azkaban3.57web及executor插件安装
azkaban插件:
web端(hdfs,jobsummary,trigger)
executor端(Jobtype)
azkaban的编译及安装请参考另外两篇博文《azkaban3.57及3.0插件的编译》,《azkaban3.57多executor节点安装图文教程》
一、安装hdfs插件(在web端)
1、配置好cdh环境变量:
export HADOOP_HOME=/opt/cloudera/parcels/CDH
export HADOOP_CONF_DIR=/etc/hadoop/conf.cloudera.yarn
(老版本需要在/webServer_home/conf/azkaban.properties文件中新增一行,viewer.plugins=hdfs,指明hdfs插件路径,现在不需要)
在web_home 下面创建 plugins/viewer
把 azkaban-hdfs-viewer-3.0.0.tar.gz 复制到 viewer下并解压,把文件夹更名为hdfs
2、复制必要的hadoop依赖包到 web下面的extlib
(注:插件下的extlib不好使,建议以如下方式把相关依赖放入azkaban_web根目录下的extlib)
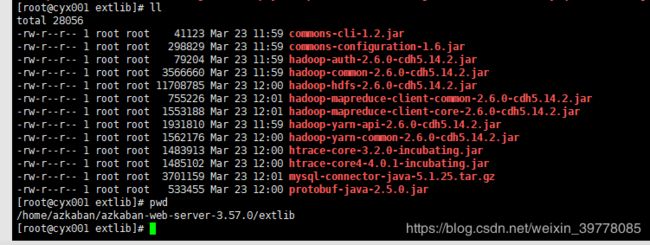
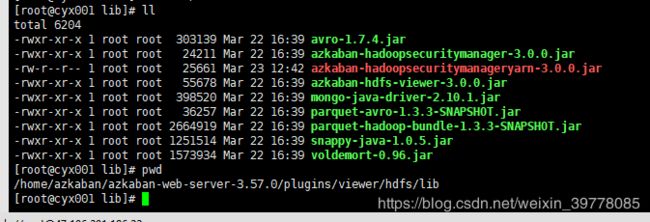
用到hadoop2.X的话,建议把yarn的安全验证也放到插件的lib下
3、修改 /home/azkaban/azkaban-web-server-3.57.0/plugins/viewer/hdfs/conf/plugin.properties 配置文件
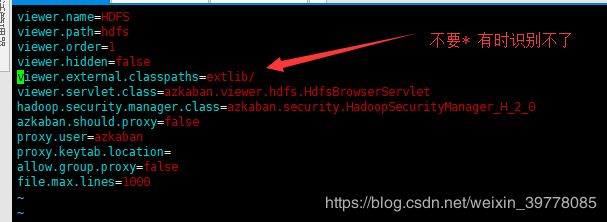
另外注意:插件会默认加载 triggers 没有的话不影响,如果创建了文件夹而没配的话,会报错,删掉文件夹即可!
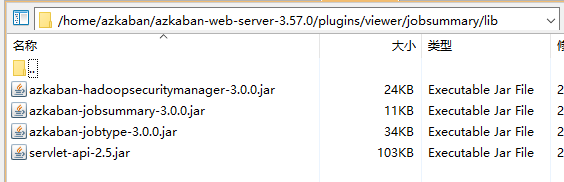
二、jobsummary插件安装
直接复制插件里的目录到viewer下,在lib下加入相应依赖包即可
三、trigger 插件安装
触发器插件安装,trigger编译缺失,需要重写编译脚本,参照plugins的目录及脚本配置
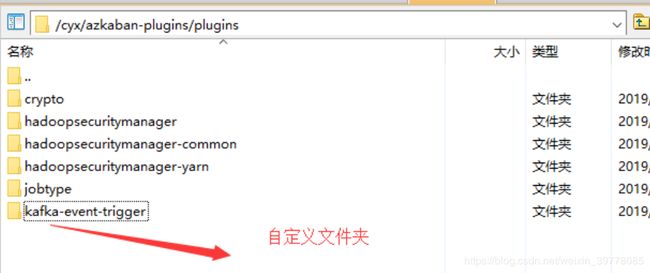
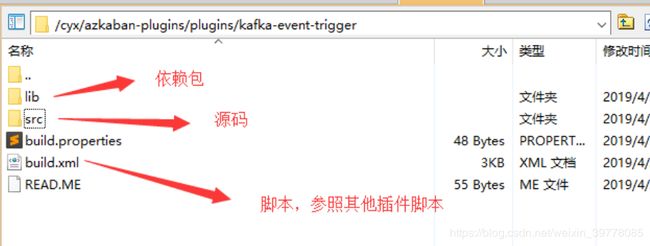
相关插件目录在 web-server 的 plugins下

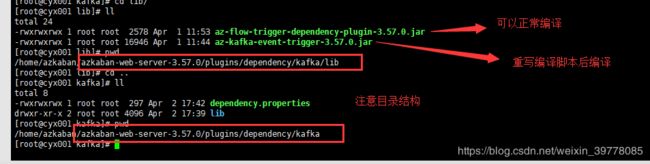

二、Jobtype插件安装(executor端)
复制编译后的插件目录到${azkaban-exec-home}/plugins/jobtypes
把spark缺失的jar包放进去,建立lib用于放置外部依赖(spark插件编译失败需要处理的)
修改
${azkaban-exec-home}/plugins/jobtypes/common.properties
该配置是executor执行任务的通用配置,一般任务调度时用到的外部配置也在此配置(比如外部数据库配置)

${azkaban-exec-home}/plugins/jobtypes/commonprivate.properties
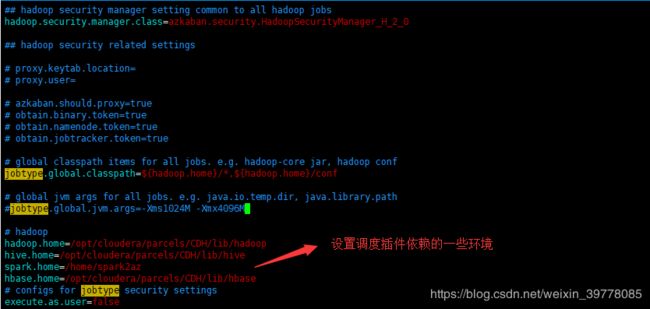
${azkaban-exec-home}/plugins/jobtypes/spark/private.properties

同时配置到其他executor节点,并且配置相应的环境变量。(如果部署节点不在大数据集群,建议把大数据集群相应的环境依赖复制过来,并配置成系统环境变量)