高斯标准化 意图和实现
因为许多学习算法在 不同范围的特征数据中 呈现不同的学习效果。
e.g : SVM算法在没有标准化的数据集上表现比较差
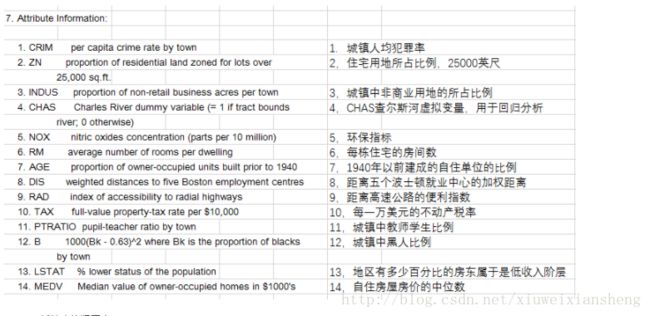
波士顿房价数据集(Boston House Price Dataset)
(下载地址:http://t.cn/RfHTAgY)
使用sklearn.datasets.load_boston即可加载相关数据。该数据集是一个回归问题。每个类的观察值数量是均等的,共有 506 个观察,13 个输入变量和1个输出变量。
每条数据包含房屋以及房屋周围的详细信息。其中包含城镇犯罪率,一氧化氮浓度,住宅平均房间数,到中心区域的加权距离以及自住房平均房价等等。
from sklearn import preprocessing
import numpy as np
from sklearn.datasets import load_boston
boston = load_boston()
X,y =boston.data,boston.target
# 取前三个特征
X[:,:3].mean(axis=0)out: array([ 3.59376071, 11.36363636, 11.13677866])
X[:,:3].std(axis=0)out: array([ 8.58828355, 23.29939569, 6.85357058])
preprocessing 进行标准化
第一维度 特征 均值3.9 标准差相对于其他两个有点大!!
preprocessing 进行标准化
均值为0(实际中很接近于0的一个数) 标准差为1
1 preprocessing.scale(对象)
X_2 = preprocessing.scale(X[:,:3])
X_2.mean(axis=0)
X_2.std(axis=0)out1:array([ 6.34099712e-17, -6.34319123e-16, -2.68291099e-15])
out2: array([ 1., 1., 1.])
2 preprocessing.StandardScaler() .fit(对象) .tansform(对象)
my_scaler = preprocessing.StandardScaler()
my_scaler.fit(X[:,:3])
my_scaler.transform(X[:,:3]).mean(axis=0)
my_scaler.transform(X[:,:3]).std(axis=0)out1 :array([ 6.34099712e-17, -6.34319123e-16, -2.68291099e-15])
out2: array([ 1., 1., 1.])
3 MiniMaxScaler类 将样本数据根据最大值和最小值调整到一个区间内
my_minmax_scaler = preprocessing.MinMaxScaler()
my_minmax_scaler.fit(X[:,:3])
my_minmax_scaler.transform(X[:,:3]).max(axis=0)out: array([ 1., 1., 1.])
MinMaxScaler类可以将默认的区间0-1 修改到所需要的区间
my_minmax_scaler = preprocessing.MinMaxScaler(feature_range = (-3,3))
my_minmax_scaler.fit(X[:,:3])
my_minmax_scaler.transform(X[:,:3]).max(axis=0)out: array([ 3., 3., 3.])