全网谁家热干面销量最高?教你用Python轻松获取
▼
更多精彩推荐,请关注我们
▼

作者:Mika
数据:真达
后期:泽龙
【导语】:今天我们聊聊热干面,Python技术部分可以直接看第三部分。公众号后台,回复关键字“热干面”获取完整数据。
Show me data,用数据说话
今天我们聊聊 热干面
点击下方视频,先睹为快:
面条在滚水里汆烫,起锅盛入碗中,淋上事先调制好的浓稠麻酱,加上酱油、辣椒油、葱花,再配上新鲜的酸豆角和萝卜丁,一碗传统的热干面就做好了。刚端上桌的面条,冒着热气,拿筷子一搅拌,香气随着四溢开来,充满了一股人间烟火的味道。
4月8日零时起,在封城76天后,武汉与外界的通道重新开启。

伴随着复工复产的有序进行,一碗碗热气腾腾、酱香弹牙的热干面也回来了。
01
瞬间被抢购一空的
热干面
4月6日晚, 在为湖北带货的直播中,央视主持人“段子手”朱广权与“带货一哥”李佳琦,在历时两个小时的直播中,累计卖出了 4014万 的湖北商品!其中热干面等湖北产品更是卖疯了,上架仅仅几分钟都被抢购一空。

那么都是谁家卖的热干面最火,最好吃?吃货们都怎么看?我们搜集整理了淘宝上关于热干面店铺的数据,今年就教你,怎么用Python来爬取和分析。
02
全网热干面销售情况
首先我们来看到结论,具体的代码实现本文请看第三部分。
店铺销量排行

在热干面店铺销量数据可以看到:
蔡林记旗舰店拔得头筹,以月销量28万+遥遥领先。其次天猫超市的销量也不少,以17万+位居第二。之后是阿宽旗舰店和韩太旗舰店,月销量都在10万+左右。值得注意的是,李子柒家的热干面销量也不错,在top10店铺中占据一席之地。
各省店铺销量排行

再看到热干面销售最多的店铺省份,作为热干面的发源地,湖北当仁不让位居第一。其次是上海、四川分别位居第二和第三。

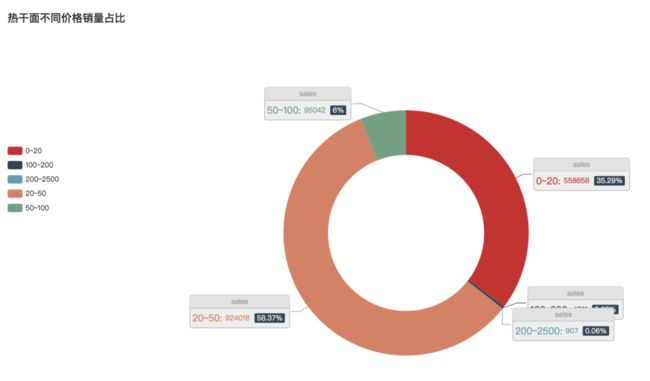
热干面都卖多少钱呢?

我们分析了淘宝上销售热干面的价格区间,一份热干面一般有5-6包左右。其中定价在20-50元一份的产品最多,也是全网销量最好的,占比达到58.37%。紧接着0-20元价格区间的热干面产品占比第二,在全网销量占比为35.29%。
买热干面,大家都看重什么?

看到热干面的评论词云,我们发现:
在购买热干面时,大家评论时对口味特别看重,“芝麻酱”“调料”“花生酱”口味是否“正宗”等都是关注的焦点。
此外,热干面在制作上是否方便也是大家关注的重点,“速食”“免煮”也是吃货们常常提到的词。
同时,“包邮”也是很关键的。对于消费者们来说,商品是否包邮在选择购买方面占了很大的比重。
03
用Python 分析
谁家的热干面买的最火
那么如何用Python来获取这些数据的呢?
我们搜集整理了淘宝网关于热干面的100页商品数据,使用Python进行整理分析。整个数据分析的过程分为以下三步:
数据获取
数据清洗
数据可视化
1. 数据获取
使用selenium抓取淘宝商品
首先确定爬虫的策略,淘宝的商品页面数据是通过Ajax加载的,但是这些Ajax接口和参数比较复杂,可能会包含加密秘钥等,所以想要自己分析Ajax并构造参数,还是比较困难的。对于这种页面,最方便快捷的方法就是通过Selenium。
因此,在此次项目项目中,我们利用selenium抓取淘宝商品并使用Xpath解析得到商品的名称、价格、购买人数、店铺名称、和店铺所在地的信息,并将数据保存在本地。具体爬虫思路如下:
代码实现:
# 导入所需包
import pandas as pd
import re
import parsel
import time
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 打开浏览器
browser = webdriver.Chrome()
wait = WebDriverWait(browser, 10)
# 定义函数登录淘宝
def login_taobao_acount():
# 登录URL
login_url = 'https://login.taobao.com/member/login.jhtml'
# 打开网页
browser.get(login_url)
# 支付宝登录
log = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#login-form > div.login-blocks.sns-login-links > a.alipay-login'))
)
log.click()
# 定义函数搜索商品
def search(key_word):
try:
browser.get('https://www.taobao.com')
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#q'))
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button')))
input.send_keys(key_word)
submit.click()
total = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.total')))
return total.text
except TimeoutException:
return search(key_word)
# 定义函数获取单页的商品信息
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
# 解析数据
html = parsel.Selector(browser.page_source)
# 获取数据
goods_name = html.xpath('//div[@class="grid g-clearfix"]//img/@alt').extract()
shop_name = html.xpath('//div[@class="grid g-clearfix"]//div[@class="shop"]/a/span[2]/text()').extract()
price = html.xpath('//div[@class="grid g-clearfix"]//div[contains(@class,"price")]/strong/text()').extract()
purchase_num = [re.findall(r'(.*?) 爬取出来的数据以数据框的形式存储,结果如下图所示。
df_all.head()

查看一下数据框的大小,可以看到一共有4404个样本。
df_all.shape
(4404, 5)
2. 数据探索和数据清洗
此处我们对数据进行以下的处理以方便后续的数据分析和可视化工作:
去除重复数据
去除购买人数为空的记录
类型转换:将购买人数转换为数值型数据
字段扩充:增加收入列,价格*购买人数=收入
字段扩充:增加商品价格分箱数据
提取省份名称字段。
对商品名称进行分词处理。
代码实现:
# 读入数据
df_all = pd.read_excel('热干面数据.xlsx')
df = df_all.copy()
# 去除重复值
df.drop_duplicates(inplace=True)
# 删除购买人数为空的记录
df = df[df['purchase_num'].str.contains('人付款')]
# 提取数值
df['num'] = [re.findall(r'(\d+\.{0,1}\d*)', i)[0] for i in df['purchase_num']] # 提取数值
df['num'] = df['num'].astype('float') # 转化数值型
# 提取单位
df['unit'] = [''.join(re.findall(r'(万)', i)) for i in df['purchase_num']] # 提取单位
df['unit'] = df['unit'].apply(lambda x:10000 if x=='万' else 1)
# 计算真实金额
df['purchase_num'] = df['num'] * df['unit']
# 提取省份
df['province_name'] = df['location'].str.split(' ').apply(lambda x:x[0])
# 删除多余的列
df.drop(['num', 'unit'], axis=1, inplace=True)
# 重置索引
df = df.reset_index(drop=True)
df.head()

# 分词
import jieba
import jieba.analyse
txt = df['goods_name'].str.cat(sep='。')
# 添加关键词
jieba.add_word('热干面')
# 读入停用词表
stop_words = []
with open('stop_words.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加停用词
stop_words.extend(['10', '12', '20', '200g', '500g', '900g', '300g'])
# 评论字段分词处理
word_num = jieba.analyse.extract_tags(txt,
topK=100,
withWeight=True,
allowPOS=())
# 去停用词
word_num_selected = []
for i in word_num:
if i[0] not in stop_words:
word_num_selected.append(i)
key_words = pd.DataFrame(word_num_selected, columns=['words','num'])
3. 数据分析和可视化
此处我们使用pyecharts进行动态数据可视化展示。我们主要对以下几个方面信息进行分析。
店铺销量排名Top10,看看哪些店铺销量高。
各省份店铺数量排名Top10,看看销量最高的热干面都来自哪里。
全国省份销量地区分布
商品标题文本分析,看看热干面搜索的结果页面,哪种种类关键词出现的比较多。
商品价格分布和各价格区间的销量表现。
店铺销量排名top10 - 柱形图
代码实现:
# 导入包
from pyecharts.charts import Bar
from pyecharts import options as opts
# 计算top10店铺
shop_top10 = df.groupby('shop_name')['purchase_num'].sum().sort_values(ascending=False).head(10)
# 绘制柱形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(shop_top10.index.tolist())
bar1.add_yaxis('sales_num', shop_top10.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title='热干面店铺商品销量Top10'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
visualmap_opts=opts.VisualMapOpts(max_=shop_top10.values.max()))
bar1.render()
全国各省份销量排名Top10 - 柱形图
代码实现:
# 计算销量top10
province_top10 = df.groupby('province_name')['purchase_num'].sum().sort_values(ascending=False).head(10)
# 条形图
bar2 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar2.add_xaxis(province_top10.index.tolist())
bar2.add_yaxis('sales_num', province_top10.values.tolist())
bar2.set_global_opts(title_opts=opts.TitleOpts(title='热干面商品销量省份排名Top10'),
visualmap_opts=opts.VisualMapOpts(max_=province_top10.values.max()))
bar2.render()
全国省份销量地区分布-地图
代码实现:
from pyecharts.charts import Map
# 计算销量
province_num = df.groupby('province_name')['purchase_num'].sum().sort_values(ascending=False)
# 绘制地图
map1 = Map(init_opts=opts.InitOpts(width='1350px', height='750px'))
map1.add("", [list(z) for z in zip(province_num.index.tolist(), province_num.values.tolist())],
maptype='china'
)
map1.set_global_opts(title_opts=opts.TitleOpts(title='国内各省份热干面销量分布'),
visualmap_opts=opts.VisualMapOpts(max_=300000),
toolbox_opts=opts.ToolboxOpts()
)
map1.render()
不同价格区间的商品数量:
代码实现:
def tranform_price(x):
if x <= 20:
return '0~20'
elif x <= 50:
return '20~50'
elif x <= 100:
return '50~100'
elif x <= 200:
return '100~200'
else:
return '200~2500'
df['price_cut'] = df.price.apply(lambda x: tranform_price(x))
price_num = df.price_cut.value_counts()
price_num
bar3 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar3.add_xaxis(price_num.index.tolist())
bar3.add_yaxis('price_num', price_num.values.tolist())
bar3.set_global_opts(title_opts=opts.TitleOpts(title='不同价格区间的商品数量'),
visualmap_opts=opts.VisualMapOpts(max_=1500))
bar3.render()
不同价格区间的销量占比
代码实现:
from pyecharts.charts import Pie
price_cut_num = df.groupby('price_cut')['purchase_num'].sum()
data_pair = [list(z) for z in zip(price_cut_num.index, price_cut_num.values)]
# 饼图
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
# 内置富文本
pie1.add(
series_name="sales",
radius=["35%", "55%"],
data_pair=data_pair,
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),
)
pie1.set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", pos_top='30%', orient="vertical"),
toolbox_opts=opts.ToolboxOpts(),
title_opts=opts.TitleOpts(title='热干面不同价格销量占比'))
pie1.set_series_opts(
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{a}
{b}: {c} ({d}%)")
)
pie1.render()
商品标题文本分析 - 词云图
代码实现:
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
# 词云图
word1 = WordCloud(init_opts=opts.InitOpts(width='1350px', height='750px'))
word1.add("", [*zip(key_words.words, key_words.num)],
word_size_range=[20, 200],
shape=SymbolType.DIAMOND)
word1.set_global_opts(title_opts=opts.TitleOpts('热干面店铺商品关键词分布'),
toolbox_opts=opts.ToolboxOpts())
word1.render()
# 在一个页面中生成所有图
page = Page()
page.add(bar1, bar2, map1, bar3, pie1, word1)
page.render('热干面数据分析.html')
以上就是如何用Python获取全网热干面销量数据的内容啦,如果感兴趣的话不妨下载数据和代码,自己分析了试试。如果有什么感兴趣的内容和话题也可以给我们留言哦~
本文出品:CDA数据分析师(ID: cdacdacda)
2020年CDA课程全新升级
扫描下方二维码
咨询CDA课程详情


长 按 关 注
CDA课程咨询
联系人:曲老师
电话:18108252445