参考文档:https://www.cnblogs.com/huanongying/p/7021555.html
几个概念的梳理:
一、常见概念
mysql默认的事务隔离级别为repeatable-read
需要搞清楚的几个概念
- 1.我们所说的这个出现问题脏读、不可重复读、幻读是指某个Session连接中,在不同隔离级别下,一个事务中出现的问题
- 脏读:事务A读取了事务B还未commit的数据修改
- 脏写:事务A写覆盖了 事务B还未commit的数据修改
- 不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。(通常使用MVCC解决)
- Lost updates:2个事务 read-modify-write cycle,其中一个覆盖了另一个,另一个的数据丢失了
- 幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
- 不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表。
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
二、单机数据库是如何实现的
1、READ COMMITED
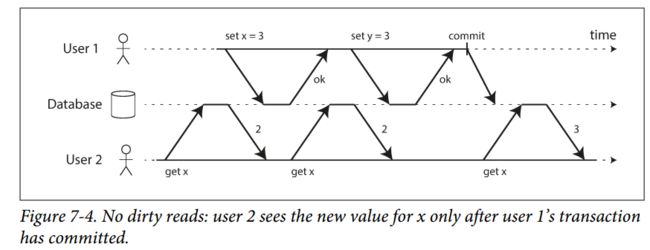
READ COMMITED保证了2点
- 你读到的是已提交的(no dirty reads)
- 你写覆盖的是已提交的(no dirty writes)
实现细节
no dirty writes
大部分数据库通过 row-lock,行锁,来保证,你的写,要么得不到锁等到,拿到锁写入的时候,肯定是已提交的
no dirty read
最简单,参考写锁,用同一个锁,即写和读都要去拿同一个行锁。但这会导致一个写比较慢时,大量的读堵塞的情况。严重影响性能
实际的实现:
当持有写锁时,数据库同时有一份老的数据和新的数据,如果未提交或回滚,则此时读就会给老的数据,如果提交了则使用新的数据。此时数据库维护2份数据
2.Snapshot Isolation and Repeatable Read
乍一看 read commited已经很完美,那么还会有其他问题吗?
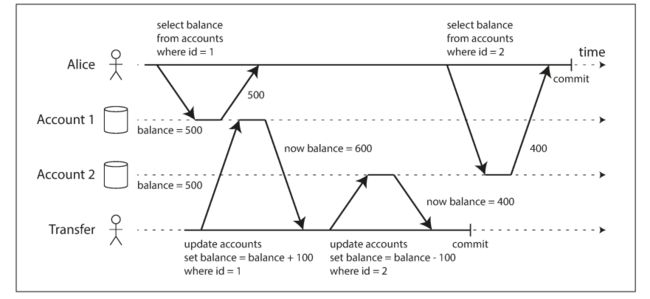
你在一个事务中读到一个变化的值, 这被称作 nonrepeatable read or read skew。说实话,这在大部分情况下,没有问题,你读到了一个最新的值。但在有些情况下,这会带来问题
- 备份:备份操作通常需要数分钟或者更久,如果在这段时间内,数据一直在变化,你备份的东西很可能是会冲突有问题的
- 数据分析和完整性检查:如你想scan一张表,用于数据分析,或者检查数据是有序的等。
解决方案--SNAPSHOT isolation
设计原则
读和写不会互相堵塞,这是为了避免慢查询或者慢写入造成的影响。
理论上,你可以通过快照的方式解决nonrepeatable的问题。每一个事务开始时,都保存一个快照版本,你的所有读操作,都在这个版本上。如何实现快照?----MVCC (multi-version concurrency control)
在read commited级别中,数据库只需要维护2个版本,commited和 overwritten-but-not-yet-commited。因为行锁只有一个,所以,每一行数据最多就2个版本。但在这里每个事务我们都需要维护一个版本,这就是所谓的MVCC
*如何实现MVCC?---通过 transaction id,即txid
难道我们真的要将所有数据每个事务,都全部保存一次吗?这显示是完成不了的。
先了解txid是什么?txid是数据库分配给每个事务的唯一id,可以体现出先后顺序

每一个写入操作,都会触发一个版本号的维护任务
每一行数据都有一系列版本维护信息
create_by field
delete_by field:一开始为空,当一个transaction删除这一行数据时,数据没有被真正的删除,只是在这个字段记录上txid信息,只有随着时间推移,当确认没有transcation会读取这个数据后,才会真正通过垃圾回收删除掉
update操作本质上是一个delete+create操作
- TXID如何实现MVCC?----通过一个数据可见的原则
1.当transaction开始时,数据库维护一个list,这个list包含所有 other transcation in progress(即还没提交或放弃的事务),在这个list中,所有已经修改的写入,就被 ignore,即对你不可见
2.所有被abort的事务修改不可见
3.比你的事务后面的事务,所有修改不可见,无论是否提交了
4.除了以上3点,其他都是可见的
这样的优点是什么呢?
原来我想象中的snapshot 直观印象上都是整个库的快照,但它的实现,其实非常精致巧妙,它只需要通过txid,将你的事务开始前的 transaction in progress 维护一个list,这个list数目实际上不会很大,在加上txid的有序递增,所有大于你的txid事务都不可见,就实现了快照的功能
3.可重复读的情况下,还有什么问题?
lost update
2个事务都read-modify-write cycle,假设都把一个值+1,最终可能只会+1,因为第二个操作,将第一个给覆盖了,好像之前的事务没有修改过一样?这就是无所谓的 lost update
- 如何解决lost update
这其实和java 的CAS目的是一样的,将这些操作转化为原子操作是最方便的
UPDATE counters SET value = value + 1 WHERE key = 'foo';
这个原子操作是通过一个特殊的锁实现的,使用这个特殊锁时,读的数据也是加锁的, 其他事务无法在获得锁事务结束前读取数据,这个方法被称为 cursor stability
此外还有一些探测lost update等操作,各个数据库采用不同的策略,有些库支持lost update,有些则不自动支持。
write skew
lost update其实是最简单的一种write skew类型,更广泛的类型是read出来的数据,用于判断,然后去操作另一份数据。
write skew的基础流程
1.query 满足条件的row
2.依赖query的结果,决定之后的操作
3.write(insert,update,delete)
先看例子

可以看出,这仍然是一个read-modify-write的操作,但和lost update相比的差别在哪?
lost update其实是write skew的一种特殊情况,特殊在那?即modify和update修改的是同一个值,而write skew修改的是不同的值,这更为难搞,因为他们修改的甚至都不是同一个值?
因此解决这个问题也更为苛刻
- 解决方案不同的点
1.原子解决方案不可用,因为multiple object 会被牵扯进去
2.一些数据库支持的探测lost update技术也没用,解决这个方案一般使用绝对的Serializable isolation
3.一些数据库有约束条件,如某个时刻必须有一个值,你这个约束条件由于包含multiple object,一般也不支持
4.主动加适当的锁,但这是一个很容易出错的的操作,一不小心就堵塞数据库了
BEGIN TRANSACTION;
SELECT * FROM doctors
WHERE on_call = true
AND shift_id = 1234 FOR UPDATE;
UPDATE doctors
SET on_call = false
WHERE name = 'Alice'
AND shift_id = 1234;
COMMIT;
As before, FOR UPDATE tells the database to lock all rows returned by this
query.
四、seriablizability
这里的串行化,只是一个概念,它保证的是所有的结果都会像串行执行出来一样
具体有以下3种方式
1.真正的串行,只用一个线程执行,完全不考虑并发,如redis。尽管这是一个最直观的想法,但知道2008年以后才开始真正使用,为什么以前没采用,因为RAM价格的降低,是的纯内存的存储开始流行起来,且OLAP和OLTP的细分,使得OLTP不怎么需要处理长查询等复杂操作。
-
2.封装成存储过程
如购买一张机票,可能包含了付费,出票等很多操作,将所有的操作封装位一个存储过程,这使得服务器的大量时间在等待用户的输入。
所以对于一个服务来说,会尽量减少交互设计,使得所有的信息尽量在一个http请求中完成
但也有很多情况下,是你的操作依赖于之前你的查询操作 ,这时候,就需要将原来的操作封装为存储过程
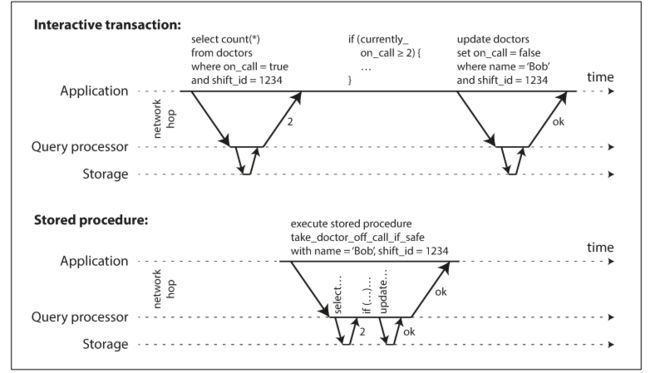 image.png
image.png
封装为存储过程后,使得复杂操作要么成功要么失败,体现的就像真正的串行一样。
存储过程有很多缺点如难以调试等,但现代的模型解决了很多问题,如redis使用lua脚本实现存储过程,这在内存型存储单线程中表现很好,因为不需要等待IO等操作,使得效率很高 3.分片
现代的多核cpu,如果一直是单线程模型,会很浪费。为了利用多核的特性,可以将数据进行分片,由每个核单独管理一定的事务范围。
这就像es的索引一样,将数据拆分后,或者数据库的表一样,如果拆分后,当你的事务在一定范围内时,可以使得多核充分利用。但当你的事务是覆盖全数据时,那么仍然解决问题
实际理论算法2pl--two-phase locking
过去30年,数据库实现serializability,只有1种算法,即为2pl,之前我们已经提到过,no dirty write的概念,通过加锁实现。后面我么又提过 snapshot 的实现原则,读和写不会互相阻塞
而2pl则是更为强力的方式,写不仅堵塞其他的写,还会阻塞其他的读和版本号修改
2pl的具体实现
以mysql的innodb以此方式实现:
1.每个object都有一个锁,这个锁有2种模式,共享状态和独占状态。
2.当一个事务read时,获得一个 共享锁,共享锁可以被多个read获得,但如果该锁为独占时,就必须等待
3.当一个事务要去写时,必须获得一个独占的锁,当有其他事务持有锁时,必须等待所有其他的持有释放共享或者独占的锁
4.当一个事务一开始读取object,然后改为写入,此时要将共享锁改为独占锁,操作等同于获得一个独占的锁
4.当事务获得锁时,会一直持有直到事务结束
- two-phase lock
第一个阶段为:锁何时获得
第二阶段为:锁何时释放
可以看到,所有的object都会有个锁,会有大量的锁同时存在,很容易产生死锁的情形,数据库会探测死锁的情况,然后放弃事务,由应用进行相应处理
可以看到,相比于之前,写锁是独占式的,他是会影响读取的!!!
2pl的问题也是显而易见的,写对读的影响,很容易导致,一个事务必须等待完另一个事务完成,再延迟性能上很难保证。
- predict lock
我们之前讲过幻读的例子,当查询,修改,写入发生时,快照的隔离无法解决,那么,使用2PL算法后,如何解读幻读的问题?
这时候我们使用predict lock,然后讲如何结合2pl实现这个概念
相比于之前的lock都是针对某个object,predict lock是对所有满足条件的object而言的
假设事务A第一步查询为:
SELECT * FROM bookings
WHERE room_id = 123 AND
end_time > '2018-01-01 12:00' AND
start_time < '2018-01-01 13:00';
这时候事务B如果持有独占锁的object也满足这些条件,那么A必须等待,直到B释放锁
当A想修改,删除,新增记录时,他必须去检查,修改前后的新值或者旧值,是满足已存在的predict lock的,如果有,那么也必须等待。
这里能看出predict lock的意义,它不仅仅会对已存在的object进行加锁,它还会对未来要修改或者新增的object进行加锁。
当2pl+predict lock时,就实现了Serializability效果
但predict lock的性能太差了,它需要对所有的条件进行匹配
因此大部分情况使用 index-range locking进行代替,也被称为next-key locking,这是predict lock的简化版
这里的关键概念是什么,减少匹配的难度,即加快匹配的速度
实际的实现:将精确的匹配条件转为更为简单的匹配,放宽匹配的要求
如1p.m-2p.m room123,扩大为所有的room和所有的时间
还是刚刚的例子,让你的room_id有索引的,可以直接将 这个index加锁,这样自然就锁住了room 123,同理时间范围也可以
所有的操作转化到了相应的index上。
index-range 的方式可能不如之前的那么精确,但能提高效率,此时要确保查询字段有index,不然可能会转为表锁
五、SSI Serializable Snapshot Isolation
SSI是2008年提出的一种新算法,在保证Serializable的同时,代价更小。目前已在一些单点数据库如PostgreSQL上使用。
悲观锁和乐观锁
之前我们所说的一切方法本质上都是悲观锁,悲观锁假设所有的环节都可能会出错,所以悲观的做了很多措施,本质上是使用了互斥的概念
而SSI使用了乐观锁,乐观锁是与其阻塞一些操作,避免问题,不如当问题出现了,也继续,它会自动恢复。
乐观锁和悲观锁的争论由来已久,通常我们认为,当出错问题概率大时,乐观锁效率反而不好SSI
顾名思义,它是在Snapshot Isolation的基础上,使用算法去探测事务冲突然后决定放弃什么事务的解决放哪wirte skew带来的问题,SSI如何解决?----重新检验读取的数据判断是否执行
write都是读-决定-写,3个步骤。当我们做决定时,我们会有一个前提,这个前提就是我们读的步骤的数据,当我们最后修改的时候,如果并发有冲突,那我们的前提就会破坏了,那么就放弃这个事务数据库如何知道前提(读的数据)被修改了
1.探测陈旧的MVCC Object Version(包括读之前未提交的)
2.探测写会影响之前读取的数据的(读之后提交的)-
实际解决方案
1.探测陈旧的MVCC Object Version
根据Snapshot Isolation,当transaction开始时,数据库维护一个list,这个list包含所有 other transcation in progress(即还没提交或放弃的事务),在这个list中,所有已经修改的写入,就被 ignore,即对你不可见。
但现在要保证Serializable,如果之前忽略的事务最终提交了,可能会产生影响。这时当前事务的前提就被破坏了
现在当数据库当探测到之前未提交被忽略的事务,如果有修改操作提交了。那么现在的事务如果有修改操作,则会被丢弃
2.当你read后,有其他事务进行了修改
和2pl一样,SSI当事务开始时,也对index进行锁定,不同的是,SSI并不会独占,即不会堵塞其他事务获得锁
当第一个事务提交时,它会通知其他的事务,他们读取的数据可能已经不是最新的了。
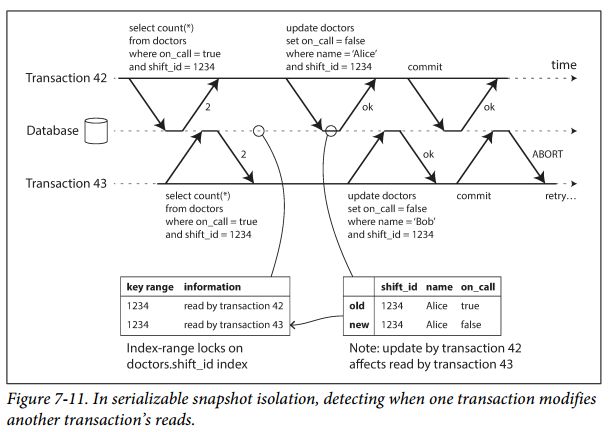 image.png
image.png SSI的性能
这个比较文献比较模糊,还是得根据实际业务情况来,不同冲突概率等肯定是不一样的