Mysql优化 ——explain 查询和分析SQl的执行记录
Mysql优化
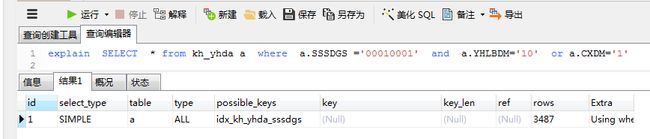

分析原因是因为加了or ,并且or 后面的语句并未加入索引查询条件,索引or 后面的语句进行了全表扫描。然后SQL语句写法,加入a.SSSDGS ='00010001'条件,再执行explain 分析,整个sql已经使用到了索引,并且ref = const.扫描了1169行就将整个结果集进行返回。相较于之前的sql,全表扫描,数据量大大减少。
使用 explain 查询和分析SQl的执行记录,可以进行sql的性能优化!
explain结果字段的含义介绍
id
SELECT识别符。这是SELECT的查询序列号,表示查询中执行select子句或操作表的顺序!
select_type
SELECT类型,可以为以下任何一种:
SIMPLE:简单SELECT(不使用UNION或子查询)
PRIMARY:最外面的SELECT
UNION:UNION中的第二个或后面的SELECT语句
DEPENDENT UNION:UNION中的第二个或后面的SELECT语句,取决于外面的查询
UNION RESULT:UNION 的结果
SUBQUERY:子查询中的第一个SELECT
DEPENDENT SUBQUERY:子查询中的第一个SELECT,取决于外面的查询
DERIVED:导出表的SELECT(FROM子句的子查询)
table
输出的行所引用的表!
type
联接类型。下面给出各种联接类型,按照从最佳类型到最坏类型进行排序:
system:表仅有一行(=系统表)。这是const联接类型的一个特例。
const:表最多有一个匹配行,它将在查询开始时被读取。因为仅有一行,在这行的列值可被优化器剩余部分认为是常数。const表很快,因为它们只读取一次!
eq_ref:对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。
ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。
ref_or_null:该联接类型如同ref,但是添加了MySQL可以专门搜索包含NULL值的行。
index_merge:该联接类型表示使用了索引合并优化方法。
unique_subquery:该类型替换了下面形式的IN子查询的ref: value IN (SELECT primary_key FROM single_table WHERE some_expr) unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。
index_subquery:该联接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引: value IN (SELECT key_column FROM single_table WHERE some_expr)
range:只检索给定范围的行,使用一个索引来选择行。
index:该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。
ALL:对于每个来自于先前的表的行组合,进行完整的表扫描。
possible_keys
指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
key
显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL
key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)
ref
表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows
显示MySQL认为它执行查询时必须检查的行数。多行之间的数据相乘可以估算要处理的行数
filtered
显示了通过条件过滤出的行数的百分比估计值。
Extra
该列包含MySQL解决查询的详细信息
避免数据类型不一致
SELECT * from kh_yhda a where a.SSSDGS ='00010001' and a.YHLBDM='10' or ( a.SSSDGS ='00010001' AND a.CXDM='1')
SELECT * from kh_yhda a where a.SSSDGS =00010001 and a.YHLBDM='10' or ( a.SSSDGS =00010001 AND a.CXDM='1')
读取适当的记录LIMIT M,N
SELECT * from kh_yhda a;
SELECT * from kh_yhda a LIMIT 1;
用IN来替换OR
SELECT * from kh_yhda a where a.HYFLDM='IC3000' OR a.HYFLDM='IC2001' OR a.HYFLDM='IC1410'
SELECT * from kh_yhda a where a.HYFLDM in ('IC3000','IC2001','IC1410')
避免函数索引
SELECT * FROM kh_yhda WHERE YEAR(d) >= 2016;
由于MySQL不像Oracle那样支持函数索引,即使d字段有索引,也会直接全表扫描。
应改为—–>
SELECT * FROM kh_yhda WHERE d >= '2016-01-01';
1查询时,能不要*就不用*,尽量写全字段名
2大部分情况连接join效率远大于子查询
3.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
5.下面的查询也将导致全表扫描:
select id from t where name like '%abc%'
可以右% select id from t where name like 'abc%'
若要提高效率,可以考虑全文检索。
6.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
7对于连续的数值,能用 between 就不要用 in 了
select id from t where num between 1 and 3
8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
9.很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
10.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。