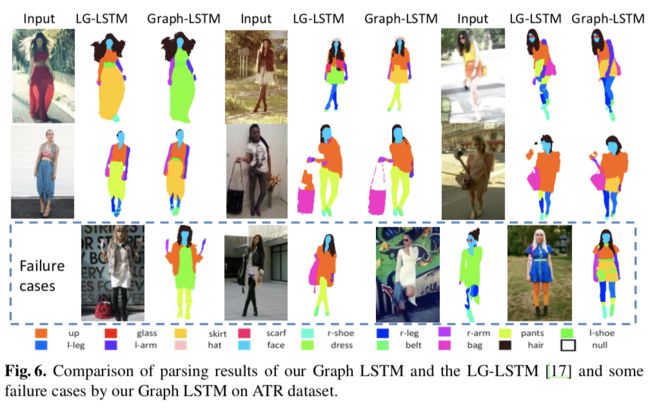
ATR dataset & Fashionista dataset: 18 labels: face, sunglass, hat, scarf, hair, upper-clothes, left-arm, right-arm, belt, pants, left-leg, right-leg, skirt, left-shoe, right-shoe, bag, dress and null
每个dataset都是的同一类物体,label是组成该物体的部分,比较符合医疗的分割
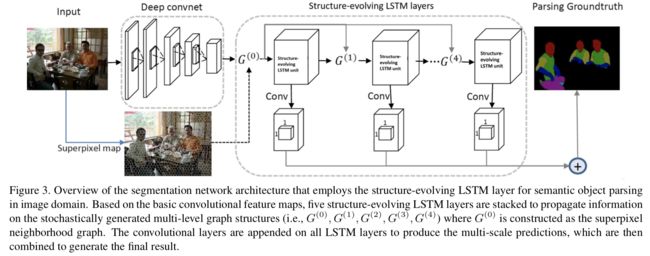
2 Interpretable Structure-Evolving LSTM可解释结构演化LSTM
——CMU CVPR2017
论文1的进阶版
2.1 主要思路

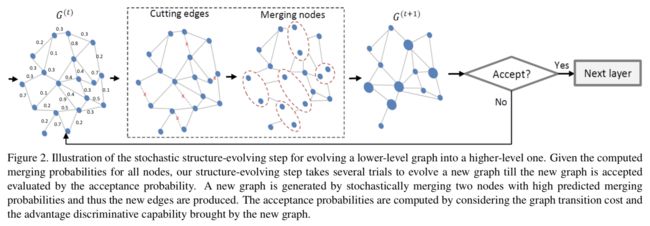
Metropolis-Hasting algorithm: stochastically merging some graph nodes by sampling their merging probabilities, and produces a new graph structure
This structure is further examined and determined according to a global reward defined as an acceptance probability. i) a state transition probability (i.e., a product of the merging probabilities); ii) a posterior probability representing the compatibility of the generated graph structure with task-specific observations.
2.3 实验结果
3 3D Graph Neural Networks for RGBD Semantic Segmentation
——CUHK ICCV2017
RGBD = RGB + Depth Map
2D appearance + 3D geometric information
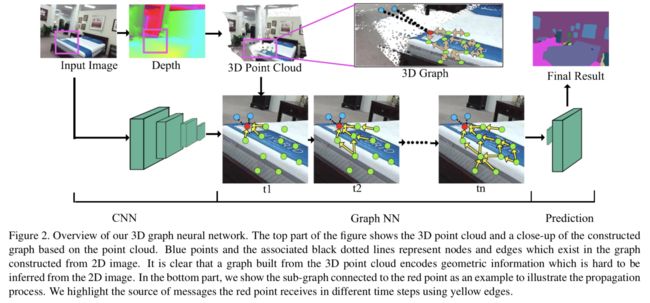
Graph construction*

node: pixel
directed edges: K nearest neighbors (KNN) in the 3D space
Propagation Model
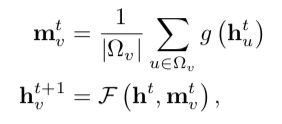
Prediction Model
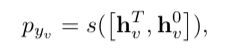
back-propagation through time (BPTT) algorithm
4 总结
这是一种更加精细的语义分割
从dataset上看,每个dataset都是的同一类物体,label是组成该物体的部分,
horse-cow dataset 头和身体在颜色上没有明显的边界,但也能分出来,有点像多器官分割里的情况
比较符合医疗的分割