【读书笔记】-- 文本可视化研究综述
1、一些背景
1.1 文本可视化简介
文本可视化技术综合了文本分析、数据挖掘、数据可视化、计算机图形学、人机交互、认知科学等学科的理论和方法,为人们理解复杂的文本内容、结构和内在的规律等信息的有效手段。
1.2文本可视化作用和重要性
问题
海量信息使人们处理和理解的难度日益增大,传统的文本分析技术提取的信息仍然无法满足人们利用浏览及筛选等方式对其进行合理的分析理解和应用。
作用
将文本中复杂的或者难以通过文字表达的内容和规律以视觉符号的形式表达出来,同时向人们提供与视觉信息进行快速交互的功能,使人们能够利用与生俱来的视觉感知的并行化处理能力快速获取大数据中所蕴含的的关键信息。
重要性
文本可视化涵盖了信息收集、数据预处理、知识表示、视觉呈现和交互等过程。
其中,数据挖掘和自然语言处理等技术充分发挥计算机的自动处理能力,将无结构的文本信息自动转换为可视的有结构信息。
而可视化呈现使人类视觉认知、关联、推理的能力得到充分的发挥。
因此,文本可视化有效的结合后了机器智能和人工智能,为人们更好的理解文本和发现知识听过了新的有效途径。
2文本可视化的基本框架:

2.1文本分析
文本可视化依赖于自然语言处理,因此词袋模型、命名实体识别、关键词抽取、主题分析、情感分析等是较常用的文本分析技术。
文本分析的过程主要包括
(1)特征提取,通过分词、抽取、归一化等操作提取出文本词汇及的内容;
(2)利用特征构建向量空间模型(vector space model,VSM)并进行降维,以便将其呈现在低维空间,或者利用主题模型处理特征;
(3)最终以灵活有效的形式表示这些过程处理过的数据,以便进行可视化呈现和交互。
2.2可视化对象类型
(1)信息图
文本内容的视觉编码主要涉及尺寸、颜色、形状、方位、文理等;文本间关系的视觉编码主要涉及网络图、维恩图、树状图、坐标轴等。
文本可视化的一个重要任务
选择合适的视觉编码呈现文本信息的各种特征:例如词频通常由字体的大小表示,不同的命名实体类别用颜色加以区分。
(2)交互
便于用户能够通过可视化有效地发现文本信息的特征和规律,通常会根据使用的场景为系统设置一定程度的交互功能。
交互方式类型:
高亮(highlighting)、缩放(zooming)、动态转换(animated transitions)、关联更新(brushing and linking)、焦点加上下文(focus+context)等。
3文本可视化典型的方法和方案
3.1方案一、文本内容
如何快速获取文本内容的重点,快速理解文本的大体内容
方法一、基于词频的可视化
思路:将文本看成词汇的集合(词袋模型),用词频表现文本特征
计算方法:TFIDF
可视化形式:标签云(tag cloud)
标签云将关键词按照一定的顺序和规律排列,如频度递减、字母顺序等,并以文字的大小代表词语的重要性。
应用:广泛用于与报纸、杂志等传统媒体和互联网,甚至T恤等实物中。
类型:
(1)一行一行水平排列
(2)词语布局遵循严格的条件,文字间的空隙得以充分利用
 :
:
(3)文字轮廓
 :
:
(4)上下文信息卡
DocumentCard
方法二、基于词汇分布的可视化
思路:反映词频在文本中的命中位置
计算方法:词汇做索引
可视化形式:TitleBars
应用:查询任务中快速了解文本内容与查询意图的相关度
3.2方案二、文本关系
理解文本内容和发现规律
方法一、文本内在关系
思路:反映文本内在结构和语义关系
可视化形式:
(1)网络图
应用:呈现命名实体在同一文本的同现关系
(2)后缀树(suffix tree)
应用:查询词的上下文关系
Word Tree:
NETAPANK:用此方法
应用:展现文本集中常见上下文关系,帮助写作时选用词汇
(3)链路图
 :
:
应用:呈现文本中命名实体的从属关系、并列关系等。
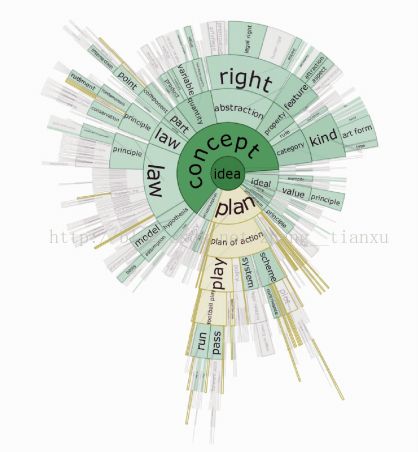
(4)径向空间填充:
FanLens
应用:呈现命名实体的层次关系
DocuBurst
应用:呈现词语在Wordnet中的上下位关系,及词频
方法二、文本外在关系
思路:反映文本间的引用关系、网页的超链关系等直接关系以及主题相似性等潜在关系(一般基于聚类算法用来呈现主题分布,并展示与特定主题相关的关键词,主要应用于信息检索、主题检测、话题演变等方面)
可视化形式:
(1)网络图
应用:对文本集的引用关系
网络节点代表文本,有向线代表引用关系
(2)
应用:展现文献共引关系,便于领域研究
比CiteSpace这种传统网络图可视化方案呈现文献更为细致的信息
(3)标签云改造
呈现由jaccard系数计算出的聚类结果,同行同主题,相邻行主题相似
插播:
文本主题分析除了基于统计的方法之外还有基于特征降维的方法
(1)高维SVM表示文本
(2)投影将高维特征向量投影到2D,3D能表示的维数
降维方式:
a、基于奇异值分解(singular value decomposition,SVD)的潜在语义索引(latent semantic indexing,LSI)
b、主成分分析(principal component analysis,PCA)
c、对应分析(correspondence analysis,CA)
d、多维尺度分析(multidimensional scaling,MDS)
e、基于人工神经网络的自组织映射图网络(self-organizating map,SOM)
特征降维的可视化:
(1)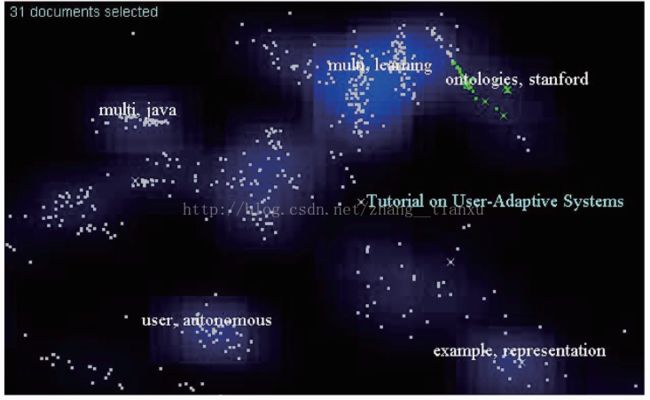
(2)标签云
ProjCloud:
用k-means算法聚类,用标签云展示相似文本和此类关键词集合
(3)嵌套长方形(分层次可视化)
解决降维过程信息丢失,带来的可视化缺乏扩展性
长方形的方向表示层次的变化,大小表示重要程度,图形复杂,文本标签缺乏可读性

展示新闻文本
Map of the Market
展示股票市场的概览
ThemeCrowds
与标签云结合展示主题的层次关系及主题关键词
(4)力导向图(force-directed placement,FDP)
InfoSky
生成层次聚类树聚类信息的分层级展示
3.3方案三、多层面信息
结合信息的多个方面帮助用户更深层的理解文本数据发现其中的规律,特别是包含时间关系的文本
方法一、时间与其他信息结合的可视化
思路:时间信息提供文本内容变化、数据规律的信息
可视化形式:
(1)引入时间轴,信息按时间顺序排列
(2)标签云与时间结合
a、词语下引入折线图,表示词语使用频度的变化
SparkCloud:
b、标签云上标上不同颜色和图形
c、时间折线图,时间点标签云,折线图上值越大表示此时刻的标签云标签越多

(3)叠式图(stacked graph)
每层代表一个事物,以颜色区分,粗细代表频度
a、ThemeRiver
做了平滑和堆叠处理
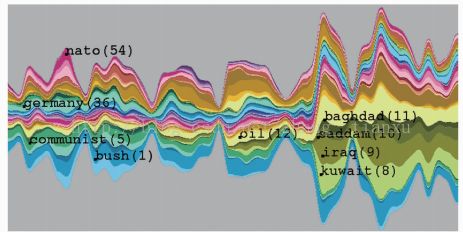
MemTracker
b、ThemeRiver扩展
NewsRiver,VisualBackchannel
跟踪博客,微博,twitter的变化
TIARA结合标签云
通过主题分析技术(Latent Dirichlet allocation,LDA)抽取文本主题融入ThemeRiver,并在每层上显示关键词
c、Tag River
河流结合标签云
d、TextFlow
河流+主题的产生,分流合并
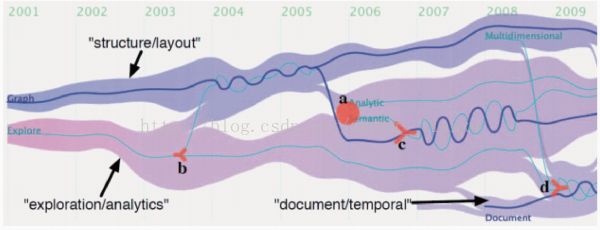
e、EventRiver
f、History Flow
文档内容随时间变化
(3)、螺旋图
文本信息的周期性变化
多层次螺旋图还可以对比不同数据集
(4)、动态呈现包含时间的数据
TwitterScope
地图形式呈现twitter内容,并以颜色区分不同主题,内容会随着时间动态消失、融合
Streamit
以动画的形式从左到右实时地呈现文本的聚合和分化

(5)结合时间空间信息
信息在监测Twitter上的突发事件并显示在地图上
信息在twitter上的传播过程和规律
Whisper:
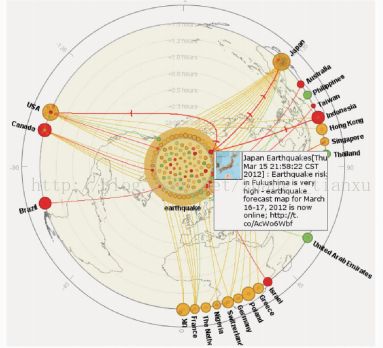
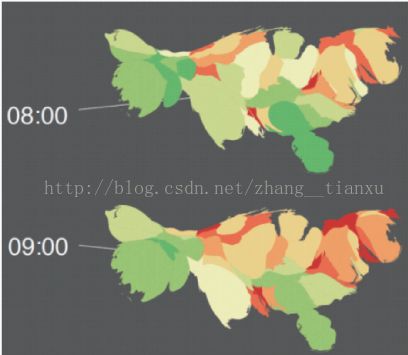
以颜色表示心情,显示情绪的变化
方法二、其他多层信息的可视化
(1)parallel Tag Cloud
结合标签云和常用于多维数据展示的平行坐标轴
(2)FacetAtlas
两种糖尿病,红色表示相似并发症,绿色表示相似症状
(3)Jigsaw、FeatureLens、ASE
通过协同展示多个视角
4、总结
(1)常见文本分析技术及可视化方式
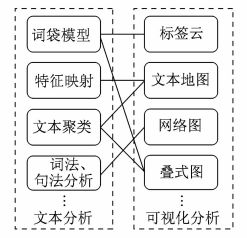
(2)
5、评价
(1)可用性测试(usability testing):用户使用反馈,指导设计
(2)可用性检查(usability inspection):专家检查,测试技术细节
(3)个案研究(case study):应用场景得到研究结论
(4)对比测试:对比主客观数据
参考:唐家渝, 刘知远, 孙茂松. 文本可视化研究综述[J]. 计算机辅助设计与图形学学报, 2013, 25(3): 273-285.
思考:总结的比较全面、系统。毕设的综述可视化部分就靠它了