SpringDataJPA 系列之 JPA 简介
1.1 了解 ORM
1.1.1 概述
对象-关系映射(Object/Relation Mapping,简称 ORM),是随着面向对象的软件开发方法发展而产生的。面向对象的开发方法是当今企业级应用开发环境中的主流开发方法,关系数据库是企业级应用环境中永久存放数据的主流数据存储系统。对象和关系数据是业务实体的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据。内存中的对象之间存在关联和继承关系,而在数据库中,关系数据无法直接表达多对多关联和继承关系。因此,对象-关系映射(ORM)系统一般以中间件的形式存在,主要实现程序对象到关系数据库数据的映射。
Java 中 ORM 的原理: 先说 ORM 的实现原理,其实,要实现 JavaBean 的属性到数据库表的字段的映射,任何 ORM 框架不外乎是读某个配置文件把 JavaBean 的属 性和数据库表的字段自动关联起来,当从数据库 SELECT 时,自动把字段的值塞进 JavaBean 的对应属性里,当做 INSERT 或 UPDATE 时,自动把 JavaBean 的属性值绑定到 SQL 语句中。简单的说:ORM 就是建立实体类和数据库表之间的关系,从而达到操作实体类就相当于操作数据库表的目的。
1.1.2 为什么要有 ORM
当实现一个应用程序时(不使用 ORM),我们可能会写特别的代码,从数据库保存数据、修改数据、删除数据,而这些代码都是重复的,一个完整的系统要包含成千上万个这样重复的而又混杂的处理过程,假如要对其中某些业务逻辑或者一些相关联的业务流程做修改,要改动的代码量将不可想象。另一方面,假如要换数据库 产品或者运行环境也可能是个不可能完成的任务。而用户的运行环境和要求却千差万别,我们不可能为每一个用户每一种运行环境设计一套一样的系统。而使用 ORM 则会大大减少重复性代码。
1.1.3 常见 ORM 框架
Mybatis(ibatis):一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Ordinary Java Object,普通的 Java 对象)映射成数据库中的记录。
Hibernate:一个开放源代码的对象关系映射框架,它对 JDBC 进行了非常轻量级的对象封装,它将 POJO 与数据库表建立映射关系,是一个全自动的 ORM 框架,hibernate 可以自动生成 SQL 语句,自动执行,使得 Java 程序员可以随心所欲的使用对象编程思维来操纵数据库。
Jpa:Java Persistence API 的简称,中文名 Java 持久层 API,是 JDK 5.0 注解或 XML 描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。
1.2 JPA 简介
1.2.1 概述
我们都知道不同的数据库厂商都有自己的实现类,后来统一规范也就有了数据库驱动, Java 在操作数据库的时候,底层使用的其实是 JDBC,而 JDBC 是一组操作不同数据库的规范。我们的 Java 应用程序,只需要调用 JDBC 提供的 API 就可以访问数据库了,而 JPA 也是类似的道理。
JPA 由 EJB 3.0 软件专家组开发,作为 JSR-220 实现的一部分。但它又不限于 EJB 3.0,你可以在 Web 应用、甚至桌面应用中使用。JPA 的宗旨是为 POJO 提供持久化标准规范,由此可见,经过这几年的实践探索,能够脱离容器独立运行,方便开发和测试的理念已经深入人心了。Hibernate3.2+、TopLink 10.1.3 以及 OpenJPA 都提供了 JPA 的实现。Sun 引入新的 JPA ORM 规范出于两个原因:其一,简化现有 Java EE 和 Java SE 应用开发工作;其二,Sun 希望整合 ORM 技术,实现天下归一。
1.2.2 JPA 的优势
☞ 标准化
JPA 是 JCP 组织发布的 Java EE 标准之一,因此任何声称符合 JPA 标准的框架都遵循同样的架构,提供相同的访问 API,这保证了基于 JPA 开发的企业应用能够经过少量的修改就能够在不同的 JPA 框架下运行。
☞ 容器级特性的支持
JPA 框架中支持大数据集、事务、并发等容器级事务,这使得 JPA 超越了简单持久化框架的局限,在企业应用发挥更大的作用。
☞ 简单方便
JPA 的主要目标之一就是提供更加简单的编程模型:在 JPA 框架下创建实体和创建 Java 类一样简单,没有任何的约束和限制,只需要使用 javax.persistence.Entity 进行注释,JPA 的框架和接口也都非常简单,没有太多特别的规则和设计模式的要求,开发者可以很容易的掌握。JPA 基于非侵入式原则设计,因此可以很容易的和其它框架或者容器集成
☞ 查询能力
JPA 的查询语言是面向对象而非面向数据库的,它以面向对象的自然语法构造查询语句,可以看成是 Hibernate HQL 的等价物。JPA 定义了独特的 JPQL(Java Persistence Query Language),JPQL 是 EJB QL 的一种扩展,它是针对实体的一种查询语言,操作对象是实体,而不是关系数据库的表,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。
☞ 高级特性
JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系,这样的支持能够让开发者最大限度的使用面向对象的模型设计企业应用,而不需要自行处理这些特性在关系数据库的持久化。
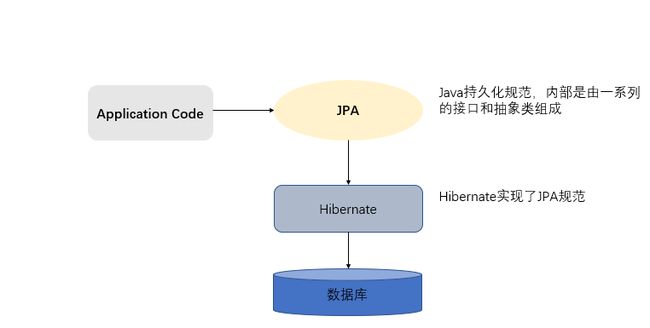
1.2.3 JPA 与 hibernate 的关系
JPA 规范本质上就是一种 ORM 规范,注意不是 ORM 框架——因为 JPA 并未提供 ORM 实现,它只是制订了一些规范,提供了一些编程的 API 接口,但具体实现则由服务厂商来提供实现。 JPA 和 Hibernate 的关系就像 JDBC 和 JDBC 驱动的关系,JPA 是规范,Hibernate 除了作为 ORM 框架之外,它也是一种 JPA 实现。好比 JDBC 规范可以驱动底层数据库吗?答案是否定的,也就是说,如果使用 JPA 规范进行数据库操作,底层需要 hibernate 作为其实现类完成数据持久化工作。
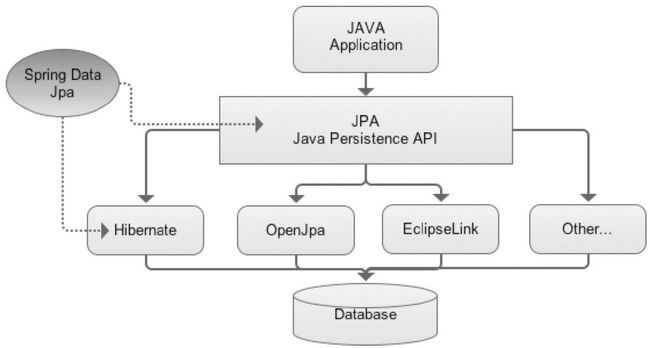
1.2.4 SpringDataJPA
JPA 是 Java Persistence API 的简称,中文名为 Java 持久层 API,是 JDK 5.0 注解或 XML 描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。可以理解为 JPA 规范的再次封装抽象,底层还是使用了 Hibernate 的 JPA 技术实现,引用 JPQL(Java Persistence Query Language) 查询语言,属于 Spring 整个生态体系的一部分。随着 Spring Boot 和 Spring Cloud 在市场上的流行,Spring Data JPA 也逐渐进入大家的视野,它们组成有机的整体,使用起来比较方便,加快了开发的效率,使开发者不需要关心和配置更多的东西,完全可以沉浸在 Spring 的完整生态标准实现下。JPA 上手简单,开发效率高,对对象的支持比较好,又有很大的灵活性,市场的认可度越来越高。
1.3 JPA 初体验
1.3.1 入门案例
☞ 导包
由于 JPA 是 sun 公司制定的 API 规范,所以我们不需要导入额外的 JPA 相关的 jar 包,只需要导入 JPA的提供商的 jar 包。我们选择 Hibernate 作为 JPA 的提供商,所以需要导入 Hibernate 的相关 jar 包。
<dependencies>
<dependency>
<groupId>org.hibernategroupId>
<artifactId>hibernate-entitymanagerartifactId>
<version>5.0.7.Finalversion>
dependency>
<dependency>
<groupId>org.hibernategroupId>
<artifactId>hibernate-c3p0artifactId>
<version>5.0.7.Finalversion>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.6version>
dependency>
dependencies>
☞ 创建实体类
/**
* Created with IntelliJ IDEA.
*
* @author Demo_Null
* @date 2020/7/28
* @description 学生类
*/
@Entity
public class Student implements Serializable {
private static final long SerialVersionUID = 1L;
@Id // 声明 id 为主键
@GeneratedValue(strategy= GenerationType.IDENTITY) // 配置主键的生成策略
private Long id;
private String name;
private Integer age;
private Boolean sex;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Boolean getSex() {
return sex;
}
public void setSex(Boolean sex) {
this.sex = sex;
}
}
☞ 核心配置文件
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<persistence-unit name="myJpa" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.jpa.HibernatePersistenceProviderprovider>
<properties>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/db"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="javax.persistence.jdbc.password" value="root"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.hbm2ddl.auto" value="create"/>
properties>
persistence-unit>
persistence>
☞ 保存一条数据
/**
* Created with IntelliJ IDEA.
*
* @author Demo_Null
* @date 2020/7/28
* @description 演示类
*/
public class Demo {
public static void main(String[] args) {
// 创建实体管理类工厂,借助 Persistence 的静态方法获取,其中传递的参数为持久化单元名称,需要 jpa 配置文件中指定
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myJpa");
// 创建实体管理类
EntityManager em = factory.createEntityManager();
// 获取事务对象
EntityTransaction tx = em.getTransaction();
// 开启事务
tx.begin();
Student tbStudent = new Student();
tbStudent.setName("张三");
tbStudent.setAge(23);
tbStudent.setSex(false);
//保存操作
em.persist(tbStudent);
// 提交事务
tx.commit();
// 释放资源
em.close();
factory.close();
}
}
☞ 运行结果
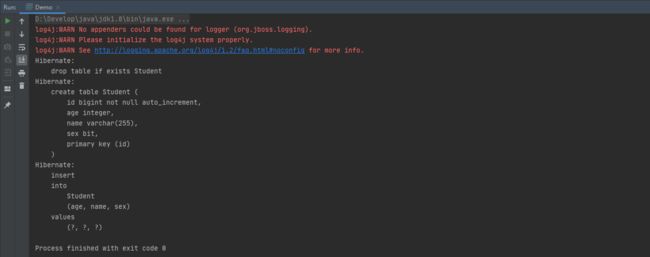
通过输出的日志可以发现,JPA 会先将与实体类同名的表删除,然后依据实体类创建一个表,接着将数据插入新创建的表中。这是怎么回事,那不是数据库永远只有一条数据?在配置文件中有这么一行配置
♞ validate:加载 hibernate 时,验证创建数据库表结构;
♞ create:每次加载 hibernate,重新创建数据库表结构;
♞ create-drop:加载 hibernate 时创建,退出是删除表结构;
♞ update: 加载 hibernate 自动更新数据库结构。
我们将其改为 update 就好了,再次执行发现它并没有从新创建数据库,而是直接插入了数据,执行多次,数据库中也插入了多条数据。
mysql> select * from student;
+----+------+-----+-----+
| id | Name | age | sex |
+----+------+-----+-----+
| 1 | 张三 | 23 | 0 |
| 2 | 张三 | 23 | 0 |
| 3 | 张三 | 23 | 0 |
+----+------+-----+-----+
3 rows in set (0.02 sec)
1.3.2 JPA 注解
☞ 常用注解
| 注解 | 说明 | 属性 |
|---|---|---|
| @Entity | 指定当前类是实体类 | |
| @Table | 指定实体类和表之间的对应关系,不指定则默认表名为类名全小写 | name:指定数据库表的名称 |
| @Id | 指定当前字段是主键 | |
| @GeneratedValue | 指定主键的生成方式 | strategy :指定主键生成策略 |
| @Column | 指定实体类属性和数据库表之间的对应关系,不指定默认与成员变量名一致 | name:指定数据库表的列名称 unique:是否唯一 nullable:是否可以为空 inserttable:是否可以插入 updateable:是否可以更新 secondaryTable: 从表名 columnDefinition: 定义建表时创建此列的 DDL |
☞ 主键生成策略
通过注解来映射 hibernate 实体类,基于注解的 hibernate 主键标识为 @Id,其生成规则由 @GeneratedValue 设定的。这里的 @id 和 @GeneratedValue 都是 JPA 的标准用法。JPA 提供的四种标准用法:
♞ IDENTITY:主键由数据库自动生成(主要是自动增长型)
♞ SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列。
♞ AUTO:主键由程序控制
♞ TABLE:使用一个特定的数据库表格来保存主键