Beam从零开始(一)
网上看了别人都在谈Beam,你说咱们作为技术人员技术也得紧跟着时代不是,所以也开始利用业余时间研究Beam。咱不是大神,不能啥都一看就会,所以一天一天来,这个也就作为笔记吧。废话不多说,进入主题,按照老规矩,从官网入手。
其实Beam官网目前做的不是很丰满,不过好在按照步骤进行,可以接受。
Beam是什么呢?英文中Beam是光束的意思,官方对Beam的解释是:Apache Beam是一个开源的统一的编程模型(记住,他是个模型而已),我们可以使用它来创建数据处理管道(核心是管道)。我们首先要定义一个程序,使用开源的BeamSDK来定义管道。然后管道由Beam支持的分布式处理后端之一执行:Apache Apex,Apache Flink,Apache Spark,Google Cloud Dataflow。
Beam对于尴尬并行数据处理任务特别有用,其中问题可以被分解为可以独立和并行处理的许多较小的数据束。我们同样可以使用Beam来提取,变换和加载(ETL)任务和纯数据集成。这些任务对于不同存储介质和数据源之间移动数据,将数据转化成理想格式,或将数据加载到新的系统上有很大的好处。
Beam管道运行器将我们定义的处理管道和程序转化为与我们选择的分布式处理后端兼容的API。当我们运行Beam程序的时候,我们需要为执行管道的后端指定适当的运行器(Runner)。
好了,上面就是简短的理论基础,下面开始我们经典的wordcount环节。不过我打算绕过官方的QuickStart环节,因为这个真的没啥意思,我们直接自己手动创建项目然后开始学习。
我们从Minimal WordCount开始说起,下面我简称:MW。MW演示了一个可以从文本中读取的管道。应用转换来对单词进行标记和计数,并将结果写入到输出文件中。下面是详细步骤:
首先我们创建一个maven项目,如图:
然后在pom文件中加入我们的依赖:
<dependency> <groupId>org.apache.beamgroupId> <artifactId>beam-sdks-java-coreartifactId> <version>0.4.0version> dependency>
接着创建我们的第一个类:Day01,然后在其中创建main方法,那么到此我们的准备工作完毕。下面开始编写代码:
Creating the Pipeline
创建Beam管道的第一步是创建一个PipelineOptions对象,这个对象让我们对我们的管道设置各种选项,例如将要执行我们管道的管道线程以及所选择的线程所需的任何指定配置。我们可以为我们的Pipeline指定一个Runner。比如DataflowRunner或者SparkRunner。当我们不指定的时候,将会默认调用本地的DirectRunner。这里我跟官网不同,我使用最为简单的本地读取。
所以我可以直接创建Pipeline对象:
PipelineOptions pipe = PipelineOptionsFactory.create(); // 当我们不指定的时候,会默认使用DirectRunner这种类型 // pipe.setRunner(DirectRunner.class); Pipeline p = Pipeline.create(pipe);
【注意】如果这里直接运行会报错,说本地找不到DirectRunner类(能导入的那个不是我们需要的),因为缺少依赖,在pom中增加:
<dependency> <groupId>org.apache.beamgroupId> <artifactId>beam-runners-direct-javaartifactId> <version>0.4.0version> dependency>
就可以成功解决问题。创建了管道,我们就可以对管道进行转化了。
每个转换采取某种输入,然后产生一些输出数据。输入和输出数据被SDK类:PCollection所表示。PCollection是一个特殊的类,他由Beam的SDK提供,我们可以用来代表几乎任何大小的数据集。流程图如下:
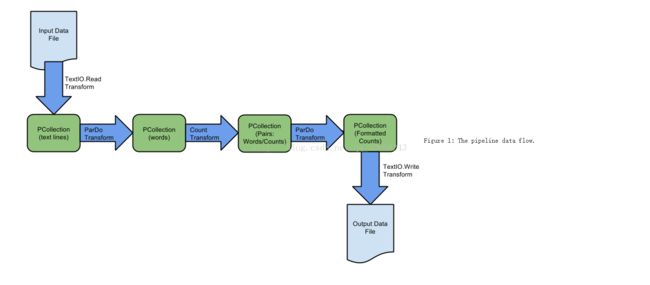
文本文件读取操作被用于Pipeline本身,他生成PCollection作为输出,输出PCollection中的每个元素表示输入文件中的一行文本。那么我们首先创建一个文件:
demo.txt为我们新创建的文件,里面内容:
tom cat hello
然后我们开始进行读取:
p.apply(TextIO.Read.from("D:\\JavaProject\\Beam_Demo\\src\\main\\resources\\demo.txt"))
读取完毕我们需要对内容进行处理,在每个元素上调用DoFn方法的ParDo转换,将文本行标记为单个单词,该文本的输入是由前一个TextIO.Read转换生成的文本行的PCollection。ParDo同样转换输出为新的PCollection,其中每个元素表示文本中的单个词:
.apply("ExtractWords", ParDo.of(new DoFn<String, String>() { @ProcessElement public void processElement(ProcessContext c) { for (String word : c.element().split(" ")) { if (!word.isEmpty()) { c.output(word); } } } }))
接下来我们需要对每个单词进行统计,SDK提供的count变换是一种通用的转换,它采用任何类型的PCollection,并返回key/value类型的PCollection。每个key表示来自于集合的唯一元素,每个value表示key出现的总次数。
.apply(Count.<String>perElement())
下面的转换将唯一word和出现次数的每个key/value对格式化为适用于写入输出文件的可打印字符串。MapElements是一个更高级别的复合变换,它封装了一个简单的ParDo。对于PCollection中的每个元素,MapElements应用只产生一个元素的函数。在本例中,MapElements调用执行格式化的simpleFunction(匿名内部类),作为输入,
MapElements获得由count生成的key/value对的PCollection。并产生可打印字符串的新PCollection。
.apply("FormatResult", MapElements.via(new SimpleFunction<KV<String, Long>, String>() { @Override public String apply(KV<String, Long> input) { return input.getKey() + ": " + input.getValue(); } })).apply(TextIO.Write.to("D:\\JavaProject\\Beam_Demo\\src\\main\\resources\\wordcounts"));
然后我们开始运行:
p.run().waitUntilFinish();
运行后我们得到结果:
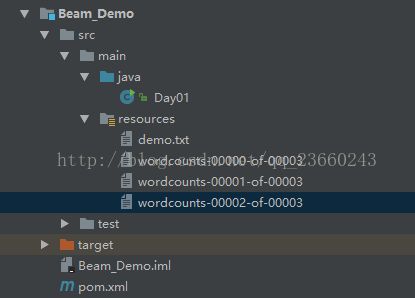
每个里面是word的统计结果,应该是hash分区,所以出现三个文件:
tom: 1
hello: 1
cat: 1
那么计算结束,这里仅仅是一个简单的入门,后面还会继续深入。
感谢开源。