java:Cassandra入门与实战——下
六、JAVA户端操作Cassandra
在第五章,我们使用Cassandra的命令操作Cassandra数据库,本章我们介绍使用JAVA客户端连接Cassandra,操作数据
6.1 JAVA客户端介绍
Cassandra有众多的JAVA客户端,目前比较流程的都是不同公司开源的客户端,如:Netfix的astyanax,datastax的java-driver,hector,以及Spring Data for Apache Cassandra。
在github中搜索cassandra,可以看都响应JAVA客户端的受欢迎程度。

6.2 datastax的java-driver
6.2.1 介绍
是由DataStax公司,开源的用来操作Cassandra的工具包,官网:
https://docs.datastax.com/en/landing_page/doc/landing_page/current.html
在github的搜索页面点击 datastax/java-driver
源码地址:
https://github.com/datastax/java-driver
在页面上可以看到使用java-driver的简单介绍,包含Maven依赖内容,环境兼容要求。
可以看到需要jdk8或更版本,支持Cassandra2.1获取更高版本

6.2.2 创建Maven工程引入依赖
cassandra-demo
com.itheima
1.0-SNAPSHOT
4.0.0
datastax-demo
com.datastax.cassandra
cassandra-driver-core
3.9.0
com.datastax.cassandra
cassandra-driver-mapping
3.9.0
junit
junit
4.12
6.2.3 操作键空间
package com.itheima.test;
import com.datastax.oss.driver.api.core.CqlIdentifier;
import com.datastax.oss.driver.api.core.CqlSession;
import com.datastax.oss.driver.api.core.cql.SimpleStatement;
import com.datastax.oss.driver.api.querybuilder.SchemaBuilder;
import com.datastax.oss.driver.api.querybuilder.schema.Drop;
import org.junit.Before;
import org.junit.Test;
import java.net.InetAddress;
import java.net.InetSocketAddress;
import java.net.UnknownHostException;
import java.util.Optional;
/**
* 测试对Keyspace的操作
*/
public class TestKeySpace {
CqlSession session = null;
@Before
public void init(){
//Cassandra服务器地址
String hosts = "192.168.137.131";
//端口
int port = 9042;
try {
session = CqlSession.builder().withLocalDatacenter("datacenter1").build();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 查询 键空间
*/
@Test
public void findKeySpace(){
Optional keyspace = session.getKeyspace();
if(keyspace.isPresent()){
CqlIdentifier cqlIdentifier = keyspace.get();
System.out.println("键空间名:"+cqlIdentifier.asInternal());
}
}
/**
* 创建键空间
*/
@Test
public void createKeySpace(){
SimpleStatement simpleStatement = SchemaBuilder.
createKeyspace("school").
ifNotExists().
withSimpleStrategy(1).
build();
session.execute(simpleStatement);
}
/**
* 删除键空间
*/
@Test
public void dropKeySpace(){
SimpleStatement state = SchemaBuilder.dropKeyspace("school").ifExists().build();
session.execute(state);
}
} 6.2.4 操作表
package com.itheima.test;
import com.datastax.driver.core.*;
import com.datastax.driver.core.schemabuilder.SchemaBuilder;
import com.datastax.driver.mapping.Mapper;
import com.datastax.driver.mapping.MappingManager;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.itheima.entity.Student;
import org.junit.Before;
import org.junit.Test;
import java.net.InetAddress;
import java.net.InetSocketAddress;
import java.net.UnknownHostException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import static com.datastax.driver.core.querybuilder.QueryBuilder.eq;
import static com.datastax.driver.core.querybuilder.QueryBuilder.select;
/**
* 测试datastax
*/
public class TestTable {
Session session = null;
Mapper mapper;
/**
* 初始化
*/
@Before
public void init() {
//Cassandra服务器地址
String hosts = "192.168.137.131";
//端口
int port = 9042;
Cluster cluster = Cluster.builder().
addContactPoint(hosts).
withPort(port).
build();
session = cluster.connect();
}
/**
* 创建表
*/
@Test
public void createTable() {
Statement statement = SchemaBuilder.
createTable("school", "student").
addPartitionKey("id", DataType.bigint()).
addColumn("address", DataType.text()).
addColumn("age", DataType.cint()).
addColumn("education", DataType.map(DataType.text(), DataType.text())).
// addColumn("email", DataType.text()).
addColumn("gender", DataType.cint()).
addColumn("interest", DataType.set(DataType.text())).
addColumn("phone", DataType.list(DataType.text())).
addColumn("name", DataType.text()).
ifNotExists();
ResultSet resultSet = session.execute(statement);
System.out.println(resultSet.getExecutionInfo());
}
/**
* 修改表
*/
@Test
public void updateTable(){
// 添加字段
SchemaBuilder.alterTable("school","student")
.addColumn("email").type(DataType.text());
// 修改字段
SchemaBuilder.alterTable("school","student")
.alterColumn("email").type(DataType.set(DataType.text()));
// 删除字段
SchemaBuilder.alterTable("school","student")
.dropColumn("email");
}
/**
* 删除表
*/
@Test
public void dropTable(){
Statement statement = SchemaBuilder.dropTable("school","student").ifExists();
session.execute(statement);
}
/**
* 添加数据
* 使用CQL
*/
@Test
public void insertByCQL() {
String insertSql = "INSERT INTO school.student (id,address,age,gender,name,interest, phone,education) VALUES (1011,'中山路21号',16,1,'李小仙',{'游泳', '跑步'},['010-88888888','13888888888'],{'小学' : '城市第一小学', '中学' : '城市第一中学'}) ;";
session.execute(insertSql);
}
/**
* 添加数据
* 使用Mapper和Bean对象
*/
@Test
public void insertByMapper() {
mapper = new MappingManager(session).mapper(Student.class);
HashMap education = new HashMap<>();
education.put("小学", "中心第五小学");
education.put("中学", "中心实验中学");
HashSet interest = new HashSet<>();
interest.add("看书");
interest.add("电影");
List phones = new ArrayList<>();
phones.add("020-66666666");
phones.add("13666666666");
// 构造student
Student student = new Student(
1012L,
"北京市朝阳区100号",
20,
education,
"[email protected]",
1,
interest,
phones,
"马小帅");
// 数据保存到cassandra服务器
mapper.save(student);
}
/**
* 查询所有数据
*/
@Test
public void queryAll(){
mapper = new MappingManager(session).mapper(Student.class);
ResultSet resultSet = session.execute(select().all().from("school","student"));
List studentList = mapper.map(resultSet).all();
for (Student student : studentList) {
System.out.println(student);
}
}
/**
* 查询一条数据
*/
@Test
public void queryOne(){
mapper = new MappingManager(session).mapper(Student.class);
ResultSet resultSet = session.execute(select().all().from("school","student"));
Student student = mapper.map(resultSet).one();
System.out.println(student);
}
/**
* 根据id 查询
*/
@Test
public void queryById(){
mapper = new MappingManager(session).mapper(Student.class);
ResultSet resultSet = session.execute(select().all().from("school", "student").where(eq("id", 1012L)));
List studentList = mapper.map(resultSet).all();
for (Student student : studentList) {
System.out.println(student);
}
}
/**
* 删除
*/
@Test
public void delete() {
mapper = new MappingManager(session).mapper(Student.class);
Long id = 1011L;
mapper.delete(id);
}
} 6.2.5 Prepared statements
cassandra提供了类似jdbcpreparedstatement使用预编译占位符。官方文档链接如下:
https://docs.datastax.com/en/developer/java-driver/3.0/manual/statements/prepared/
官方文档原理图:
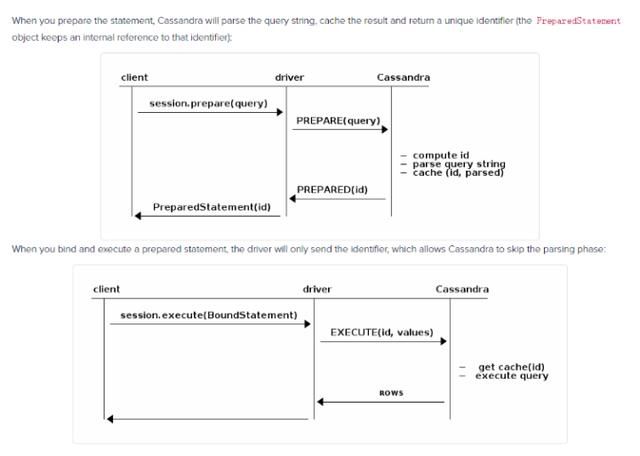
基本原理:
预编译statement的时候,Cassandra会解析query语句,缓存解析的结果并返回一个唯一的标志。当绑定并且执行预编译statement的时候,驱动只会发送这个标志,那么Cassandra就会跳过解析query语句的过程。 应保证query语句只应该被预编译一次,缓存PreparedStatement 到我们的应用中(PreparedStatement 是线程安全的);如果我们对同一个query语句预编译了多次,那么驱动输出印警告日志; 如果一个query语句只执行一次,那么预编译不会提供性能上的提高,反而会降低性能,因为是两次请求,那么此时可以考虑用 simple statement 来代替
代码:
/**
* 批量写入操作
*
*/
@Test
public void batchPrepare(){
// 先把语句预编译
BatchStatement batch = new BatchStatement();
PreparedStatement ps = session .prepare("INSERT INTO school.student (id,address,age,gender,name,interest, phone,education) VALUES (?,?,?,?,?,?,?,?)");
// 循环10次,构造不同的student对象
for (int i = 0; i < 10; i++) {
HashMap education = new HashMap<>();
education.put("小学", "中心第"+i+"小学");
education.put("中学", "第"+i+"中学");
HashSet interest = new HashSet<>();
interest.add("看书");
interest.add("电影");
List phones = new ArrayList<>();
phones.add("0"+i+"0-66666666");
phones.add("1"+i+"666666666");
// 构造student
Student student = new Student(
1013L+i,
"北京市朝阳区10"+i+"号",
21+i,
education,
"[email protected]",
1,
interest,
phones,
"学生"+i);
BoundStatement bs = ps.bind(student.getId(),
student.getAddress(),
student.getAge(),
student.getGender(),
student.getName(),
student.getInterest(),
student.getPhone(),
student.getEducation());
batch.add(bs);
}
session.execute(batch);
batch.clear();
} 6.3 Spring Data Cassandra
6.3.1 介绍
官网:
https://spring.io/projects/spring-data-cassandra
官网对相关环境的要求:
Spring Data for Apache Cassandra 2.x binaries require JDK level 8.0 and later and Spring Framework 5.2.7.RELEASE and later. It requires Cassandra 2.0 or later.
6.3.2 创建Maven工程
引入依赖
cassandra-demo
com.itheima
1.0-SNAPSHOT
4.0.0
springCassandra-demo
org.springframework.data
spring-data-cassandra
2.2.8.RELEASE
junit
junit
4.12
创建配置文件
cassandra.properties
cassandra.contactpoints=192.168.137.131
cassandra.port=9042
cassandra.keyspace=schoolspringContext.xml 配置文件
6.3.3 编写代码
创建实体类 Student.java
package com.itheima.springcass.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.cassandra.core.mapping.PrimaryKey;
import org.springframework.data.cassandra.core.mapping.Table;
import java.util.List;
import java.util.Map;
import java.util.Set;
@Data
@Table
@AllArgsConstructor
@NoArgsConstructor
public class Student {
@PrimaryKey
private Long id;
private String address;
private Integer age;
private Map education;
private String email ;
private Integer gender;
private Set interest;
private List phone ;
private String name;
} 创建StudentRepository.java
package com.itheima.springcass.repository;
import com.itheima.springcass.entity.Student;
import org.springframework.data.cassandra.repository.CassandraRepository;
/**
* 持久层
*/
public interface StudentRepository extends CassandraRepository {
} 创建service
package com.itheima.springcass.service;
import com.itheima.springcass.entity.Student;
import com.itheima.springcass.repository.StudentRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
/**
* student的操作
*/
@Service
public class StudentService {
/**
* 注入持久层
*/
@Autowired
private StudentRepository repository;
/**
* 查询所有信息
* @return
*/
public List queryAllStudent(){
List studentList = repository.findAll();
return studentList;
}
/**
* 根据id 查询一条信息
* @param id
* @return
*/
public Student queryOneStudent(Long id){
return repository.findById(id).get();
}
/**
* 保存数据
*/
public void saveStudent(Student student){
repository.save(student);
}
/**
* 修改数据
*/
public void updateStudent(){
Student student = this.queryOneStudent(1019L);
student.setGender(0);
repository.save(student);
}
/**
* 删除数据
*/
public void deleteStudent(Long id){
repository.deleteById(id);
}
} 创建测试代码
package com.itheima.springcass.test;
import com.itheima.springcass.entity.Student;
import com.itheima.springcass.service.StudentService;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.context.ConfigurableApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import java.net.InetSocketAddress;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
public class TestSpringCassandra {
private StudentService studentService;
@Before
public void init(){
ConfigurableApplicationContext context = new ClassPathXmlApplicationContext("springContext.xml");
studentService = (StudentService)context.getBean("studentService");
}
/**
* 查询所有
*/
@Test
public void testQueryAll(){
List students = studentService.queryAllStudent();
for (Student student : students) {
System.out.println(student);
System.out.println("=============");
}
}
@Test
public void testOne(){
Student student = studentService.queryOneStudent(1018L);
System.out.println(student);
}
@Test
public void insert(){
HashMap education = new HashMap<>();
education.put("小学", "中心第五小学");
education.put("中学", "中心实验中学");
HashSet interest = new HashSet<>();
interest.add("看书");
interest.add("电影");
List phones = new ArrayList<>();
phones.add("130-66666666");
phones.add("15766666666");
// 构造student
Student student = new Student(
1028L,
"北京市朝阳区800号",
30,
education,
"[email protected]",
0,
interest,
phones,
"小小咸");
studentService.saveStudent(student);
}
@Test
public void delete(){
studentService.deleteStudent(1028L);
}
} 七、Cassandra集群搭建
7.1 准备
采用3台CentOS x64系统(虚拟机)
为每台虚拟机设置静态IP
- 192.168.137.131 (seed)
- 192.168.137.132 (seed)
- 192.168.137.133
选择 131,、132两台机器作为集群的种子节点(seed)。种子节点的作用:
一个新节点加入集群时,需要通过种子节点来发现集群中其它节点,需要至少一个活跃的种子节点可以连接,一旦节点加入这个集群,知道了集群中的其它节点,这个节点在下次启动的时候就不需要种子节点了。 对于种子节点没有特殊要求,可以设置任何一个节点为种子。
7.2 改配置
需要在每台机器的配置文件cassandra.yml中进行一些修改,包括
cluster_name 集群名字,每个节点都要一样
seeds 填写2个节点的ip作为 种子节点,每个节点的内容都要一样
listen_address 填写当前节点所在机器的IP地址
rpc_address 填写当前节点所在机器的IP地址
具体修改如下:
192.168.137.131 机器修改的内容:
cluster_name: 'Test Cluster'
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "192.168.137.131,192.168.137.132"
listen_address: 192.168.137.131
rpc_address: 192.168.137.131192.168.137.132 机器的修改内容
cluster_name: 'Test Cluster'
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "192.168.137.131,192.168.137.132"
listen_address: 192.168.137.132
rpc_address: 192.168.137.132192.168.137.133 机器的修改内容
cluster_name: 'Test Cluster'
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "192.168.137.131,192.168.137.132"
listen_address: 192.168.137.133
rpc_address: 192.168.137.133修改完成后,启动每个节点。可以在192.168.137.131机器上使用noodtools status 命令进行测试
八、Cassandra的数据存储
Cassandra的数据包括在内存中的和磁盘中的数据
这些数据主要分为三种: CommitLog:主要记录客户端提交过来的数据以及操作。这种数据被持久化到磁盘中,方便数据没有被持久化到磁盘时可以用来恢复。 Memtable:用户写的数据在内存中的形式,它的对象结构在后面详细介绍。其实还有另外一种形式是BinaryMemtable 这个格式目前 Cassandra 并没有使用,这里不再介绍了。 SSTable:数据被持久化到磁盘,这又分为 Data、Index 和 Filter 三种数据格式。
8.1 CommitLog 数据格式
Cassandra在写数据之前,需要先记录日志,保证Cassandra在任何情况下宕机都不会丢失数据,这就是CommitLog日志。要写入的数据按照一定格式组成 byte 组数,写到 IO 缓冲区中定时的被刷到磁盘中持久化。Commitlog是server级别的。每个Commitlog文件的大小是固定的,称之为一个CommitlogSegment。
当一个Commitlog文件写满以后,会新建一个的文件。当旧的Commitlog文件不再需要时,会自动清除。
8.2 Memtable 内存中数据结构
数据写入的第二个阶段,MemTable是一种内存结构,当数据量达到块大小时,将批量flush到磁盘上,存储为SSTable。优势在于将随机IO写变成顺序IO写,降低大量的写操作对于存储系统的压力。每一个columnfamily对应一个memtable。也就是每一张表对应一个。用户写的数据在内存中的形式,
8.3 SSTable 数据格式
SSTable是Read Only的,且一般情况下,一个ColumnFamily会对应多个SSTable,当用户检索数据时,Cassandra使用了Bloom Filter,即通过多个hash函数将key映射到一个位图中,来快速判断这个key属于哪个SSTable。
为了减少大量SSTable带来的开销,Cassandra会定期进行compaction,简单的说,compaction就是将同一个ColumnFamily的多个SSTable合并成一个SSTable。
在Cassandra中,compaction主要完成的任务是:
1) 垃圾回收: cassandra并不直接删除数据,因此磁盘空间会消耗得越来越多,compaction 会把标记未删除的数据真正删除;
2) 合并SSTable:compaction 将多个 SSTable 合并为一个(合并的文件包括索引文件,数据文件,bloom filter文件),以提高读操作的效率;
3) 生成 MerkleTree:在合并的过程中会生成关于这个ColumnFamily中数据的 MerkleTree,用于与其他存储节点对比以及修复数据。
九、Cassandra的重要知识点
Cassandra的集群中每一台机器都是对等的,不存在主、从节点的区分,集群中任何一台机器出现故障是,整个集群系统不会受到影响。
一致哈希
一致性哈希是Cassandra搭建集群的基础,一致性哈希可以降低分布式系统中,数据重新分布的影响。
在Cassandra中,每个表有Primary Key外,还有一个叫做Partition Key,Partition Key列的Value会通过Cassandra一致性算法得出一个哈希值,这个哈希值将决定这行数据该放到哪个节点上。
每个节点拥有一段数字区间,这个区间的含义是:如果某行记录的Partition Key的哈希值落在这个区间范围之内,那么该行记录就该被存储到这个节点上。
如果简单的使用哈希值,可能会引起数据分布不均匀的问题,为了解决这个问题,一致性哈希提出虚拟节点的概念,简单的理解就是:将某个节点根据一个映射算法,映射出若干个虚拟子节点出来,再把这些节点分布在哈希环上面,保存数据时,如果通过一致性哈希计算落到某个虚拟子节点上,这条记录就会被存在这个虚拟子节点的母节点上。
Token:在Cassandra,每个节点都对应一个token,相当于hash环中的一个节点地址。在Cassandra的配置文件中有一项配置叫做:num_tokens,这个配置项可以控制一个节点映射出来的虚拟节点的个数。
Range:在Cassandra中,每一个节点负责处理hash环的一段数据,范围是从上一个节点的Token到本节点Token,这就是Range
在健康的集群中,可以通过自带的工具nodetool查看集群的哈希环具体情况,命令为:nodetool ring。
这里我们使用cassandra官方文档中一张图来说明

Gossip内部通信协议
Cassandra使用Gossip的协议维护集群的状态,这是个端对端的通信协议。通过Gossip,每个节点都能知道集群中包含哪些节点,以及这些节点的状态,
Gossip进程每秒运行一次,与最多3个其他节点交换信息,这样所有节点可很快了解集群中的其他节点信息。