上一节《Pandas入门1 -- 简介与安装》
要学习Pandas的功能,首先要理解Pandas的数据结构(Data structure)
Pandas里面应用的最多的一维数据结构:Series 和 二维数据结构: DataFrame
三维的数据结构Panel,由于使用频率极少,且随着Pandas功能越来越强大,Panel的升级维护工作特别繁重,性价比不高,所以Pandas决定今后不支持Panel了
本文主要集中介绍使用的最多,且最核心的Series 和 DataFrame
Series 是一种类,用于表示1维带标签的数组,Series,顾名思义,“序列”,很容易理解也很容易记忆
最基本的创建Series对象的方法是:
s=pd.Series(data,index=index)
其中,data可以是一个列表,或者是一个Python Dictionary对象,或者是一个标量,比如,5
index是一个标签列表(Label list);当不指定标签的时候,默认标签列表是[0,1,2,3,4,5....]
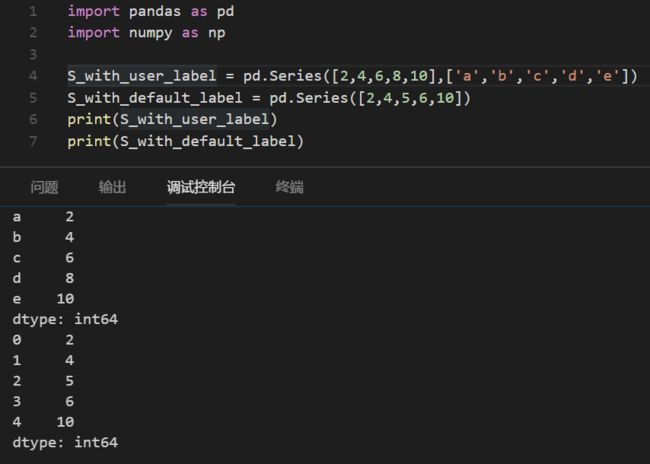
例如,创建一个数据(data)为[2,4,6,8,10],标签(index)为['a','b','c','d','e']的Series对象
范例程序:
import pandas as pd
import numpy as np
S_with_user_label = pd.Series([2,4,6,8,10],['a','b','c','d','e'])
S_with_default_label = pd.Series([2,4,5,6,10])
print(S_with_user_label)
print(S_with_default_label)
运行结果如下,第一列是标签(Label),第二列是数据(Data)
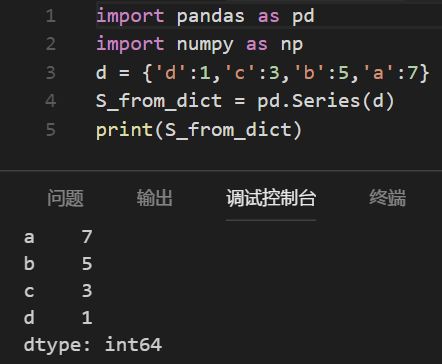
Series对象也可以用字典(dictionary)来创建,若没有指定index;Series对象创建时,会按照字典的键值(keys)来排序,如下图所示
若指定了index,则按指定的index 列表来创建Series对象,如下图所示
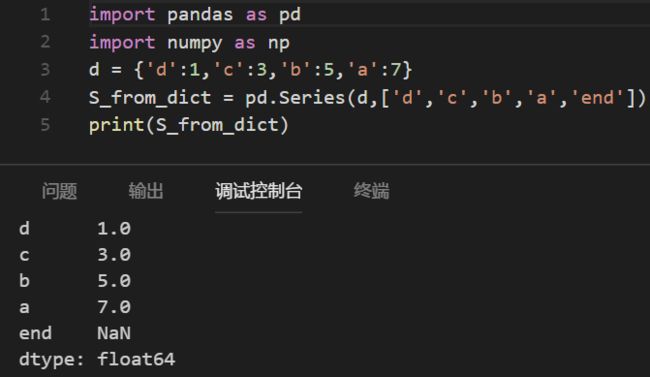
注意:NaN (not a number) is the standard missing data marker used in pandas
Series类 也类似Dictionary 类,有values 和 index
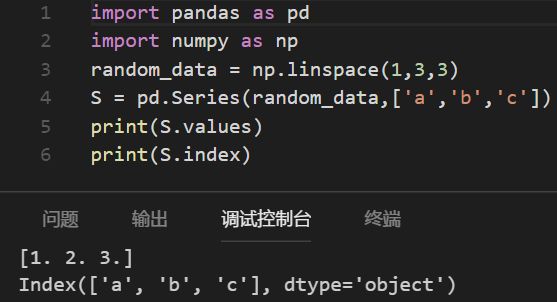
Series对象也可以用标量(scalar)来创建,如下图所示
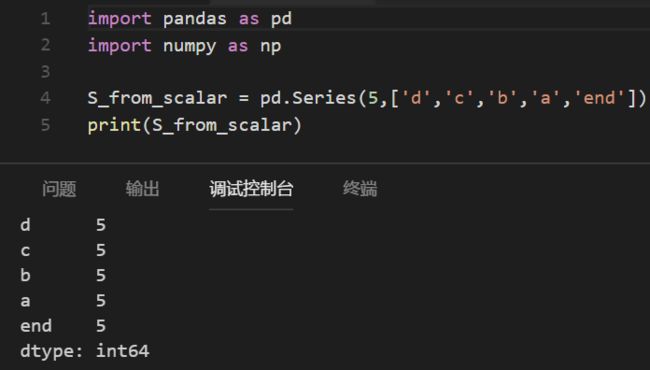
到此,Series类,及Series对象的创建就介绍完毕。
下一节,将介绍Series对象的操作