Face Aging with Identity-Preserved Conditional Generative Adversarial Networks随笔
背景:
人脸老化在刑侦、跨年龄段识别以及娱乐等方面起到相当重要的作用,然而研究最大的阻碍是缺乏每个人跨越时间维度的脸部标记数据。

目的:
随机输入一张人脸图像,生成五张更加真实的老化人脸。五张老化人脸分别对应作者标定的年龄组(11-20,21-30, 31-40, 41-50,以及50+),并且保留个人身份信息。
为什么分年龄组?
因为每个人脸老化程度不同,无法做到生成精确年龄的老化人脸。
传统方法:
基于原型的方法(prototype-based)计算年龄组的平均脸,年龄组间的差异性被用做生成老化的脸。目标个人的特征将被缺失,模型生成的脸不真实。
基于物理模型的方法(Physical model-based)可以模拟发色、肌肉和纹理等变化,样本过多计算量冗余。
目前神经网络方法:
2018年4月发表的“基于RNN的人脸老化方法研究”中,RNN网络因为每一张图片需要解决LBFGS算法的问题所以时效很低,并且生成的老化人脸年龄组之间相差不大且生成图像相对模糊。

本文模型框架:

IPCGANs = LSGANs module + identity preserved module + age classifier module
IPCGAN(Identity-Preserved Conditional Generative Adversarial Networks)中,LSGANs生成老化人脸,Identity-Preserved模型保留目标的个人信息,age classifier确保生成的人脸图片具有目标年龄。
Objective function:

LSGANs(Least Squares Generative Adversarial Networks),条件GAN生成老化人脸不真实并且质量很差,LSGANs将生成的人脸逼近决策边界使得判别器难以区分,并且LSGANs可以生成更高质量的图片,网络训练也相对稳定。
Loss function:

注释:
x为输入判别器的真实目标年龄组人脸服从Px(x)分布
y为输入生成器的真实人脸服从Py(y)分布
Ct为目标年龄组
LSGAN网络的知识点回顾,清楚的同学可以自行跳过
LSGANs(Least Squares Generative Adversarial Networks)将标准GAN的目标函数由交叉熵损失换成最小二乘损失,从而对标准GAN生成的图片质量不高以及训练过程不稳定这两个缺陷进行改进。
为什么普通GANs生成图片质量不高?
GANs由判别器和生成器组成,判别器用于判断一张图片是来自真实数据还是生成器,要尽可能地给出准确判断;生成器用于生成图片,并且生成的图片要尽可能地混淆判别器。 利用交叉熵作为损失,会使得生成器不会再优化那些被判别器识别为真实图片的生成图片。但事实这些生成图片距离判别器的决策边界仍然很远(距真实数据比较远),所以生成器的生成图片质量并不高。
为什么生成器不再优化生成图片呢?
因为生成器已经完成我们为它设定的目标——尽可能地混淆判别器,所以交叉熵损失已经很小了。通过将GANs中的交叉熵loss换成计算最小二乘loss,要使得最小二乘loss较小,需在混淆判别器的前提下还得让生成器把距离决策边界比较远的生成图片拉向决策边界。

因为辨别器 D 使用的是 sigmoid 函数,sigmoid 函数本质上不会惩罚远离 w 的 x。由于sigmoid 函数饱和得十分迅速,该函数会忽略 x 到决策边界 w 的距离。sigmiod函数满足于将 x 标注正确,因此随着 x变得越来越大,辨别器 D 的梯度就会很快地下降到 0。因此对数损失并不关心距离,它仅仅关注于是否正确分类。
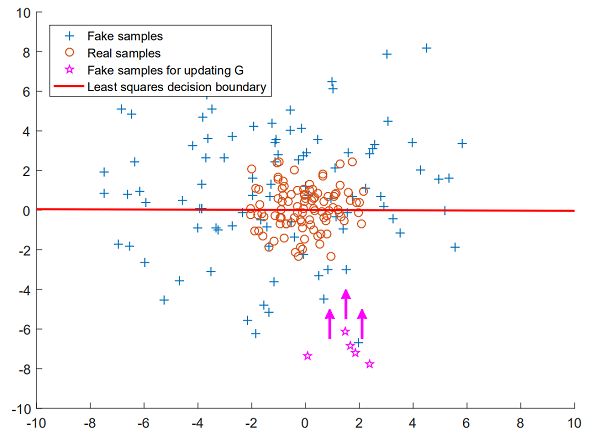
在 Least Squares loss中,与 w(即上例图中 Pdata(X) 的回归线)相当远的数据将会获得与距离成比例的惩罚。因此梯度就只有在 w完全拟合所有数据 x 的情况下才为 0。如果生成器 G 没有捕获数据流形(data manifold),那么这将能确保辨别器 D 服从多信息梯度(informative gradients)。在优化过程中,辨别器 D 的 L2 损失想要减小的唯一方法就是使得生成器 G 生成的 x 尽可能地接近 w。只有这样,生成器 G 才能学会匹配 Pdata(X)。
LSGANs loss function:
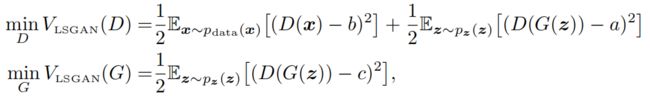
注释:常数a、b分别表示假图片和真图片的标记;c是生成器为了让判别器认为生成图片是真实数据而定的值。
Identity-Preserved module 使得生成样本的仍然具有初始的身份信息。
Loss function:
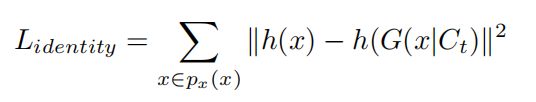
注释:x为输入生成器的真实人脸图。
H(.)函数是利用预训练ALexnet从特定的特征层提取特征,Lidentity促使生成的图像在同一特征空间中接近输入人脸的特征。不直接计算x与G(x|Ct)的均方差,是因为在衰老的过程中发色、皱纹和发际线都会发生变化,若强制计算x与G(x|Ct)的均方差会导致生成的图片会与输入图一样无法达到老化效果。
Age classification module 保障生成的人脸老化图是在指定的目标年龄组中,并识别生成人脸来自哪个年龄组。通过反向传播分类器loss促进生成器的参数变化,从而生成更加准确年龄组老化人脸图。
Loss function:
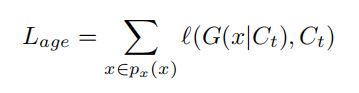
注释:l(.)表示计算softmax loss
Softmax函数用来解决多分类问题,得到的值属于(0,1)
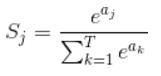
Sj为softmax输出向量S的第j个数的值(概率)。
Softmax loss:
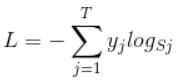
yj前面有个求和符号,j的范围也是1到类别数T,因此y是一个1*T的向量,里面的T个值,而且只有1个值是1,其他T-1个值都是0。真实标签对应的位置的那个值是1,其他都是0。所以这个公式其实有一个更简单的形式:
![]()
举例:
假设一个5分类问题,然后一个样本I的标签y=[0,0,0,1,0],也就是说样本I的真实标签是4,假设模型预测的结果概率(softmax的输出)p=[0.1,0.15,0.05,0.6,0.1],可以看出这个预测是对的,那么对应的损失L=-log(0.6)。那么假设p=[0.15,0.2,0.4,0.1,0.15],这个预测结果就很离谱了,因为真实标签是4,而你觉得这个样本是4的概率只有0.1,对应损失L=-log(0.1)。那么假设p=[0.05,0.15,0.4,0.3,0.1],这个预测结果虽然也错了,但是没有前面那个那么离谱,对应的损失L=-log(0.3)。我们知道log函数在输入小于1的时候是个负数,而且log函数是递增函数,所以-log(0.6) < -log(0.3) < -log(0.1)。预测错比预测对的损失要大,预测错得离谱比预测错得轻微的损失要大。
实验结果:
