图解mysql索引---历史最详细、最清楚的讲解
我们先来列一个提纲,从以下几个方面介绍mysql索引
- 1、索引的本质
- 2、索引结构及其详细解读(二叉树、红黑树、HASH、B-Tree、B+Tree)
- 3、非聚集索引(MyISAM)、聚集索引(InnoDB)
- 4、常见问题
一、索引的本质
- 索引是帮助mysql高效获取数据的排好序的数据结构
- 索引存储在文件里
- 索引结构
- 二叉树
- Hash
- B树
注意:索引起的作用是:排好序的快速查找数据结构!索引会影响where后面的查找,和order by 后面的排序。
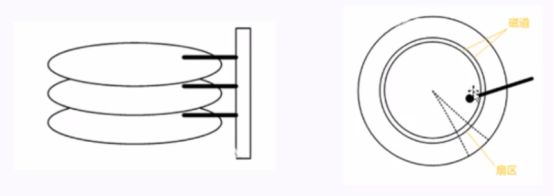
关系型数据库的数据是存储在磁盘上面,且是不均匀存在不同的扇区上的,查询内容需要磁头在磁盘去寻找,找一次就是一次磁盘I/O。
- 磁盘存取原理
- 寻道时间(速度慢,费时)
- 旋转时间(速度较快)
二、索引结构及其详细解读(二叉树、红黑树、HASH、B-Tree、B+Tree)
接下来我们根据一张图来讲解几种索引
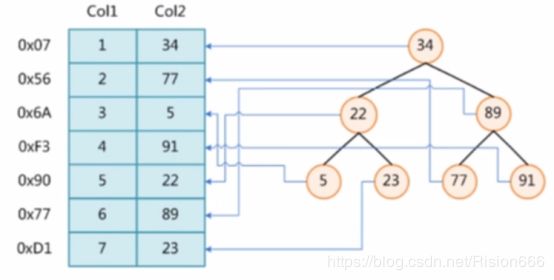
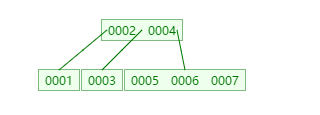
1、二叉树:右边的子元素大于父元素,左边的子元素小于父元素。如下图
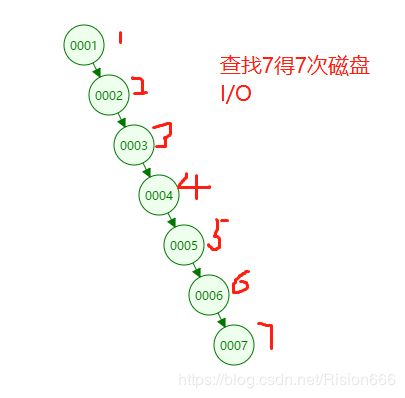
从上图可以看到,执行where col1=0007时,得经过7次磁盘IO
现在通过二叉树算法给col2建立索引,执行where col2=89时,第一次查34,然后再查89,经过两次磁盘io查到了。
2、红黑树(二叉平衡树):

从上图可以看到,执行where col1=0007时,得经过4次磁盘I/O,很明显比二叉树少了很多次磁盘I/O操作
总结:二叉树和红黑树的缺点就是:树的高度太高
存储1000万条数据,设树的高度为n,则![]() ,则n=23.253497。
,则n=23.253497。
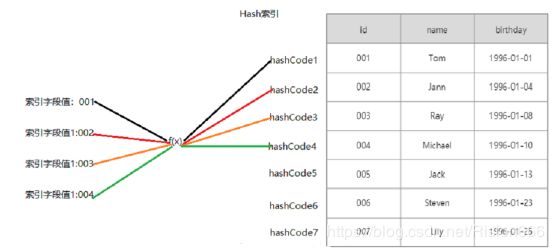
3、Hash索引:
基于哈希表实现,只有精确匹配索引所有列的查询才有效,对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),并且Hash索引将所有的哈希码存储在索引中,同时在索引表中保存指向每个数据行的指针。
4、B-Tree:多叉平衡树
-
度(Degree)-节点的数据存储个数
-
叶节点具有相同的深度
-
叶节点的指针为空
-
节点中的数据key从左到右递增排列
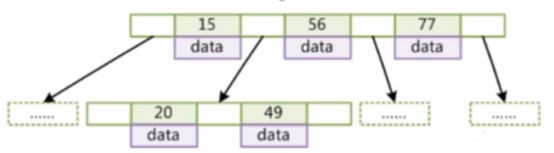
B-Tree缺点
现在要查找where col>20,则困难重重,得找好多次,下面我们来看一下B树变种B+树
5、B+Tree(B-Tree变种):
-
非叶子节点不存储data,只存储key,可以增大度
-
叶子节点不存储指针
-
顺序访问指针,提高区间访问的性能
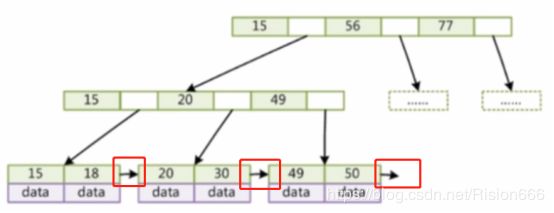
从上图可以看到找到where col>20的数据,根据指针一次就能找出来
B+Tree索引的性能分析
- 一次使用磁盘I/O次数评价索引结构的优劣
- 预读:磁盘一般会顺序向后读取一定长度的数据(页的整数倍)放入内存
- 局部性原理:当一个数据被用到时,其附近改的数据也通常马上被使用
- B+Tree节点的大小设为等于一个页,每次新建节点直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,就实现了一个节点的载入只需一个I/O
- B+Tree的度d一般不会超过100,因此h非常小(一般为1到3之间)
- 一般操作系统的最小存储单元为页。1页大小为4K
- 查看mysql文件页大小(16K): SHOW GLOBAL STATUS LIKE ‘Innodb_page_size’;
三、非聚集索引(MyISAM)、聚集索引(InnoDB)
1、MyISAM索引实现(非聚集)
首先我们先来看一下MyISAM引擎在磁盘里是如何存在的
MyISAM索引文件和数据文件是分离的
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。如图:
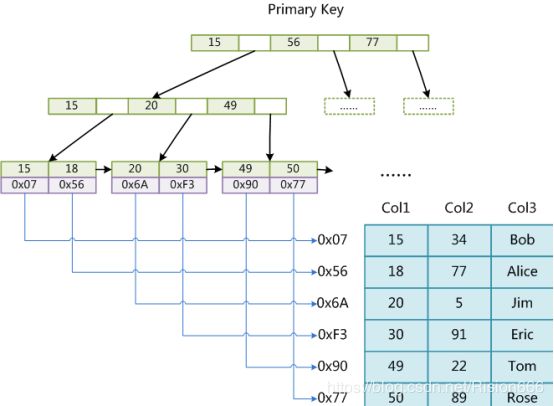
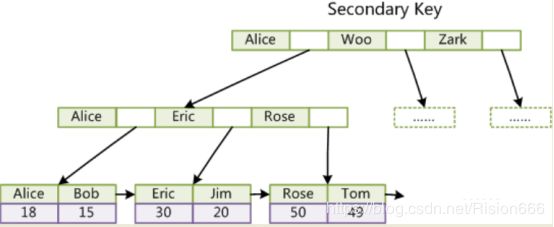
这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
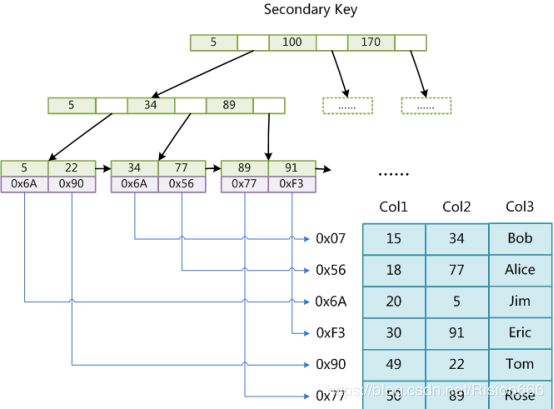
如上图,同样也是一棵B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
2、InnoDB索引实现(聚集)
- 表数据文件本身就是按B+Tree组织的一个索引结构文件
- 聚集索引-叶节点包含了完整的数据记录
- 为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
- 为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
先看一下InnoDB引擎在磁盘里是如何存在的
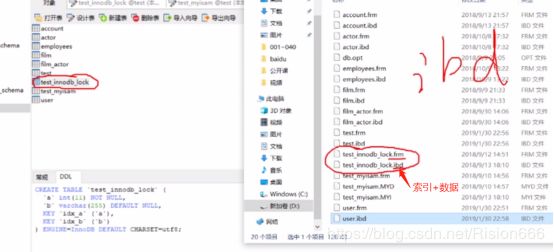
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
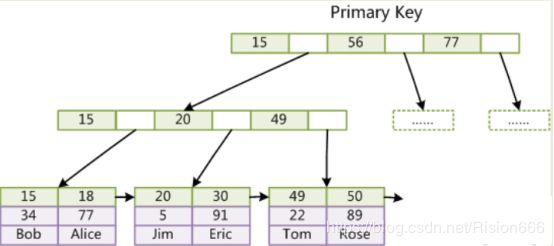
上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
四、常见问题
1、为什么mysql页文件默认16k?
假设我们一行数据大小为1k,那么一页就能存16条数据,也就是一个叶子节点能存16条数据;再看非叶子节点,假设主键ID为bigint类型,那么长度为8B,指针大小在Innodb源码中为6B,一共就是14B,那么一页里就可以存储16k/14=1170个(主键+指针)
那么一颗高度为2的B+树能存储的数据为:1170*16=18720条,一颗高度为3的B+树能存储的数据为:1170*1170*16=21902400(千万级条)
2、为什么索引结构默认使用B-Tree,而不是hash,二叉树,红黑树?
hash:虽然可以快速定位,但是没有顺序,IO复杂度高。
二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且IO代价高。
红黑树:树的高度随着数据量增加而增加,IO代价高。
3、为什么官方建议使用自增长主键作为索引?
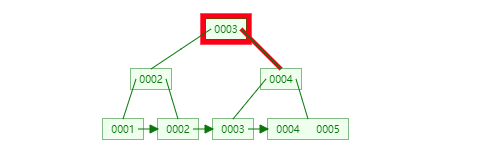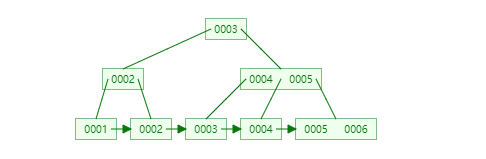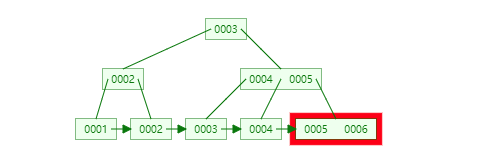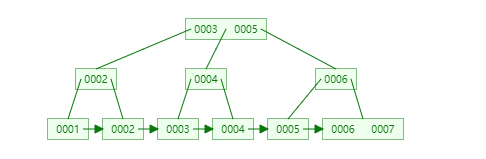
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。
插入连续的数据:
插入非连续的数据
