Kaldi-MFCC模块源码主流程分析
那么趁着这个机会,研究一下kaldi源码中MFCC部分的内容。不说废话,我们从 compute-mfcc-feats.cc开始讲解,这里是个main函数,需要携带参数,具体使用样例如下:
1.compute-mfcc-feats:
![]()
其实看到这里我是一脸懵逼的,并不知道该如何用,没办法硬着头皮往下看。
![]()
这句看起来好似定义了一个类,要想知道它到底在干什么,我们找到ParseOptions中。【这里注意一下,关于这些子类,我不做细节介绍,只做整体查看,不然细节太多,文章篇幅会很大。】ParseOptions如下:

看这个类应该对命令有关的操作,所以我理解ParseOptions仅仅是对用户输入的命令进行各种执行转化显示解析等操作,不做细节讲解,泛化概念上先如此理解。
我们接着往下看:
![]()
这是个结构体,比较重要。先整体看一下结构体的组成:

这个结构体定义了MFCC使用到的一些参数,并对其进行了初始化操作。这里又涉及到一个MelBanksOptions,具体如下:

他是对梅尔滤波器组进行操作所需的参数和方法的结构体。关于这里的Register函数,我个人认为是类似于某种map映射类型的操作,保存变量的值,具体理解是否正确后面会再次说明。
下面主要是一些变量的声明,群体贴出来。不具体讲每个变量的意义,很大一部分我都不知道干什么的,不过不影响我们继续往下看。

接下来定义了一个Mfcc:
![]()
不过Mfcc只不过是一个宏定义,其真实类型是OfflineFeatureTpl,其定义如下:

再展开一层:

从注释和名字来看我们可以知道,该类主要处理“离线”数据的特征提取。也就是说,在提取特征之前,你可以获取信号的始终。其存在主要是为了直接替换旧版的Mfcc类,Plp等。
回到Mfcc,现在可以看出来,我们的mfcc准备完毕。
接下来如下:
![]()
光从名字猜测可能与读取音频文件有关,那我们展开来看:

从注释来看,其主要功能就是从文件中读取对象。那么假如我要读取wav格式的数据,理应用wav结构的object去接。那么我们查看一下WaveHolder类:

这里面仅仅封装了一些方法而已,简化我们写出读入等等,并没有找到我想看的结构体,继续查看WaveData:
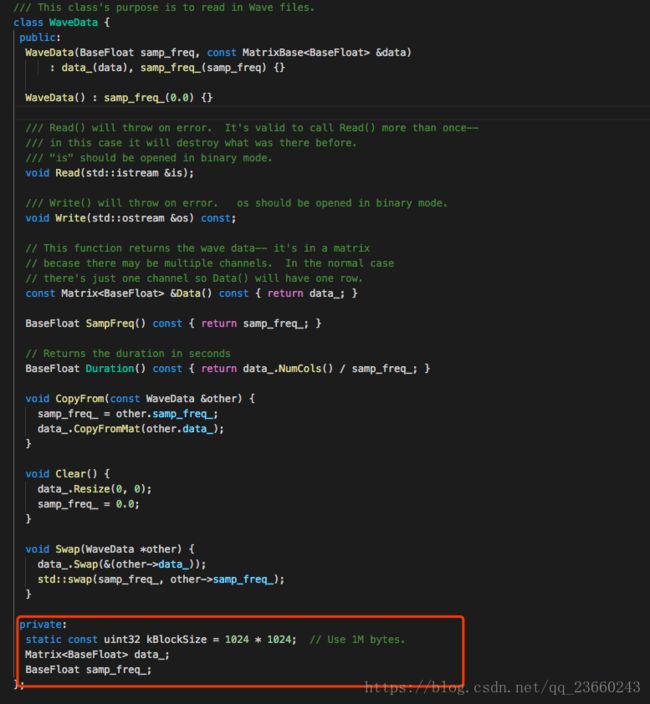
我们看WaveData的私有成员变量,发现仅仅如上面三个。那么我这里私自认为该WaveHolder仅仅把wav文件的data部分和采样率sample_frequency读取出来,其余并没有保存。至于具体细节如何实现的,我这里不深入。
我们返回到compute-mfcc-feats.cc中,继续下两行:
![]()
看名称我猜测与把文件写出有关,不过有人可能会问为什么有两个?这里分析一下:这里变量名称前缀分别为kaldi和htk,学过语音的一定都或多或少的了解htk(kaldi更不用说),即使没了解过也一定听过。所以这里的两种writer很有可能对应两种不同的开源ASR,写出的文件能用在不同的平台上。不过也会有人问,既然这个是kaldi的源码 ,为什么还要考虑htk。我是这么说服我自己的:MFCC部分并非仅属于kaldi,他独立性较大,换句话说它可以完全从kaldi中剥离出来(也许后面我会这么做),所以提供多个平台对接是可以说的通的。由于我们讲kaldi的,所以我们只看BaseFloatMatrixWriter:
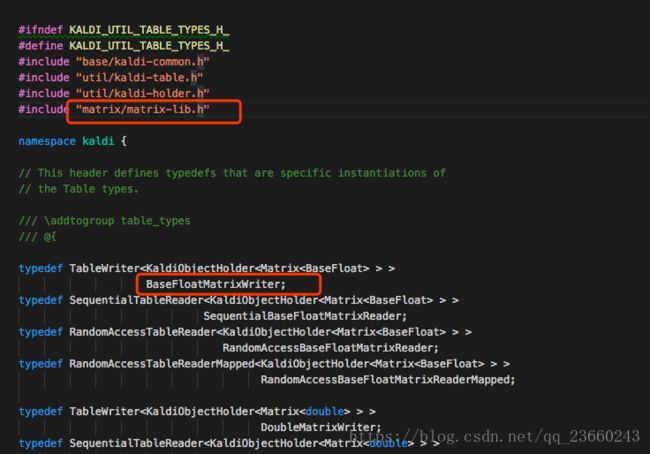
从这里看来,其实BaseFloatMatrixWriter也是TableWriter,只不过里面定义的泛型不同。此处是KaldiObjectHolder,那么我们看一下里面究竟有些什么:

从这里可以看出来,此类主要也是对二进制流进行处理的封装类,猜测与htk部分有出入,所以单独拿出来,细节不讲,我们继续,返回到compute-mfcc-feats.cc中(跳过判断):
![]()
这个靠名字很难猜测具体在做什么,也不知道谁和谁映射?为什么映射?怎么映射?我们进入定义:
![]()
同样是一个宏定义,真实类型是RandomAccessTableReaderMapped,不知道具体功能,进入定义查看:

根据注释和名字我的猜测是:当你随机的读取某个文件的时候,你面临这样一个问题:你只有每个spk对应的utt,不过文件却是按照spk来储存的。这就需要一个关于spk和utt相互映射的功能,并且随机读取出来。所以:映射+随机读取就是此函数的功能,五个准备阶段的文件中,utt2spk应该就是为此阶段的函数做准备的,大家可以看compute-mfcc-feats.cc中调用此函数的第二个参数:utt2spk_rspecifier,指的应该就是utt2spk文件【脚本处传的参数比较乱,时间原因我不做考究】。回到compute-mfcc-feats.cc中:

这里是对输出格式验证,没有太多可以说的。我们继续:

下面是一个超长的for循环,所以这里我先折叠一下,看一下流程,循环的条件应该就是我们持续读入的wav音频文件,直至读完位置。那么看一下代码对音频文件做了什么,我们一段一段的过:

首先上来是一个计数,然后读入键值utt,然后根据键值读入数据wav_data。接下来有个判断,如果文件持续时间太小,换言之文件太短,我们报错不进行处理,并给出错误信息。继续:

对声道进行检查,看定义的是否与原始数据有出入,如果有跳出并显示错误。继续:

目前暂时不理解vtln_warp_local(其实是一个扭曲因子)的实际用处,不过此处同样是检查,同时幅值vtln_warp_local供后面使用,具体用处后面指出。继续:

我们不看细节,整体上可以看到我们把数据取出放入子向量中(感觉这里那么像分帧的操作)。然后把子向量作为参数执行mfcc.ComputeFeatures,注意,重点来着,我认为这个ComputeFeatures就是计算MFCC的核心算法,必须要看。在进入之前,我们先看一下传入的各个参数:有数据,有采样率,vtln_warp_local扭曲因子(http://www.kaldi-asr.org/doc/feat.html),最后一个应该是返回值的存放引用。那么我们逐层追踪代码,首先Mfcc是OfflineFeatureTpl

我们发现里面有两个ComputeFeatures,下面的注释中写了会调用上面的non-const到一个暂时的通过拷贝形成的对象中,具体为什么创造它我们不管,我们只关注上面的方法。可以肯定,参数与我们之前的推断是一致的。那么继续看实现:
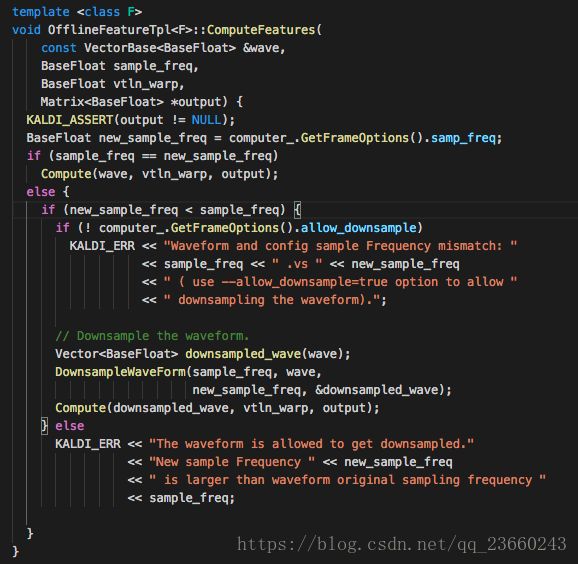
我们依次往下看,程序分别在做:检查输出是否为空指针,获取采样率,随后检查wav采样率和配置的采样率是否一致,如果一致执行Compute操作(那么这个Compute就是MFCC的核心算法了),如果不一致执行下采样之后再做Compute(你可能会问为什么不执行上采样,要加个else,去翻翻采样率,看看从低频往高频采样会有什么后果)。那么不做采样率的深入,直接查看Compute函数:

首先同样进行了输出的引用判断是否为空指针,然后获取帧数和维数(想像成一个矩阵的行和列把)。如果帧数为0,那么结果置0直接跳出(废话,啥都不给我让我给你啥)。如果帧数ok,那么对输出output进行“行和列”的定义。同时定义了一个窗函数,然后定一个标志变量,看是否使用对数的能量表示(类似于log||X||^2)。然后进入for循环开始遍历每帧,下面这个ExtractWindow我有些看不懂,进入一下看他在干什么:

很长,我不全贴出来,不过看注释就大概理解了其所做的内容。他返回的是已经加窗,消除直流分量,预加重并且经过二次方的帧。可以理解为信号的预处理阶段在这里完成,不做具体深入,回到Compute中,继续。
我们定义一个存放返回值的变量:output_row,然后调用Compute函数(汗,这封装的有点深呀),接下来我们继续查看Compute函数:

能走到这里不容易,东西很多,尽量直讲大纲。
上来首先对参数进行检验。然后定义了mel滤波器组(不进入细节),然后查看是否使用srfft(我就理解为一种特别的快速傅立叶变换方式,具体不深入),如果使用的话我们就执行Compute操作。那么这个Compute我猜测是用来进行fft变换的,进入查看一下:

查看注释可以发现,此算法既包括傅立叶变换也包括逆傅立叶变换,取决于后面的标志位,前面的实数的形式也会变化。具体实现不看,回到上面MfccCompute::Compute中,如果我们不适用srfft,那么会使用另外一种fft方式进行替换(此种方式主要针对非能量表示的信号,也就是非||X||^2),具体不看。那么现在已经得到频域表示的信号了。接下来调用了:ComputePowerSpectrum函数,此算法是求信号的功率谱密度(通常理解为相关函数的傅立叶变换,细节不进入)。
接下来把功率谱密度保存在一个新的向量种,同时只去了每帧长度/2+1。(因为傅立叶变换后是共轭对称的)接下来使用mel滤波器组进行过滤,也就是:mel_banks.Compute(不查看细节,这次主要目的是把主流程捋清楚)。
接下来是应用两个操作:一个避开能量为0(为什么,因为后面要取log),第二个要取log。那么现在的形式应该是类似于:log||X||^2这种样子。
接下来开始对返回结果的容器feature开始初始化,防止内部有NaN(not a number)。然后把结果开始装入feature,
![]()
接下来两种选项是使用哪种方式,针对不同的选项对feature中的部分进行调整,细节不看,到目前位置我们已经拿到了feature,里面已经存放这我们所需的特征向量。
那么跟官网给出的MFCC的教程进行比较:
For each frame:
- Extract the data, do optional dithering, preemphasis and dc offset removal, and multiply it by a windowing function (various options are supported here, e.g. Hamming)
- Work out the energy at this point (if using log-energy not C0).
- Do FFT and compute the power spectrum
- Compute the energy in each mel bin; these are e.g. 23 triangular overlapping bins whose centers are equally spaced in the mel-frequency domain.
- Compute the log of the energies and take the cosine transform, keeping as many coefficients as specified (e.g. 13)
- Optionally do cepstral liftering; this is just a scaling of the coefficients, which ensures they have a reasonable range.
说明我们整体的追踪是正确的,细节有时间补一版,然后把MFCC单独提取出来放入git中,主要看时间,希望能帮到大家。