Pulsar Shed Unloading后producer无法连接到broker
文章目录
- Pulsar Shed Unloading后producer无法连接到broker
- 一、问题描述
- 二、先说原因&解决方案
- 1、在这之前
- 1.1NamespacesBundle和ownership
- 1.2 Shed Load Balance
- 1.3 Producer和Connection的关系 此处所说的connection是client和broker所建立的TCP连接。
- 2、原因
- 3、解决方案
- 4、重现步骤
- 三、排查过程
- 1、快速恢复应用才是最重要的
- 2、原因定位
- 2.1、本地模拟
- 2.2、ShedLoadBalance 由于上面确认是由于ShedLoadBalance功能导致的,那就先去看了这个功能是否有坑。
- 2.3、什么情况下会产生Producer is already present on
- 2.4、开启扫描模式
- 2.5 serverCnx处理Producer创建的逻辑
- 2.6 真正的原因浮出水面
- 四、带给我们的一些思考
- 1、为什么是使用了`RuntimeException`
- 2、代码健壮性是第一位,其他都排在后面
Pulsar Shed Unloading后producer无法连接到broker
一、问题描述
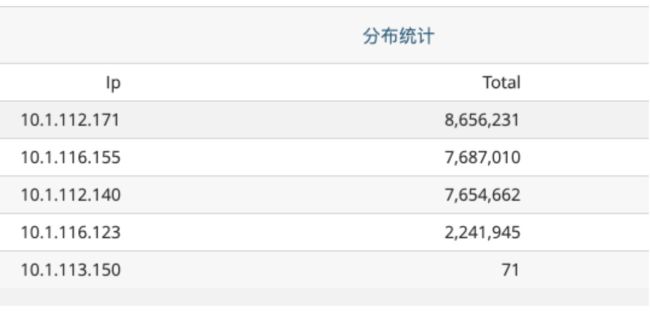
业务方反馈生产消息有大量失败,我登陆查看Cat上报信息发现该Topic有5个producers,其中4个producers都有大量的失败消息,并且分布比较均匀在每个时间段都有失败,而不是集中在某个时间点。有1个producer的消息生产正常。
下图为失败上报统计信息:
二、先说原因&解决方案
1、在这之前
说原因之前先普及几个概念,会让大家更易于理解这个问题的原因。如果已经了解这些概念所代表的机制可以直接略过。
1.1NamespacesBundle和ownership
在pulsar中一个topic(如果是分区topic此处就是指topic的一个分区)在同一时间只能被一个broker来服务,为该topic服务的broker就称之为ownership。但是决定topic的ownership所属确是在namespace级别,确切说是通过NamespaceBundles机制决定的。
NamespaceBundles和topic的关系其实就类似于一致性hash的实现,其中NamespaceBundles就是一个预先分段的hash环(默认是分成4段,每一段就是一个bundle),每一台broker会负责这个hash环的一部分,即负责一个NamespaceBundle,该NamespaceBundle上的Topic就归该broker负责。
在client连接到broker时会首选触发一个lookup的动作,其实就是确定该topic现在归那个broker负责,然后就和该broker建立连接。
broker负责的NamespaceBundle不是一成不变的,Pulsar提供了一个unload的管理API,可以把某个NamespaceBundle从该broker上卸载,卸载之后其他Broker就会触发一次tryAcquiringOwnership的动作,得到这个NamespaceBundle的就成为了新的Ownership。
另外Pulsar又提供了一个loadBalancerShedding的功能,如果启动用了该功能(loadBalancerSheddingEnabled=true,默认启用)后Broker Leader会根据运行时的负载情况动态进行NamespaceBundle的unload。
1.2 Shed Load Balance
从上文我们知道Broker Leader会根据所有brokers运行时的负载情况动态进行NamespaceBundles的unload,这个功能就称为Shed Load Balance。
目前在pulsar2.5.0版本中是收集CPU、堆内存、堆外内存和入站出战流量5个指标,默认情况下只要有其中1个指标的使用率超过指定阈值(默认为85,loadBalancerBrokerOverloadedThresholdPercentage配置)就会触发该动作。
简单流程就是:选出需要unload NamespaceBundles,然后调用unload的API接口。
具体逻辑此处不涉及,有兴趣同学可以阅读文档:pulsar.apache.org/docs/en/adm…
源码的话阅读org.apache.pulsar.broker.loadbalance.impl.OverloadShedder和org.apache.pulsar.broker.loadbalance.LoadSheddingTask
1.3 Producer和Connection的关系 此处所说的connection是client和broker所建立的TCP连接。
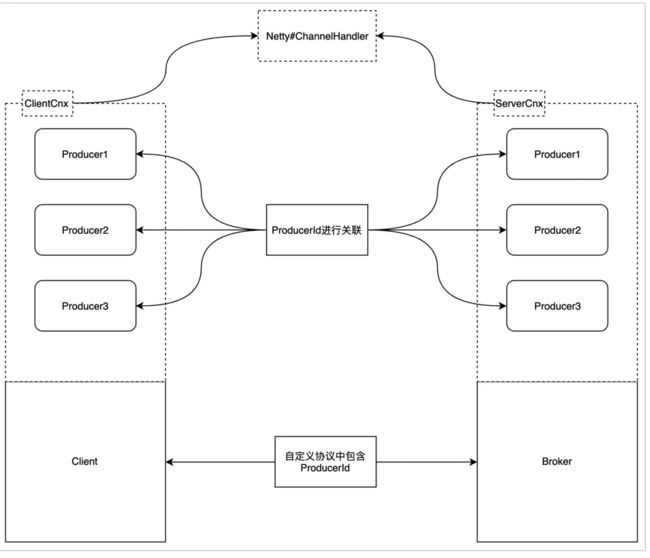
在Pulsar中producer创建的时候需要绑定一个topic,然后建立和broker的connection发送NewProducer的指令到broker。换句话说一个client有多少个topic需要发送消息就需要初始化多少个producer,但是connection可以是共享的,默认情况下所有的producer和consumer是共享在一个connection上的。
这就有个问题client发送NewProducer到broker时就需要对该producer有个唯一的标识符来防止重复创建和在后续client和server交互时判断cmd用于哪一个producer,这个标识符就是ProducerId(不能使用topic)。这个ProducerId需要在该connection上保持唯一,目前是在client端使用AtomicLong生成。
2、原因
NamespaceUnload发生时Client端重试创建Producer(发送NewProducer的Command),ServerCnx处理NewProducer命令时会先根据ProducerId判断是否已经有对应的ProducerFuture(使用了CompletableFuture),如果有的话就会阻断本次创建返回客户端Producer is already present on the connection的错误,但是在client端这个producer确实没有创建好的,必须一直重试NewProducer。我们碰到的问题就是这个,从broker的日志看有大量的Producer is already present on the connection。
log.warn("[{}][{}] Producer with id {} is already present on the connection", remoteAddress,
topicName, producerId);
ctx.writeAndFlush(Commands.newError(requestId, error,
"Producer is already present on the connection"));
后来排查发现是由于Server端在NewProducer的处理过程中为了防止同一个Topic被多个broker所owner,会进行checkTopicNsOwnership的判断,而在NamespaceUnload后这个这个方法就会校验失败抛出RuntimeException,但是在Server端确没有对这个异常进行处理,导致ServerCnx#handleProducer方法处理过程直接异常终止,ProducerFuture一直无法完成或者exception(这里还有个诡异的是这个RuntimeException竟然没有任何异常栈的信息输出,导致后面的排查几次都无法定位真正原因)。
然后如果再次触发了unloading或者手动unload后,这个namespacebundle的ownership又变回了上面的broker,进行NewProducer时由于有个dangling
producerFuture存在就导致producer一直无法创建成功,client就一直重试一直失败,一直失败一直重试,就不用谈发送消息了。
NewProducer的前置判断逻辑:
CompletableFuture<Producer> producerFuture = new CompletableFuture<>();
CompletableFuture<Producer> existingProducerFuture = producers.putIfAbsent(producerId,
producerFuture);
//有producerFuture了
if (existingProducerFuture != null) {
if (existingProducerFuture.isDone() && !existingProducerFuture.isCompletedExceptionally()) {
//producer已经创建完成了,直接返回success
//。。。省略
} else {
//已经有个producer在创建中
ServerError error = null;
if(!existingProducerFuture.isDone()) {
//上一个producer创建还是没完成
//有dangling producerfuture一直进到这里
error = ServerError.ServiceNotReady;
}else {
error = getErrorCode(existingProducerFuture);
// remove producer with producerId as it's already completed with exception
producers.remove(producerId);
}
//todo log错误
log.warn("[{}][{}] Producer with id {} is already present on the connection", remoteAddress,
topicName, producerId);
ctx.writeAndFlush(Commands.newError(requestId, error,
"Producer is already present on the connection"));
return null;
}
}
异常所在的代码:
try {
//这里的代码会抛出RuntimeException,导致producerFuture dangling
topic.addProducer(producer);
//....省略
} catch (BrokerServiceException ise) {
log.error("[{}] Failed to add producer to topic {}: {}", remoteAddress, topicName,
ise.getMessage());
ctx.writeAndFlush(Commands.newError(requestId,
BrokerServiceException.getClientErrorCode(ise), ise.getMessage()));
producerFuture.completeExceptionally(ise);
}
3、解决方案
知道了原因解决起来就很简单直接把catch (BrokerServiceException ise)修改为Exception或者增加RuntimeExceptioncatch处理也可以。
4、重现步骤
这个问题有点难重现,我在本地试了挺多次一直无法重现,简单说下重现步骤。
- broker触发unloading namespace bundle
- 在unloading namespace bundle执行disconnect producer后,但是还没执行到
removeTopic时(这一点很重要),有个重连producer的请求进到了这个broker。并且需要在a执行removeTopic之前进行getOrCreateTopic。 - unloading namespace bundle完成,ownership转到其他broker。b继续执行产生dangling producerfuture
- 其他broker发生unloading namespace bundle,这个namespaceBundle又回到了原来的broker,则异常出现。(需要保证connection是同一个,如果发生了reconnect,serverCnx也会重建)
三、排查过程
说透了原因就会发现这个问题很简单,但是由于log不全和本地一直无法复现的原因,在排查时候被带偏了几次导致走了弯路,到第2天才定位了真正原因。简单说下排查过程
1、快速恢复应用才是最重要的
接收到业务方反馈后,马上通过grafana和prometheus查看add_entry的成功率是100%,又查看了pulsar_msg_backlog在安全阈值之内的,并且这个topic配置backlog策略是consumer方失败而不是producer失败。
登陆Cat查看失败分布发现5个producers,有4个都在失败并且每个时间段都有很多,心里默默排除了是网络问题,不过为了确认还是询问业务方说3台机器都分布在亦庄,2台是在什么机房记不清楚了,基本把网络问题排除。(Pulsar集群部署在亦庄机房)
在Cat查看是否有异常信息,发现一切OK,和业务方确认了下说是未log出exception,只是做了event上报,好吧,下一步。
登陆Pulsar-manager后台查看该topic的情况时发现只有3个producer是连接状态,当时看Cat明明是有5个节点的,为了进一步确认于是登陆了服务器上通过pulsar-admin topics stats查看该topic的情况发现确实只有3台producers连接,那另外2台去那了呢?
迅速排查出了未连接的2台机器的IP,然后告知了业务方的同学,没办法这种关键时刻直接拿出了大杀器(重启业务应用,不是重启pulsar),业务方重启后通过监控发现2台producer已经连接上来了观察了下发布指标发现发布速率和延迟都是正常的。Cat上也不再有发布失败的event上报,那下一步就要确认是什么原因导致2台机器没连接上来。
我直接在线上grep了一下这两个机器的IP发现这两个节点一直在disconnect和connect,大约30-40分钟就会触发一次,然后还有Producer is already present on the connection的Warn日志。然后我又把其他3台机器的IP也grep了一下发现有同样的问题。看到了这么整齐的操作,我当时判断1、机房网络很不稳定
2、比较频繁的进行broker负载均衡,不过机房网络不稳定这个可能性马上被我否掉了(要是机房网络不稳定,群里岂不是早就炸锅了),那就只能是broker负载均衡问题引发的。
随后我就在log中寻找一些蛛丝马迹,发现确实有namespace bundle unloading之类的日志输出信息基本确认了这问题。心里虽然认定了是broker负载均衡引发的,不过为了进一步实锤这个,我就默默拿起了手机,这个时候只需要等待,如果是broker负载均衡的问题那等一会再次触发负载均衡时候肯定还会出现这个问题。
等了大约20分钟吧从日志中出现了namespace bundle unloading,然后topics stats发现ownership已经转变并且又有producer没连接上来,确实是这个问题引发的。在等待期间我又看了下jvm监控情况发现在过去的几个小时堆内存一直使用很高,平均在80%以上,这个应该是引发负载均衡的原因。
随后和大佬报备了一下之后,我就重启了Pulsar Broker,一是关闭了shedLoadBalance功能 二是加大了JVM的堆内存。
后续配置了producer数量降低的告警,持续观察了发送指标状态,这个问题算是恢复了。不过就辛苦业务方需要对过往数据进行fix了,大佬喝茶!
2、原因定位
2.1、本地模拟
在本地k8s集群中启动2个broker和5个producers+3分钟调用一次unlod的Job,一直无法复现问题,猜测可能是由于搭建在本地环境中延时极低,无法触发producer创建。
2.2、ShedLoadBalance 由于上面确认是由于ShedLoadBalance功能导致的,那就先去看了这个功能是否有坑。
看了一遍代码和测试用例发现功能很简单,就是计算出需要unload的namespaceBundles然后调用broker提供的unload API。
//获取broker:bundle
final Multimap<String, String> bundlesToUnload = strategy.findBundlesForUnloading(loadData, conf);
bundlesToUnload.asMap().forEach((broker, bundles) -> {
bundles.forEach(bundle -> {
//拆成2段
final String namespaceName = LoadManagerShared.getNamespaceNameFromBundleName(bundle);
final String bundleRange = LoadManagerShared.getBundleRangeFromBundleName(bundle);
//namespace亲和
if (!shouldAntiAffinityNamespaceUnload(namespaceName, bundleRange, broker)) {
return;
}
log.info("[Overload shedder] Unloading bundle: {} from broker {}", bundle, broker);
try {
//调用admin client unloadnamespace
pulsar.getAdminClient().namespaces().unloadNamespaceBundle(namespaceName, bundleRange);
loadData.getRecentlyUnloadedBundles().put(bundle, System.currentTimeMillis());
} catch (PulsarServerException | PulsarAdminException e) {
log.warn("Error when trying to perform load shedding on {} for broker {}", bundle, broker, e);
}
});
});
复杂的是unload,简单概括过程
- 清除NamespaceBundle Ownership本地cache
- 断开replicator、producer、consumer
- 关闭manageLedger和cache
- 更新zk
2.3、什么情况下会产生Producer is already present on
the connection 在log中发现无法连接的producers都是在一直输出Producer with id xxx is already present on the connection的错误,因此先从源码着手看看是什么情况下会产生此问题。
在ServerCnx#handleProducer中有以下代码:
CompletableFuture<Producer> producerFuture = new CompletableFuture<>();
CompletableFuture<Producer> existingProducerFuture = producers.putIfAbsent(producerId,
producerFuture);
if (existingProducerFuture != null) {
if (existingProducerFuture.isDone() && !existingProducerFuture.isCompletedExceptionally()) {
//producer已经创建完成了,直接返回success
Producer producer = existingProducerFuture.getNow(null);
log.info("[{}] Producer with the same id {} is already created: {}", remoteAddress,
producerId, producer);
//成功创建producer
ctx.writeAndFlush(Commands.newProducerSuccess(requestId, producer.getProducerName(),
producer.getSchemaVersion()));
return null;
} else {
//已经有个producer在创建中
ServerError error = null;
if(!existingProducerFuture.isDone()) {
//上一个producer创建还是没完成
error = ServerError.ServiceNotReady;
}else {
error = getErrorCode(existingProducerFuture);
// remove producer with producerId as it's already completed with exception
producers.remove(producerId);
}
log.warn("[{}][{}] Producer with id {} is already present on the connection", remoteAddress,
topicName, producerId);
ctx.writeAndFlush(Commands.newError(requestId, error,
"Producer is already present on the connection"));
return null;
}
}
从以上代码比较容易的就可以看出是由于在producers这个map中已经存在了一个producerFuture,并且这个producerFuture一直无法complete或者completeexception才出现这种情况。
那为什么这个producerFuture一直无法完成呢,我简单看了下后面的创建逻辑,没有发现问题,然后就去log中看看有没有什么蛛丝马迹方便定位问题。
2.4、开启扫描模式
因为多台机器都出现了无法连接的问题,并且无法连接的broker还不相同,因此把2台broker的机器都拿出来从每一个producer无法连接时的log寻找共同点。
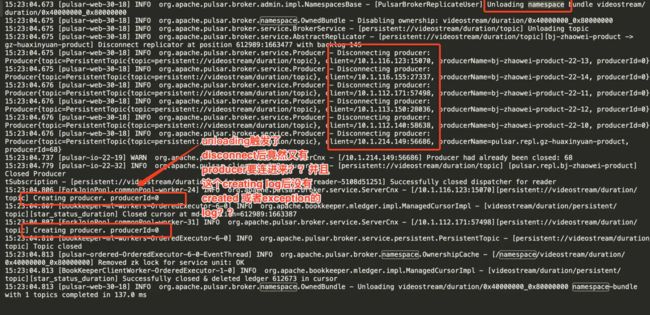
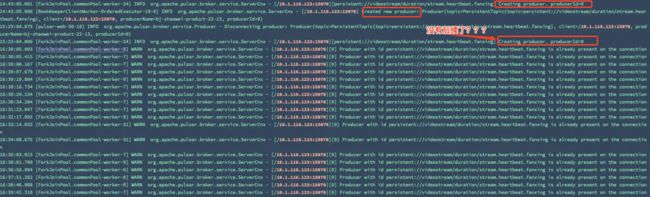
再把每一次shed unload和开始出现Producer is already present on the connection的log一一对比,被我发现了一个诡异的事情,
在unloading触发了producer disconnect后如果有producer要连接进来然后这个连接输出了creating producer了就没了后续,并且直接grep这个endpoint发现后续会一直Producer is already present on the connection。
下面是我截取了一部分的log:
发现了这个重连的问题之后我就被带偏了,我竟然去client端查为什么会在server端发送disconnect
命令后客户端会马上进行重连,查了下源码发现在断开后有个job会根据步长自动发起重连,我考虑这个应该是为了防止异常网络下断开的情况。
不过我确认了问题后马上暗骂自己傻了,即使是client发起了重连也是正常的呀,我应该去查server端为什么产生了dangling
ProducerFuture呀!!!
这里真的是以后注意,首先要定位自己产生的真正原因,即使真的是由于外部请求异常因素导致了问题产生,那也首先是自身系统不健壮才会出现问题!!!
2.5 serverCnx处理Producer创建的逻辑
排查 想清楚这个问题后我就根据creating producer的log定位代码,这个代码其实就是在put producerFuture后输出的。
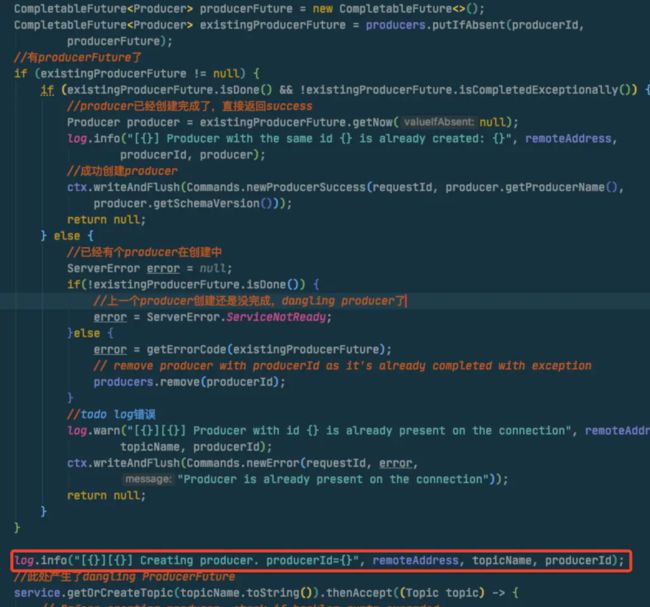
那就直接从这后面的代码排查即可,我首先看了service.getOrCreateTopic(topicName.toString())这个代码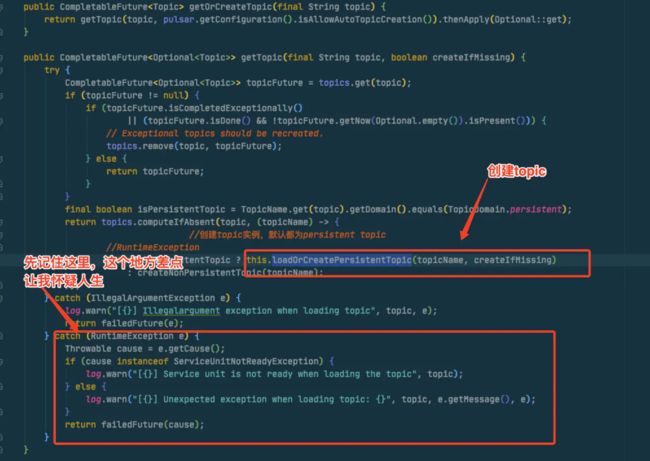
在上面的代码我进入了一个误区,因为上文在log中已经看到是disconnecting后才触发了连接,我就相当然的以为topics要进入重建,所以应该是进入了loadOrCreatePersistentTopic()方法。
我们继续看看下这个方法,首先进来就做了一个ownership的判断: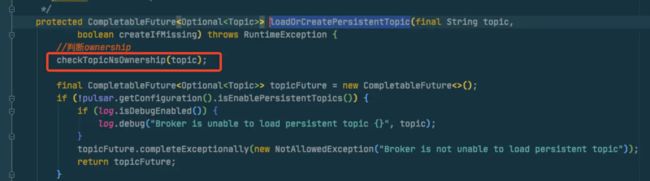
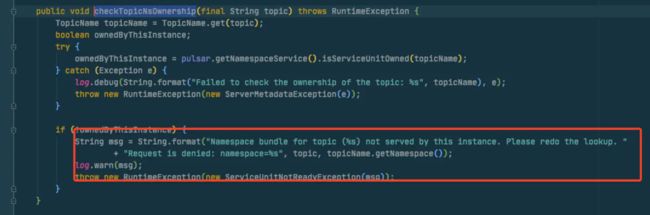 在上面的ownership方法中,我看到会输出一个
在上面的ownership方法中,我看到会输出一个log.warn(),就先去日志中找一下,发现确实有输出这个日志。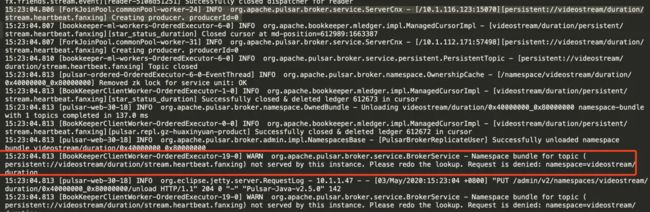
在log中发现了这个之后,然后再结合上面代码我们知道这个方法抛出了一个RuntimeException,然后在调用方其实有个trye catch runtimeexception的处理,看一下这个catch逻辑。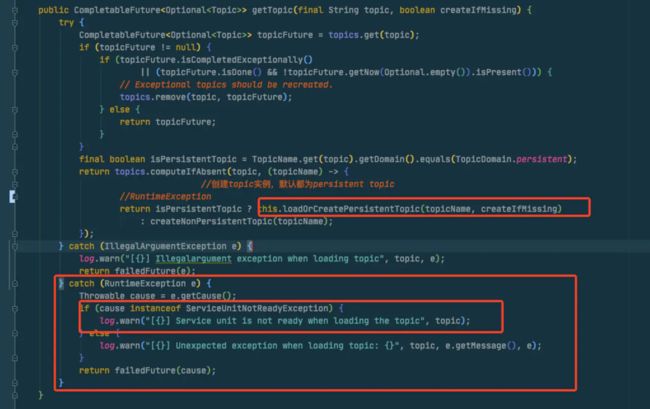
从上面代码中我们可以看到这里捕获了RuntimeException然后也进行了log.warn,我就再去日志中进行确认,然后就发现这个日志完全找不到!!!完全找不到!!!
在这里我坑了很久,因为已经有看到checkownship失败的log,那肯定是抛出了RuntimeException,在上面代码catch之后理论上应该有log呀??
花了很多时间一直都无法定位哪里出了问题,搞的我脑子一团浆糊,然后就去看了下不用带脑子的搞笑视频(big笑工坊,强势打广告)放松一下,忽然有一道灵光闪过,也许这里不会执行的,
因为执行到这里的时候unloading可能还没移除这个topic的缓存,也就不会去触发loadOrCreatePersistentTopic方法了(主要是我在前面日志中看到disconnect producer,就想当然的以为topic已经被卸载了,都是泪啊)!!!
先去unloading逻辑确认下什么时候移除topic缓存,进入PersistentTopic的close方法,从以下代码发现是要等该topic的producer、订阅和consumer、managedLedger都close后才会移除缓存!!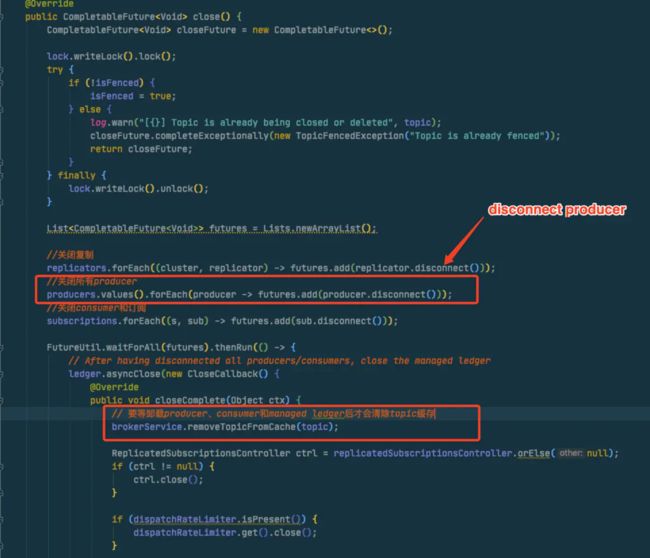
2.6 真正的原因浮出水面
从上面确认了topic缓存问题后,那就继续执行代码从下面逻辑寻找问题,后面逻辑很多,我直接删除了其他无用的,保留了核心代码。 核心问题就出在这里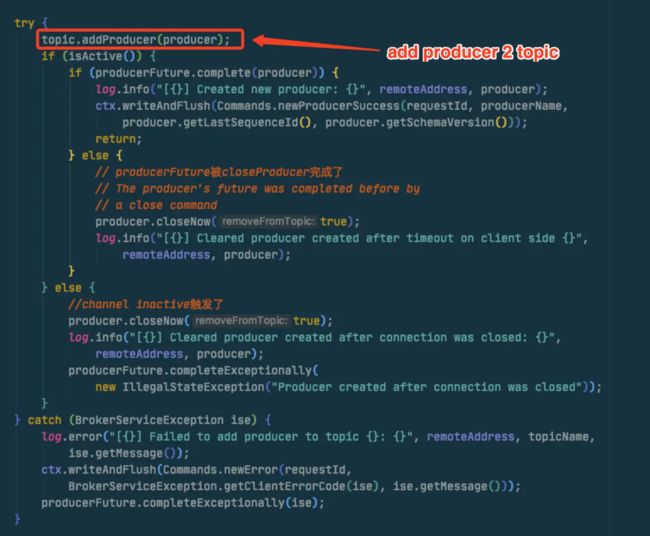
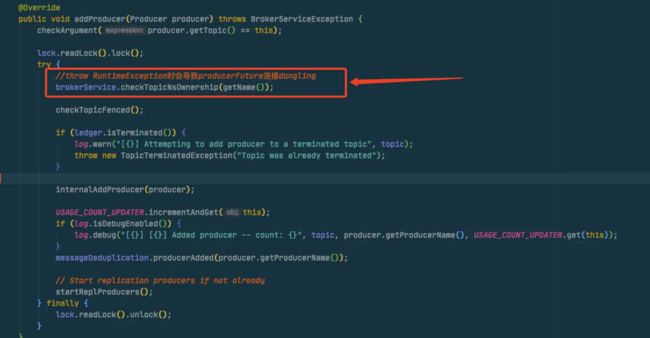 从上面的代码发现在调用
从上面的代码发现在调用topic.addProducer时在拿到了readlock后首先又进行了checkownership的判断,这个方法就是我们前面在2.5中提到的方法,上面说到它会抛出一个runtimeexception!!
而在上层调用方catch时确只处理了BrokerServiceException的异常,导致执行直接异常中断,然后产生了一个Dangling
ProducerFuture,后续如果使用这个connection进行相同producerId的创建时就会一直就报错了,除非重建这个连接或者重启应用!!
四、带给我们的一些思考
问题算是发现了,找到原因之后可以说是一个很简单的bug,fix起来也很容易,不过这个bug的产生确实带来的一些思考。
1、为什么是使用了RuntimeException
先看一下checkownership的方法签名,可以看到是throw了一个RuntimeException!!
这个写法其实我个人认为很坑(虽然我也这么干过),坑的不只是自己也是坑的后期维护的人,因为既然是在方法签名上显示进行了throw就说明这个异常需要外层进行处理,但是抛一个runtimeexception算什么吧!
那为什么不抛一个check exception呢??
我个人猜测其实是为了更好的使用JDK8引入了lambda表达式,如果用过lambda表达式的童鞋可能会有这方面的体会,尤其是在FuncationInterface中调用一些CheckedException的方法会很蛋疼,具体不做描述,有兴趣可以另行实验。
就是上面的代码了,如果loadOrCreatePersistentTopic是抛出一个CheckedException,那在这里写起来就有点蛋疼,需要在lambda里捕获然后再抛出去RuntimeException,然后外层再处理,就有点丑陋,例如这个样子: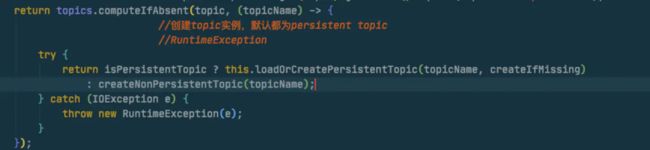
最重要的一点,上面都是我猜的,大家如果不认可的话就当笑料吧。
2、代码健壮性是第一位,其他都排在后面
转自: https://juejin.im/post/5eb50bece51d4542de28d27a