Oracle的内存管理
oracle数据库实例启动时,需要分配共享内存,启动后台进程。
oracle数据库使用的内存主要涉及到:PGA和SGA。
一、 PGA
Program Global Area,顾名思义是程序全局区,是服务器进程(Server Process)使用的一块包含数据和控制信息的内存区域,PGA是非共享的内存,在服务器进程启动或创建时分配,并为Server Process排他访问。
进程的创建有两方式:专用服务器模式(Dedicated Server)和共享服务器模式(Shared Server)。专用服务器模式下,Oracle为每个会话启动一个Oracle进程;在共享服务器模式下,通常在服务器端启动一定数量的服务器进程,然 后由多个客户端请求共享同一个Oracle服务进程。通常服务器运行在专用服务器模式下。
PGA的创建过程
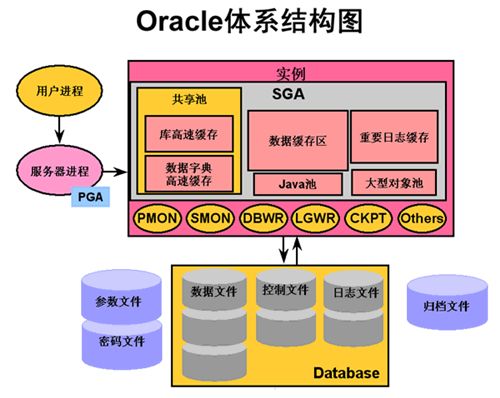
oracle的结构图
PGA创建过程:当客户端向服务器发送连接请求,服务器监听到客户端要求,在专用服务器模式下,在服务器端生成一个Serlver Process来代理用户的请求,服务器进程进而向实例发起连接,创建会话(Create Session),而PGA就为为Servler Process所分配和使用。
通常,PGA包括私有SQL区、Session信息等内容。
会话内存(Session Memory):用于存放会话的登录信息以及其他相关信息,对于共享服务器模式,这部分是共享的。
私有SQL区(Private SQL Area):包含绑定变量信息,查询执行状态信息以及查询工作区等。每个发出查询的会话都有一块私有SQL区,对于专用服务器模式,这部分内存在PGA中分配,对于共享服务器模式,这部分内存在SGA中分配。
私有SQL区又由两部分组成: 永久区域(Persistent Area):包含绑定变量等信息,这部分内存只有在游标关闭时才会被释放;运行时区域(Runtime Area),存放了SQL语句运行时所需要的信息,在执行请求时首先创建,其中包含了查询执行的状态信息、SQL Work Areas。
二、 UGA(User Global Area):用户全局区。由用户会话数据、游标状态和索引区组成。在共享服务器模式下,一个共享服务进程被多个用户进程共享,此时UGA是Shared Pool或Large Pool的一部分,而在专用服务器下,UGA则是PGA的一部分。
在Dedicatred模式下,PGA与UGA的关系,就如同Process和Session的关系,PGA是服务于进程的内存结构,包含进程信息;而UGA是服务于会话的,包含的是会话的信息。
固定UGA包括大约70个原子变量,小的数据结构以及指向UGA堆的指针。
还有一块内存区域是CGA(Call Glabal Area,调用全局区),存在是瞬间的,只存在于调用过程中,而且不论UGA存在于PGA还是SGA,CGA都是PGA的SubHeap.SQL解析、SQL优化需要用到CGA。这里不展开介绍。
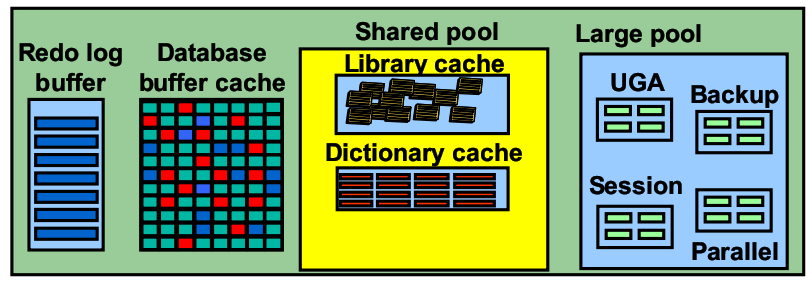
三、 SGA(System Global Area):系统全局区,用于加载数据、对象并保存运行状态和数据库控制信息的一块内存区域,在数据库实例启动时分配,当实例关闭时释放,每个实例都有自己的SGA区。
SGA的体系结构图上面的图已包括。
连接到Oracle数据库的用户都可以共享SGA中的数据,通常是为了更优化的性能,SGA设置得更高,可以减少物理I/O(SGA中数据缓冲区的增大可以有效地减少物理读取)。
组成:
1. 固定区域(Fixed Area): Fixed Area是SGA中的固定部分,包含几千个变量和一些小的数据结构,如Latch或地址指针等,这部分内存分配和特定的数据库版本以及平台有关,不受用户控制,固定部分只需要很小的内存。
2. Buffer Cache(缓冲区高速缓存):用于存储最近使用的数据块,这些数据块可能修改过,也可以未修改过。在Oracle对数据的处理中,代价最昂贵的就是物理 I/O(Physical I/O),同样的数据从内存中得到比从磁盘上读取快得多,所以将尽可能多的数据保存在内存中,可以减少磁盘I/O操作,从而提高数据库性能。
通常的数据访问和修改都需要通过Buffer Cache来完成。当一个进程需要访问数据时,首先需要确定数据是否在内存中存在 ,如果数据在Buffer中存在,则需要根据数据的状态来判断是否可以直接访问还是需要构造一致性读取;如果数据在Buffer中不存在,则需要在 Buffer Cache中寻找足够的空间以装载需要的数据,如果Buffer Cache中找不到足够的内存空间,则需要触发DBWR去写出脏数据,释放Buffer空间。
Buffer Cache使用了Hash Bucket和Cache Buffer Chain存放数据。
每个Buffer中存放的Bucket由Buffer的数据块地址(Data Block Address)运算决定。在Bucket内部,通过Cache Buffer Chain(双向链表)将所有的Buffer通过Buffer Header信息联系起来。Buffer Header存放的是对应数据块的概要信息,包括数据块的文件号、块地址、状态等。判断数据块是否在Buffer中存在,通过检查Buffer header即可确定。
3. Shared Pool(共享池),包含共享内存结构,如SQL区等。SQL区包含SQL解析树、执行计划等信息,通过共享池,反复执行的SQL可以在不同Session间得到共享。
Shared Pool是Oracle SGA中设置最复杂也是最重要的一环,Shared Pool可实现SQL共享、减少代码硬解析等,提高数据库的性能。
Oracle引入Shared Pool是为了帮助我们实现代码的共享和重用。
组成:
库缓存(Library Cache):主要存储SQL语句、SQL语句解析树、执行计划、PL/SQL程序块以及它们转换后能够被Oracle执行的代码等;
数据字典缓存(Data Dictionary Cache): 主要存放数据字典信息,包括表、视图等对象的结构信息,用户以及对象权限等信息,这部分信息相对稳定。
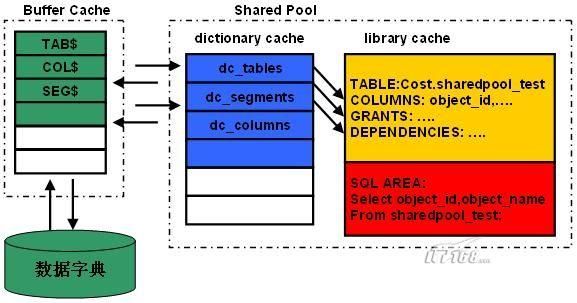
shared pool与buffer cache的协同工作
除上述两部分,从Oracel 11g开始,在Shared Pool中划出了另外一块内存用于存储SQL查询的结果集,称为Result Cache Memory(结果集缓存)。以前的Shared Pool的主要功能是共享SQL,减少硬解析,从而提高性能,但SQL共享以后,执行查询同样可以消耗大量的时间和资源,现在Oracle尝试将查询的结 果集缓存,可以将缓存的查询结果返回给用户,不需要真正去执行运算,为性能带来了极大的提升。
4. Redo Log Buffer-日志缓冲区存储重做日志条目,日志记录数据库变更,最终将被写出到重做日志文件中,在数据库崩溃或故障时用于恢复。
5. Java Pool:用于JVM等Java选件。
内存分配Oracle的建议是:Oracle最多可以使用80%的物理内存,其余20%内存给操作系统使用。